概要
この投稿では次のことを説明します。
- フレームワークのインストール
- 建築環境
- ライブラリのインポート
- 言語モデルの構築
- LangChain 式言語の使用
- Agent Executor の構成
- エージェントの実行
- セルフアスクエージェントの使用
検索チェーンを使用したセルフアスクを実装するにはどうすればよいですか?
Self-Ask は、コマンドを徹底的に理解し、連鎖プロセスを改善するプロセスです。チェーンは、データセットからすべての重要な用語に関するデータを抽出することで質問を理解します。モデルがトレーニングされてクエリを理解すると、ユーザーが尋ねたクエリに対する応答が生成されます。
LangChain の検索チェーンを使用してセルフアスクを実装するプロセスを学ぶには、次のガイドを参照してください。
ステップ 1: フレームワークのインストール
まず、次のコードを使用して LangChain プロセスをインストールしてプロセスを開始し、プロセスのすべての依存関係を取得します。
pip インストール ラングチェーン
LangChainをインストールしたら、「 グーグル検索結果 」を使用して、OpenAI 環境を使用して Google から検索結果を取得します。
pip インストール openai google-search-results 
ステップ 2: 環境の構築
モジュールとフレームワークがインストールされたら、環境をセットアップします。 OpenAI そして セルパピ 次のコードを使用して API を使用します。それぞれのアカウントから API キーを入力するために使用できる os ライブラリと getpass ライブラリをインポートします。
輸入 あなた輸入 ゲットパス
あなた 。 約 [ 「OPENAI_API_KEY」 】 = ゲットパス 。 ゲットパス ( 「OpenAI API キー:」 )
あなた 。 約 [ 「SERPAPI_API_KEY」 】 = ゲットパス 。 ゲットパス ( 「Serpapi API キー:」 )
ステップ 3: ライブラリのインポート
環境をセットアップしたら、ユーティリティ、エージェント、llm などの必要なライブラリを LangChain の依存関係からインポートするだけです。
から ラングチェーン。 llms 輸入 OpenAIから ラングチェーン。 公共事業 輸入 SerpAPIラッパー
から ラングチェーン。 エージェント 。 出力パーサー 輸入 SelfAskOutputParser
から ラングチェーン。 エージェント 。 フォーマット_スクラッチパッド 輸入 format_log_to_str
から ラングチェーン 輸入 ハブ
から ラングチェーン。 エージェント 輸入 エージェントの初期化 、 道具
から ラングチェーン。 エージェント 輸入 エージェントタイプ
ステップ 4: 言語モデルの構築
言語モデルの構成には OpenAI() が使用されるため、プロセス全体を通じて上記のライブラリを取得する必要があります。 SerpAPIWrapper() メソッドを使用して検索変数を構成し、エージェントがすべてのタスクを実行するために必要なツールを設定します。
llm = OpenAI ( 温度 = 0 )検索 = SerpAPIラッパー ( )
ツール = [
道具 (
名前 = 「中間の答え」 、
機能 = 検索。 走る 、
説明 = 「検索で聞きたいときに便利」 、
)
】
ステップ 5: LangChain 式言語の使用
プロンプト変数にモデルをロードして、LangChain Expression Language (LCEL) を使用してエージェントの構成を開始します。
プロンプト = ハブ。 引く ( 「hwchase17/self-ask-with-search」 )テキストの生成を停止し、返信の長さを制御するために実行できる別の変数を定義します。
llm_with_stop = そうですね。 練る ( 停止 = [ 」 \n 中間の答え:」 】 )次に、イベント駆動型のサーバーレス プラットフォームである Lambda を使用してエージェントを設定し、質問に対する応答を生成します。また、前に構成したコンポーネントを使用して、モデルのトレーニングとテストに必要な手順を構成し、最適化された結果を取得します。
エージェント = {'入力' : ラムダ ×:× [ '入力' 】 、
「エージェント_スクラッチパッド」 : ラムダ x: format_log_to_str (
バツ [ '中間ステップ' 】 、
観測_プレフィックス = 」 \n 中間の答え: ' 、
llm_prefix = 「」 、
) 、
} |プロンプト | llm_with_stop | SelfAskOutputParser ( )
ステップ 6: Agent Executor の構成
メソッドをテストする前に、LangChain から AgentExecutor ライブラリをインポートして、エージェントが応答できるようにします。
から ラングチェーン。 エージェント 輸入 エージェントエグゼキュータAgentExecutor() メソッドを呼び出し、コンポーネントを引数として使用して、agent_executor 変数を定義します。
エージェント_エグゼキューター = エージェントエグゼキュータ ( エージェント = エージェント 、 ツール = ツール 、 冗長な = 真実 )ステップ 7: エージェントの実行
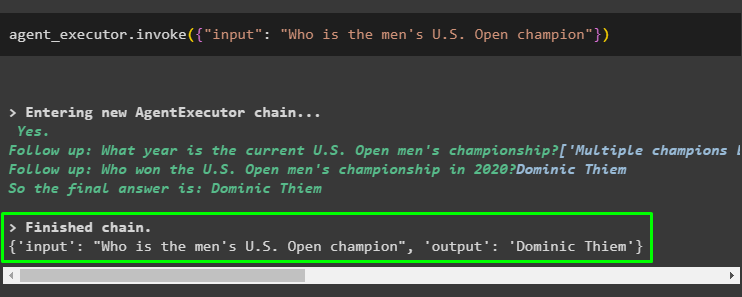
Agent Executor を構成したら、入力変数に質問/プロンプトを指定してテストします。
エージェント_エグゼキュータ。 呼び出す ( { '入力' : 「全米オープン男子チャンピオンは誰だ?」 } )上記のコードを実行すると、出力に全米オープンチャンピオンの名前、つまり Dominic Thiem が返されます。
ステップ 8: Self-Ask エージェントの使用
エージェントから応答を取得した後、 SELF_ASK_WITH_SEARCH run() メソッドでクエリを使用したエージェント:
self_ask_with_search = エージェントの初期化 (ツール 、 llm 、 エージェント = エージェントタイプ。 SELF_ASK_WITH_SEARCH 、 冗長な = 真実
)
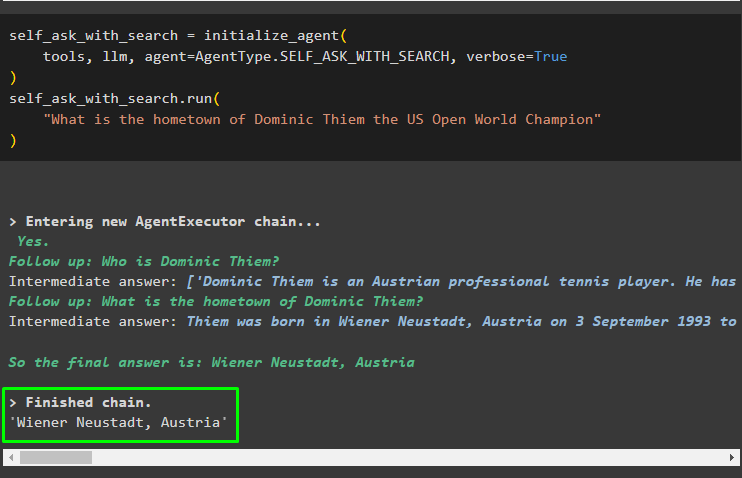
self_ask_with_search。 走る (
「全米オープンワールドチャンピオン、ドミニク・ティエムの故郷はどこですか?」
)
次のスクリーンショットは、自己質問エージェントがデータセットから各重要な用語に関する情報を抽出することを示しています。クエリに関するすべての情報を収集し、質問を理解したら、単純に回答を生成します。エージェントが自ら尋ねる質問は次のとおりです。
- ドミニク・ティエムとは誰ですか?
- ドミニク・ティエムの出身地はどこですか?
これらの質問に対する回答を取得した後、エージェントは元の質問に対する回答を生成しました。 ウィーン・ノイシュタット、オーストリア ”:
LangChain フレームワークを使用して検索チェーンでセルフアスクを実装するプロセスについては以上です。
結論
LangChain で検索によるセルフアスクを実装するには、エージェントから結果を取得するために google-search-results などの必要なモジュールをインストールするだけです。その後、OpenAI アカウントと SerpAPI アカウントの API キーを使用して環境をセットアップし、プロセスを開始します。エージェントを構成し、自己質問モデルを使用してモデルを構築し、AgentExecutor() メソッドを使用してテストします。