キール (進化的学習に基づく知識抽出) は、進化的アルゴリズムの実装に特化した Java ベースのソフトウェア ツールです。オープンソースであるため、データマイニングと分析コミュニティを強化する実験で使用できるさまざまな知識発見アルゴリズムを提供します。このツールの全体的な複雑さを大幅に軽減する、シンプルで使いやすいグラフィカル ユーザー インターフェイスを提供します。市場に出回っているほとんどの同様のツールは、ユーザーがコードを記述して対話する必要がありますが、Keel は、初心者と専門家の両方が使用できる直感的な GUI を提供することで、この要件を取り除きます。
Keel は、分類、回帰、特徴抽出、パターン分析、クラスタリングなど、さまざまな計算知能ベースのアルゴリズムを提供します。主流のモデルがアプリケーション自体に組み込まれているため、Keel は、生データセットで探索的データ分析を実行する場合に非常に便利なツールです。シンプルなドラッグ アンド ドロップ インターフェイスと機能の使いやすさを組み合わせることで、教育目的と研究目的の両方で、迅速かつ効率的なデータ マイニング実験を行うことができます。キールのようなツールは、他の方法では複雑なアルゴリズムの実践に対する単純化されたアプローチのため、人気が高まっています。
インストール
インストールには主に2つの方法があります キール 任意の Linux マシンで。最初のものはに行くことを含みます キールのウェブページ そこからソフトウェアをダウンロードします。このインストール ガイドで説明する 2 番目の方法では、Keel をダウンロードする必要があります。 wget Linux ユーザー向けのダウンロード ツール。
1.取得することから始めます wget Linuxマシンで。
次のコマンドを実行して、wget をダウンロードします。 適切な パッケージマネージャー:
$ 須藤 apt-get インストール wget
同様の端末出力が表示されます。
2.これで、 wget ツールを Linux マシンにインストールし、それを使用して キール 道具。
これは リンク これを wget に渡します。
ターミナルで次のコマンドを実行します。
$ wget http: /// sci2s.ugr.es / キール / ソフトウェア / 試作品 / オープンバージョン / ソフトウェア- 2018年 -04-09.zip
端末に同様の出力が表示されるはずです。
Keel のダウンロードが完了したら、残りのインストールを続行できます。
3. Linux Unzip ツールを使用して、前のステップでダウンロードした圧縮ファイルを解凍します。
次のコマンドを実行します。
$ 解凍する ソフトウェア- 2018年 -04-09.zip
ターミナルに同様の出力が表示されるはずです。
4. 次のコマンドを実行して、Keel フォルダーに移動します。
$ CD ソフトウェア- 2018年 -04-09 / ドキュメント / 実験 / キール / 距離 /
5. 次のコマンドを実行して、インストールを開始します。
$ ジャワ -jar . / GraphInterKeel.jar
これで、Linux マシンで Keel を使用できるようになります。
ユーザーガイド
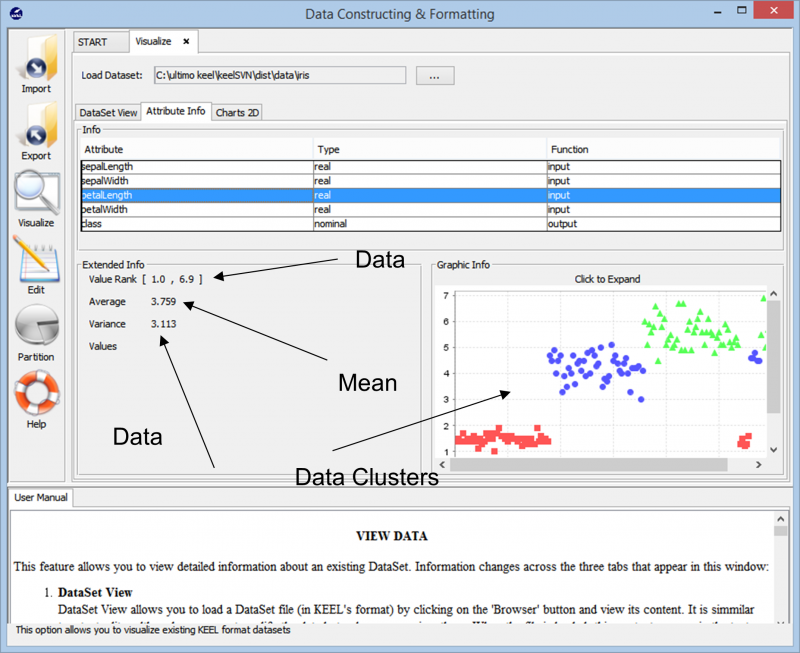
との相互作用 キール アプリケーションは本当に簡単でシンプルです。インポートすることから始めましょう アイリスデータセット 私たちのワークスペースに。
データをインポートすると、ツールはデータ セット内のデータ ポイントの全体的なクラスタリングを表示します。また、データセットに存在するさまざまなクラスと、これらのデータポイントがまたがる数値範囲、全体的な分散および平均値などの基本情報も表示されます。この情報により、ユーザーは、あらゆる種類のデータ分析タスクのデータ準備を進める方法をよりよく理解できます。
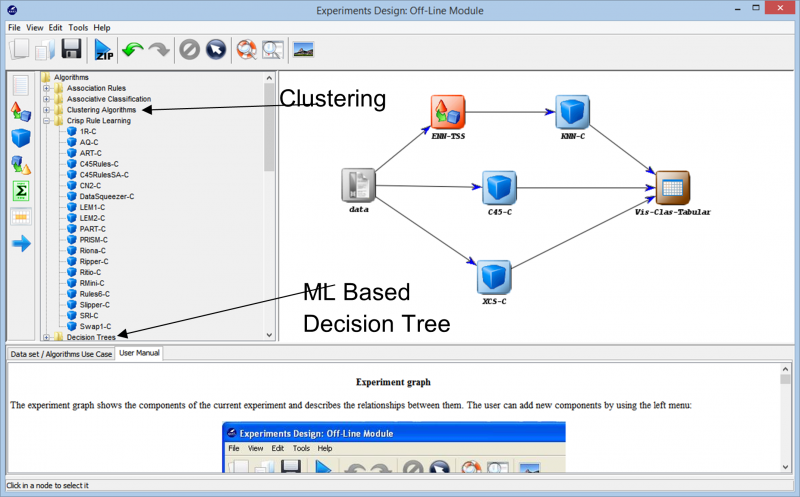
実験をさらに進めると、任意のデータセットで実験を作成するために使用できるさまざまな手法に出くわします。次の画像は、データに使用できるさまざまな学習アルゴリズムを示しています。データ セットの性質と実験の要件に応じて、さまざまなアルゴリズムを試すことができます。
たとえば、ラベル付けされていないデータを扱っていて、データ セット内の異なるデータ ポイント間の類似点を見つける必要がある場合、利用可能なさまざまなオプションからクラスタリング アルゴリズムを使用すると、データ ポイントをよりよく理解するのに役立ちます。これは最終的に、データ ポイントのラベル付けと分類に役立ち、より包括的な教師あり学習アルゴリズムを使用して実験を構築できるようになります。
結論
の キール データ分析のプラットフォームは、研究と教育の両方の目的に適したリソースです。使いやすいグラフィカル ユーザー インターフェイスは、ユーザーがデータの要件をよりよく理解するのに役立ち、ワークフローでユーザーをさらに支援する便利なテクニックとアルゴリズムへの論理的な参照を提供します。さまざまなカテゴリとアルゴリズム手法に分類されるさまざまなアルゴリズムを幅広く用意することで、ユーザーは多数の論理的な方向性を試し、これらの結果を比較して、あらゆる問題に対する最適なソリューションに到達できるようになります。
Keel のデータ マイニングへのコード フリー ドラッグ アンド ドロップ アプローチは、初心者でも包括的な計算インテリジェンス モデルを簡単に操作できるようにします。これにより、複雑なデータセットへの洞察が得られ、その結果、現実世界の問題を解決するのに役立つ有用な推論が導き出されます。