構文
df [ ( cond_1 ) & ( cond_2 ) ]例 01
これらのコードは「Spyder」アプリで実行し、「パンダ」の条件で「AND」演算子を使用します。パンダコードを実行しているので、最初に「pandas as pd」をインポートする必要があり、コードに「pd」を入れるだけでそのメソッドを取得します。次に、「Cond」という名前の辞書を生成します。ここに挿入するデータは「A1」、「A2」、「A3」は列名で、「1、2、3」を「 A1」、「A2」には「2、6、および 4」があり、最後の「A3」には「3、4、および 5」が含まれています。
ここで「pd.DataFrame」を利用して、このディクショナリの DataFrame を作成していきます。これにより、上記の辞書データの DataFrame が返されます。また、ここで「print ()」を指定してレンダリングし、その後、いくつかの条件を適用し、この条件で「&」演算子も使用します。ここでの最初の条件は「A1 >= 1」で、次に「&」演算子を入れて「A2 < 5」という別の条件を配置します。これを実行すると、「A1 >=1」かつ「A2 < 5」の場合に結果が返されます。ここで両方の条件が満たされた場合、結果が表示されます。ここでいずれかの条件が満たされない場合、データは表示されません。
DataFrame の「A1」列と「A2」列の両方をチェックし、結果を返します。 「print()」ステートメントを使用しているため、結果が画面に表示されます。
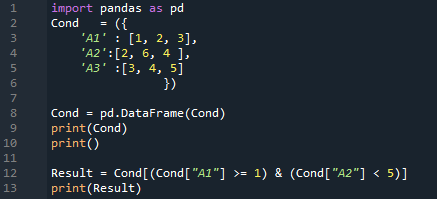
結果はこちら。 DataFrame に挿入したすべてのデータを表示し、両方の条件をチェックします。 「A1 >=1」および「A2 < 5」の行を返します。両方の条件が 2 つの行で満たされているため、この出力では 2 つの行が得られます。
例 02
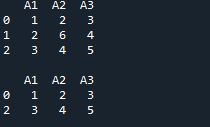
この例では、「pandas as pd」をインポートした後、DataFrame を直接作成します。ここで「チーム」データフレームが作成され、データには 4 つの列が含まれます。最初の列は「チーム」列で、「A、A、B、B、B、B、C、C」を入力します。次に、「チーム」の次の列は「スコア」で、「25、12、15、14、19、23、25、および 29」を挿入します。この後、列は「Out」になり、データも「5、7、7、9、12、9、9、および 4」として追加されます。ここでの最後の列は「リバウンド」列で、「11、8、10、6、6、5、9、および 12」という数値データも含まれています。
ここで DataFrame が完成し、今度はこの DataFrame を印刷する必要があるため、ここに「print()」を配置します。この DataFrame から特定のデータを取得したいので、ここでいくつかの条件を設定します。ここには 2 つの条件があり、これらの条件の間に「AND」演算子を追加すると、両方の条件を満たす条件のみが返されます。ここで追加した最初の条件は「score > 20」で、次に「&」演算子と「Out == 9」という他の条件を配置します。
そのため、チームのスコアが 20 未満でアウトが 9 であるデータをフィルタリングします。それらをフィルタリングし、両方の条件またはいずれかの条件を満たさない残りを無視します。両方の条件を満たすデータも表示するため、「print()」メソッドを利用しています。
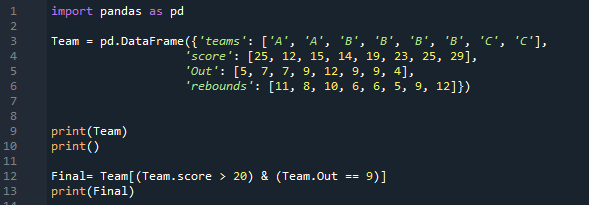
この DataFrame に適用した両方の条件を満たす行は 2 行だけです。スコアが 20 よりも大きく、アウトが 9 である行のみをフィルタリングして、ここに表示します。
例 03
上記のコードでは、数値データを DataFrame に挿入するだけです。ここで、このコードにいくつかの文字列データを入れています。 「pandas as pd」をインポートした後、「Member」DataFrame の構築に移ります。 4 つの固有の列が含まれています。ここの最初の列の名前は「名前」で、メンバーの名前を挿入します。「同盟国、ビルズ、チャールズ、デビッド、エセン、ジョージ、ヘンリー」です。次の列は「場所」と名付けられており、「アメリカ.カナダ、ヨーロッパ、カナダ、ドイツ、ドバイ、およびカナダ」が含まれています。 「コード」列には、「W、W、W、E、E、E、および E」が含まれます。また、ここでメンバーの「ポイント」を「11、6、10、8、6、5、12」として追加します。 「print()」メソッドを利用して、「Member」DataFrame をレンダリングします。この DataFrame でいくつかの条件を指定しました。
ここでは、2 つの条件があり、それらの間に「AND」演算子を追加することで、両方の条件を満たす条件のみを返します。ここで導入した最初の条件は「場所 == カナダ」で、その後に「&」演算子が続き、2 番目の条件は「ポイント <= 9」です。両方の条件を満たすDataFrameからデータを取得し、両方の条件を満たすデータを表示する「print()」を配置しています。
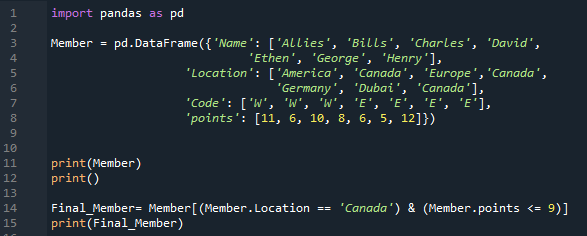
以下では、DataFrame から 2 つの行が抽出されて表示されていることがわかります。どちらの行も場所は「カナダ」で、ポイントは 9 未満です。
例 04
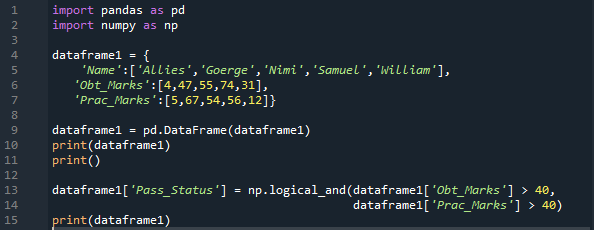
ここでは、「pandas」と「numpy」の両方をそれぞれ「pd」と「np」としてインポートします。 「pd」を配置することで「pandas」メソッドを取得し、必要に応じて「np」を配置することで「numpy」メソッドを取得します。次に、ここで作成したディクショナリには 3 つの列が含まれています。 「名前」欄には、「同盟国、ジョージ、ニミ、サミュエル、ウィリアム」を挿入します。次に、「Obt_Marks」列があり、学生の取得したマークが含まれており、それらのマークは「4、47、55、74、および 31」です。
また、学生の実践的な点数を持つ「Prac_Marks」の列もここに作成します。ここで追加するマークは「5、67、54、56、および 12」です。この Dictionary の DataFrame を作成し、それを出力します。ここで「np.Logical_and」を適用すると、結果が「True」または「False」の形式で返されます。また、両方の条件をチェックした後の結果を、ここで作成した「Pass_Status」という名前の新しい列に保存します。
「Obt_Marks」が「40」よりも大きく、「Prac_Marks」が「40」よりも大きいことを確認します。両方が true の場合、新しい列で true になります。それ以外の場合は false になります。
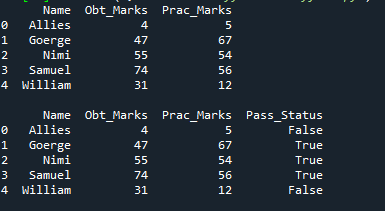
「Pass_Status」という名前の新しい列が追加され、この列は「True」と「False」のみで構成されます。得られた点数と実技の点数が 40 を超える場合は true になり、残りの行は false になります。
結論
このチュートリアルの主な目的は、「pandas」の「and 条件」の概念を説明することです。両方の条件が満たされる行を取得する方法について説明しましたが、すべての条件が満たされている場合は true になり、残りの場合は false になります。ここでは、4 つの例を検討しました。このチュートリアルで確立した 4 つの例はすべて、このプロセスを経ています。このチュートリアルの例はすべて、ユーザーの利益のために慎重に提示されています。このチュートリアルは、このアイデアをより明確に理解するのに役立つはずです.