- Series.to_numpy()
- Series.index.to_numpy()
- np.array(シリーズ.配列)
- np.array(シリーズ.インデックス.配列)
- np.array(Series.index.values)
このガイドでは、これらの各方法の実際の実装について説明します。
例 1: Series.To_Numpy() メソッドの利用
Pandas シリーズを NumPy 配列に変換するためにこのガイドで使用する最初の方法は、「Series.to_numpy()」関数です。このメソッドは、提供されたシリーズの値を NumPy 配列に変換します。 Python プログラムを実際に実行して、その機能を調べてみましょう。
このチュートリアルで生成されるサンプル コードのコンパイルには、「Spyder」ツールを選択します。ツールを起動し、スクリプトを開始します。このプログラムを実行するための基本的な要件は、必要なパッケージをロードすることです。ここでは、「Pandas」ツールキットに属するいくつかのモジュールを使用します。そのため、Pandas ライブラリをプログラムにインポートし、そのエイリアスを「pd」として作成します。この「Pandas」の「pd」の省略形は、スクリプト内で Pandas のメソッドにアクセスする必要がある場合に使用されます。
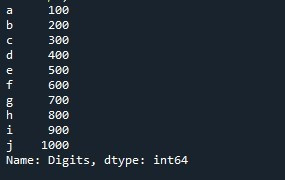
ライブラリをインポートした後、このライブラリから「pd.Series()」というメソッドを呼び出すだけです。ここで、前述の「pd」は Pandas のエイリアスであり、Pandas のメソッドにアクセスすることをプログラムに伝えるために使用されます。一方、「シリーズ」は、番組でシリーズ作成プロセスを開始するキーワードです。 「pd.Series()」関数が呼び出され、値のリストを指定します。提供する値は、「100」、「200」、「300」、「400」、「500」、「600」、「700」、「800」、「900」、「1000」です。 「name」パラメーターを使用して、このリストのラベルを「数字」として分類します。 「index」属性は、デフォルトのシーケンシャル インデックス リストの代わりに挿入するインデックス リストを指定するために使用されます。 「a」、「b」、「c」、「d」、「e」、「f」、「g」、「h」、「i」、「j」の値を格納します。シリーズを格納するために、シリーズ オブジェクト「Counter」を作成します。次に、「print()」関数は、出力を端末に出力することで、出力を確認するのに役立ちます。
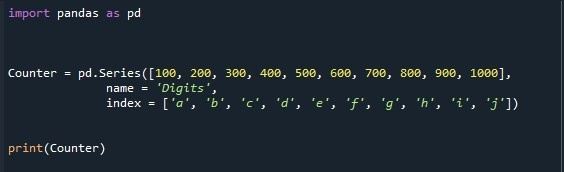
定義されたインデックス リストを使用して新しく生成されたシリーズが、出力ウィンドウに表示されます。
このシリーズを NumPy 配列に変更するには、「Series.to_numpy()」メソッドを使用します。シリーズ「カウンター」の名前は、「.to_numpy()」関数で言及されます。したがって、この関数はシリーズ「Counter」の値を取得し、それらを NumPy 配列に変換します。この関数から生成された結果の NumPy 配列を保持するために、「output_array」変数が生成されます。その後、「print()」メソッドを用いて表示します。

レンダリングされたイメージは配列を示しています。

「type()」関数を使用してその型を確認しましょう。変数の名前を入力し、「type()」関数の括弧の間に NumPy 配列を格納します。次に、この関数を「print()」メソッドに渡して、型を表示します。

ここでは、出力 NumPy 配列が検証されます。次の図はクラスを「numpy.ndarray」として示しています。

例 2: Series.Index.To_Numpy() メソッドの利用
シリーズの値を NumPy 配列に変換する以外に、インデックスを NumPy 配列に変換することもできます。このインスタンスは、「Series.index.to_numpy()」メソッドを使用して、シリーズのインデックスから NumPy 配列への変換を学習するのに役立ちます。
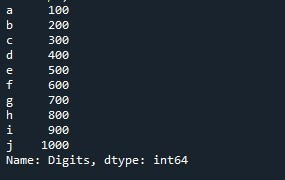
このデモでは、前の図で作成したシリーズを使用します。
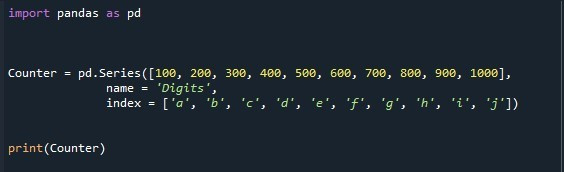
このコードを切り取って生成された出力を次の図に示します。
ここで、シリーズのインデックス リストを NumPy 配列に変換するために、「Series.index.to_numpy()」メソッドを利用します。
「Series.index.to_numpy()」関数が呼び出されます。シリーズの名前は、「.index.to_numpy()」メソッドで「Counter」として提供されます。このメソッドは、「Counter」シリーズからインデックスを取得し、NumPy 配列に変換します。ここで、変換された NumPy 配列を格納するために、「ストレージ」変数を初期化し、それを NumPy 配列に割り当てます。最後に、達成された結果を確認するために、「print()」関数を呼び出します。

シリーズのインデックス リストが NumPy 配列に変換され、Python コンソールに表示されるようになりました。

配列タイプの検証のために、「type()」メソッドを実行し、「storage」変数をそれに渡します。カテゴリの閲覧には「印刷」機能を採用。

これにより、次のスナップショットで提供されるクラス タイプが得られます。

例 3: Series.array プロパティで Np.array() メソッドを利用する
系列を NumPy 配列に変換する別の方法は、NumPy のメソッド「np.array()」です。このインスタンスでは、「Series.array」プロパティでこのメソッドを使用します。
最初に Pandas と NumPy ライブラリをインポートします。 「np」はNumPyのエイリアス、「pd」はPandasのエイリアスにしています。 「np.array()」メソッドがこのライブラリに属しているため、NumPy ライブラリをインポートします。
Pandas シリーズを作成するために「pd.Series()」メソッドが呼び出されます。シリーズに指定する値は、「Apple」、「Banana」、「Orange」、「Mango」、「Peach」、「Strawberry」、および「Grapes」です。この値のリストに定義されている「名前」は「フルーツ」であり、「インデックス」パラメーターにはインデックスの値が「F1」、「F2」、「F3」、「F4」、「F5」、「F6」として含まれています。 、「F7」。この索引リストは、デフォルトの順次リストの代わりに表示されます。シリーズはシリーズ オブジェクト「Bucket」に格納され、「print()」関数を使用して表示されます。
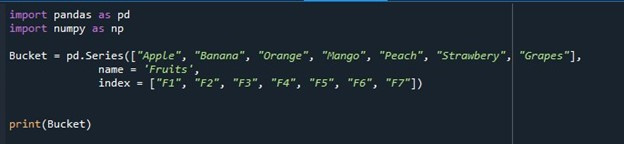
次のスナップショットは、構築されたシリーズを示しています。
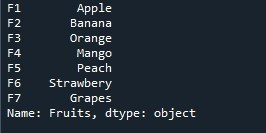
次に、このシリーズを必要な NumPy 配列に変換します。 「np.array()」メソッドが呼び出されます。その括弧内で、「Series.array」プロパティが渡されます。これにより、シリーズ値が NumPy 配列に変更されます。結果を保持するために、「値」変数があります。最後に、「print()」で NumPy 配列を表示します。

シリーズの値から生成された NumPy 配列がここに表示されます。

「type()」メソッドを使用して、配列の型が NumPy であることを確認します。

検証は成功しました。

例 4: Series.Index.Array プロパティで Np.Array() メソッドを利用する
前の例のシリーズを使用して、「Series.index.array」プロパティで「np.array()」メソッドを使用して、シリーズのインデックスを NumPy 配列に変換します。
「np.array()」メソッドが呼び出され、「Series.index.array」プロパティがシリーズ名「Bucket」で渡されます。 「Nump」変数は、結果を保持するためにここにあります。そして、「print()」関数はそれを画面に示します。

インデックス リストは NumPy 配列に変換されます。

例 5: Series.Index.Values プロパティで Np.Array() メソッドを利用する
最後に使用するメソッドは、「Series.index.values」プロパティを持つ「np.array()」メソッドです。
「np.Series()」メソッドは、「Series.index.values」プロパティで呼び出されます。このメソッドから生成された NumPy 配列は、「x」変数に配置され、端末に表示されます。

結果を以下に示します。

結論
この記事では、Pandas シリーズを NumPy 配列に変更する 5 つの手法について説明しました。最初の 2 つの図は、Pandas の「Series.to_numpy」メソッドを使用して実行されました。最初に系列の値を変換し、次にインデックス リストをこの関数で NumPy 配列に変換しました。次の 3 つの例では、NumPy のツールキットの「np.array()」メソッドを利用しました。シリーズとインデックス リストの値を NumPy 配列に変換するために、この関数に 3 つのプロパティを渡しました。