スケーラビリティ
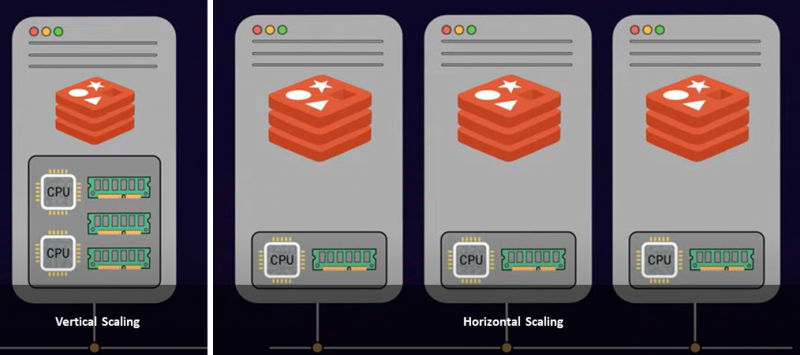
サーバーのスケーリングには、垂直スケーリングと水平スケーリングの 2 つの一般的なアプローチがあります。垂直方向のスケーリングまたはスケールアップは、コストがかかる CPU、メモリ、ストレージなど、より多くの電力とリソースをサーバーに追加する場所です。一方、水平スケーリングでは、複数のノードを既存のリソース プールに追加します。これをスケールアウトと呼びます。そのため、制限と要件に基づいて、単一のより大きなサーバー インスタンスを用意するか、複数のサーバー ノードをデプロイするかはユーザー次第です。
100 GB の RAM があり、200 GB のデータを保持する必要があるとします。この場合、次の 2 つの選択肢があります。
- システムに RAM を追加してスケールアップする
- 100 GB の RAM を備えた別のサーバー インスタンスを追加してスケールアウトする
インフラストラクチャ内の最大 RAM 制限に達した場合は、スケールアウトが理想的なアプローチです。さらに、スケールアウトすると、データベースのスループットが大幅に向上します。
Redis シャーディング
Redis が単一のスレッドで動作することは既知の事実です。そのため、Redis はサーバーの CPU の複数のコアを利用してコマンドを処理することができません。したがって、CPU コアを追加しても、Redis のスループットやパフォーマンスはあまり向上しません。複数のサーバー インスタンス間でデータを分割する場合には当てはまりません。複数のサーバーを追加し、それらの間でデータ セットを分散すると、クライアント要求の並列処理が可能になり、スループットが向上します。さらに、全体的なパフォーマンスはほぼ直線的に増加する可能性があります。
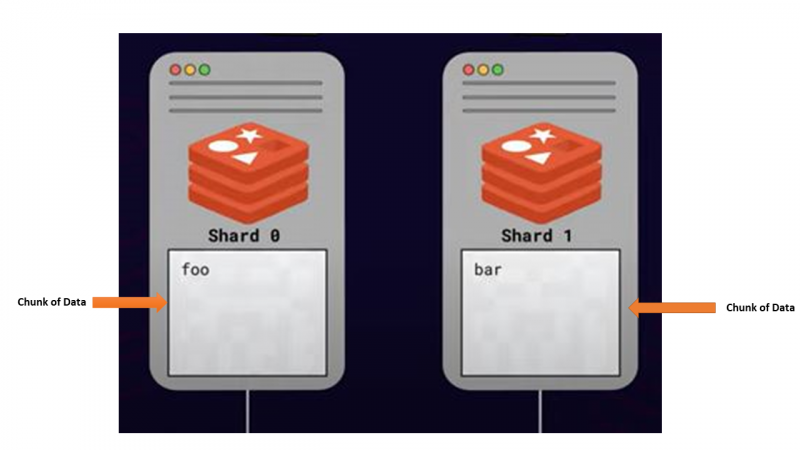
スケーリングを念頭に置いて複数のサーバー間でデータを分割または分散するこのアプローチは、 シャーディング .データの一部を保存するすべてのサーバーが呼び出されます 破片 .
シャーディングの仕組み — アルゴリズム シャーディング
シャーディングに関する主な懸念事項の 1 つは、複数の Redis ノード間で特定のキーを見つける方法でした。特定のキーは使用可能な任意のシャードに格納できるため、特定のキーを見つけるためにすべてのシャードをクエリすることは最適なオプションではありません。そのため、各キーを特定のシャードにマップする方法が必要であり、Redis はアルゴリズム シャーディング戦略を使用します。
最も一般的なアプローチは、Redis キー名とモジュロを使用してハッシュ値を計算することです。次に、システムで使用可能な Redis シャードで割ります。
HASH_SLOT = CRC16(キー) mod 16384シャードの総数が一定である限り、これは非常に優れたソリューションです。新しい Reids サーバー インスタンスを追加するたびに、シャードの総数が増えるため、特定のキーの結果の値が変わる可能性があります。間違った Redis シャードにクエリを実行することになります。したがって、各キーの新しいシャードを計算し、正しいサーバーにデータを転送することにより、リシャーディング プロセスに従う必要があります。これは面倒であり、シャードの合計数が時々増加している場合は簡単な作業ではありません。
Redis は、と呼ばれる新しい論理エンティティを使用します。 ハッシュスロット この問題を防ぐために。特定のシャードで複数のハッシュ スロットを使用でき、1 つのハッシュ スロットで複数の Redis キーを保持できます。変更されていない Redis データベース クラスターには 16384 個のハッシュ スロットがあります。モジュロ除算は、シャード数ではなくハッシュ スロット数で行われます。シャードの数が増えた場合でも、指定されたキーのハッシュ スロットの正しい位置を提供します。ハッシュ スロットを 1 つのシャードから新しいシャードに移動し、要件に従って異なる Redis インスタンス間でデータを分割することにより、リシャーディング プロセスを簡素化します。
Redis シャーディングの利点
Redis シャーディングは、最小限の変更でデータベース システムにいくつかの利点をもたらします。
ハイスループット
Redis はシングルスレッドであるため、複数のクライアント リクエストを処理する場合、複数の CPU コアを使用して並列処理することはできません。そのため、新しいシャードまたはサーバー インスタンスを追加すると、Redis 操作を並行して実行できることが保証されます。 Redis データベースでの 1 秒あたりの操作が増加し、最終的に高いスループットが得られます。
高可用性
シャーディング アプローチにより、Redis クラスターは、高可用性と耐久性を保証するマスター/レプリカ アーキテクチャをセットアップできます。
リードレプリカ
シャーディングを使用すると、データの正確なコピーを保持し、個別の Redis インスタンスを介して読み取り操作を提供できるため、読み取りクエリの実行のパフォーマンスが向上します。
これらの利点とは別に、Redis クラスターに偶数のシャードがある場合、シャーディングはスプリット ブレインの状況を引き起こす可能性があります。そのため、Redis クラスターに奇数のシャードを保持することをお勧めします。
結論
要約すると、Redis シャーディングは複数のサーバー間でデータを分割することで、データベースのスケーリングと高スループットを可能にします。説明したように、Redis はアルゴリズムのシャーディング戦略を使用して、クライアントの要求を正しいシャードに向けます。これには、シャードの総数が増えるといくつかの欠点があります。そのため、シャードの総数ではなく、Redis はハッシュ スロットの数を使用して適切なシャードを計算します。シャーディングが導入された Redis データベースは、高可用性、高スループット、および高性能を提供します。