forループは、一連の命令を指定された回数だけ繰り返すことを可能にする制御構造です。これは、特にいくつかの要素に対して同じ操作を実行する必要がある場合や、DataFrame のようなデータ構造を反復する必要がある場合に、R での反復に一般的に使用される方法です。行と列は R の DataFrame を構成し、各行は単一の観測を表し、各列はその観測の変数または側面を表します。
この特定の記事では、for ループを使用して、さまざまなアプローチで DataFrame を反復処理します。行と列にまたがる for ループの反復は、大規模な DataFrame では非常に計算量が多いことに注意してください。
例 1: R の DataFrame 行で For ループを使用する
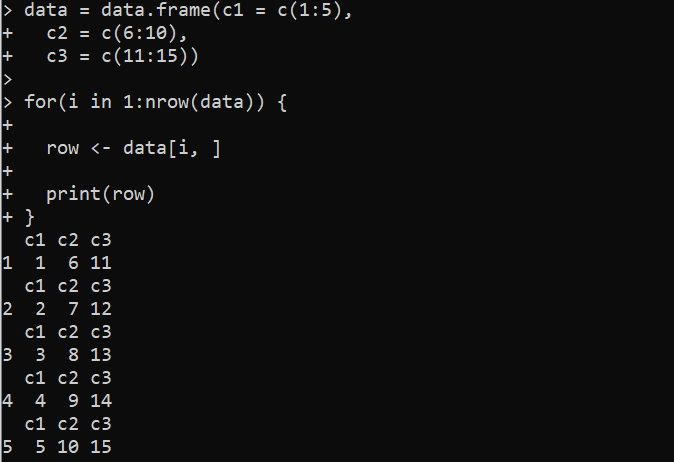
R の for ループを使用して、DataFrame の行を反復処理できます。 for ループ内では、行インデックスを使用して DataFrame の各行にアクセスできます。指定された DataFrame の行を反復する for ループのデモンストレーションである次の R コードを考えてみましょう。
data = data.frame(c1 = c(1:5),
c2 = c(6:10)、
c3 = c(11:15))
for(i in 1:nrow(データ)) {
行 <- データ[i, ]
印刷(行)
}
ここでは、まず「data」内に data.frame() 関数を定義します。ここの data.frame() 関数には 3 つの列が含まれています。各列には、それぞれ 1 ~ 5、6 ~ 10、11 ~ 15 の一連の数字が設定されています。その後、for ループ関数がデプロイされ、nrow() 関数を使用して DataFrame の「データ」の行を反復処理し、合計行数を取得します。ループ変数「i」は、「data」の全行数分の値を取ります。
次に、角かっこ表記「[ ]」を使用して、DataFrame「data」の i 行目を抽出します。抽出された行は「row」変数に格納され、print() 関数によって出力されます。
したがって、ループは DataFrame 内のすべての行を反復処理し、列の値とともに行番号を出力に表示します。
例 2: DataFrame 列に対する For ループの使用
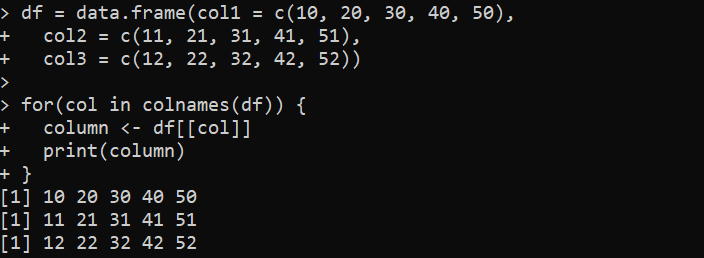
同様に、R の for ループを使用して、指定されたデータフレームの列をループできます。前のコードを使用して列をループできますが、for ループで ncol() 関数を使用する必要があります。逆に、for ループを使用して DataFrame の列をループする最も簡単な方法があります。これについては、次の R コードを検討してください。
df = data.frame(col1 = c(10, 20, 30, 40, 50),col2 = c(11, 21, 31, 41, 51),
col3 = c(12, 22, 32, 42, 52))
for(colnames(df)のcol){
列 <- df[[列]]
印刷(列)
}
ここでは、列の挿入で data.frame() が使用される df 変数を最初に作成します。 「df」DataFrame には、数値を含む 3 つの列が含まれています。次に、for ループを使用して、colnames() 関数を使用して「データ」DataFrame の列名を反復処理します。各反復で、ループ変数「col」は現在の列の名前を取ります。抽出された列は、「列」である新しい変数に格納されます。
したがって、「column」変数のデータは、次のコンソールに出力を出力します。
例 3: データフレーム全体で For ループを使用する
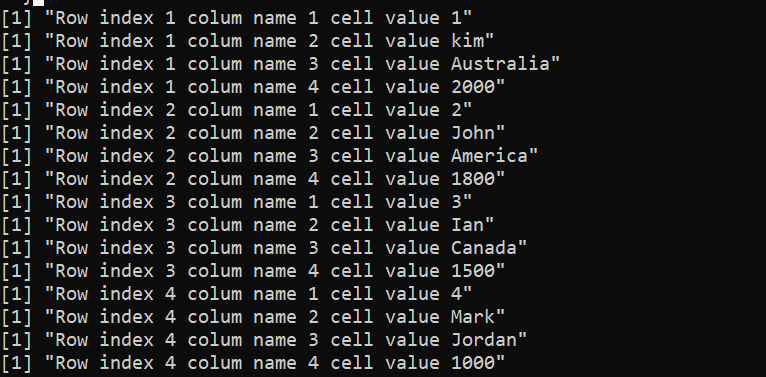
前の例では、for ループを使用して列と行をそれぞれループしました。ここで、ネストされた for ループを使用して、DataFrame の行と列の両方を同時に反復処理します。 R のコードを次に示します。ここでは、ネストされた for ループが列と行で使用されています。
従業員 <- data.frame(id=1:4,names=c('キム', 'ジョン', 'イアン', 'マーク'),
location=c('オーストラリア', 'アメリカ', 'カナダ', 'ヨルダン'),
給与=c(2000, 1800, 1500, 1000))
for (row in 1:nrow(employees)) {
for (col in 1:ncol(employees)) {
print(paste('行インデックス', 行, '列名', 列, 'セル値', 従業員[行, 列]))
}
}
ここで、列を設定するために data.frame() が呼び出される「employees」変数を宣言します。各列の値は、ベクトルを使用して指定されます。次に、「employees」DataFrame の行と列に対して、ネストされた 2 つの for ループを使用してデータを反復処理します。外側のループは、「1:nrow(employees)」を使用して、指定された DataFrame の行を反復処理します。行ごとに、「1:ncol(employees)」が内側のループで使用され、DataFrame の列を繰り返し反復処理します。
その後、ネストされたループ内に print() 関数があり、paste() 関数を展開して、行インデックス、列インデックス、およびセル値を単一の文字列に連結します。ここでの employee [row, col] 式は、現在のセルの値を取得します。行と列は、それぞれ既存の行と列のインデックスです。
したがって、コンソールの出力は、行インデックス、列インデックス、およびセル値が 1 つの文字列に連結されて取得されます。
例 4: R での for ループ代替メソッド
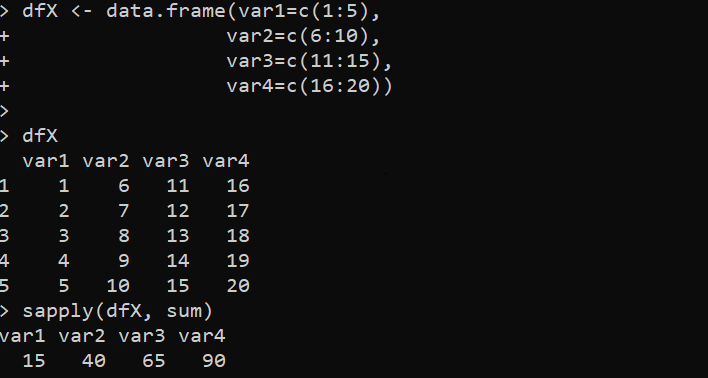
for ループは、R 言語では時代遅れになりました。ただし、for ループと同じように機能し、for ループよりも高速な代替方法がいくつか用意されています。このメソッドは、バックグラウンドで for ループを実行して DataFrame を反復処理する「apply family」関数からのものです。 sapply() 関数を使用して DataFrame をループする次の R コードを考えてみましょう。
dfX <- data.frame(var1=c(1:5),var2=c(6:10)、
var3=c(11:15),
var4=c(16:20))
dFX
sapply(dfX, 合計)
ここでは、まず、それぞれが数値を含む 2 つの列で data.frame() 関数を呼び出して、「dfX」DataFrame を確立します。次に、元の「dfX」DataFrame をコンソールに出力します。次のステップでは、sapply() 関数を使用して、提供された DataFrame を反復処理し、各列の合計を取得します。 sapply() 関数は、通常、「x」および「FUN」引数を取ります。この場合、X は「dfX」DataFrame であり、「FUN」は DataFrame の各列に適用される sum() 関数です。
sapply() 関数によって達成される反復の結果は、次の画面で達成されます。 DataFrame の合計操作の結果は、列ごとに表示されます。さらに、R の for ループ操作に「apply ファミリー」の他の関数を使用することもできます。
結論
for ループを使用して、DataFrame の行または列を反復処理し、特定の操作を実行します。 for ループは、列と行を反復処理するために個別に使用されます。さらに、これを使用して、データフレームの列と行の両方を同時に反復処理します。ほとんどの場合、目的の結果を得るために関数を適用する方が効果的です。 apply 関数の例は、for ループ操作の最後の例に示されています。