プロファイリング ツールを使用した Python コードの最適化
プロファイリング ツールを使用して Python コードを最適化できるように Google Colab をセットアップするには、まず Google Colab 環境をセットアップします。 Colab を初めて使用する場合、Colab は、Jupyter ノートブックやさまざまな Python ライブラリへのアクセスを提供する、不可欠で強力なクラウドベースのプラットフォームです。 Colab にアクセスするには、(https://colab.research.google.com/) にアクセスし、新しい Python ノートブックを作成します。
プロファイリング ライブラリをインポートする
私たちの最適化は、プロファイリング ライブラリの熟練した使用に依存しています。このコンテキストにおける 2 つの重要なライブラリは、cProfile と line_profiler です。
輸入 cプロフィール
輸入 ラインプロファイラー
「cProfile」ライブラリはコードをプロファイリングするための組み込み Python ツールですが、「line_profiler」はコードを 1 行ずつさらに深く分析できる外部パッケージです。
このステップでは、再帰関数を使用してフィボナッチ数列を計算するサンプル Python スクリプトを作成します。このプロセスをさらに詳しく分析してみましょう。フィボナッチ数列は、連続する各数値がその前の 2 つの数値の合計である一連の数値です。通常は 0 と 1 で始まるため、シーケンスは 0、1、1、2、3、5、8、13、21 などのようになります。これは、再帰的な性質があるため、プログラミングの例としてよく使用される数列です。
再帰フィボナッチ関数で「Fibonacci」という Python 関数を定義します。この関数は、計算したいフィボナッチ数列内の位置を表す「n」整数を引数として受け取ります。たとえば、「n」が 5 に等しい場合、フィボナッチ数列の 5 番目の数値を見つけたいとします。
確かに フィボナッチ ( n ) :
次に、基本ケースを確立します。再帰の基本ケースは、呼び出しを終了し、所定の値を返すシナリオです。フィボナッチ数列では、「n」が 0 または 1 の場合、結果はすでにわかっています。 0 番目と 1 番目のフィボナッチ数はそれぞれ 0 と 1 です。
もし n <= 1 :戻る n
この「if」ステートメントは、「n」が 1 以下であるかどうかを判断します。1 以下である場合は、それ以上再帰する必要がないため、「n」自体を返します。
再帰的計算
「n」が 1 を超える場合、再帰的計算が続行されます。この場合、「(n-1)」番目と「(n-2)」番目のフィボナッチ数を合計して、「n」番目のフィボナッチ数を見つける必要があります。これは、関数内で 2 つの再帰呼び出しを行うことで実現します。
それ以外 :戻る フィボナッチ ( n - 1 ) + フィボナッチ ( n - 2 )
ここで、「fibonacci(n – 1)」は「(n-1)」番目のフィボナッチ数を計算し、「fibonacci(n – 2)」は「(n-2)」番目のフィボナッチ数を計算します。これら 2 つの値を加算して、「n」位置に目的のフィボナッチ数を取得します。
要約すると、この「フィボナッチ」関数は、問題をより小さなサブ問題に分割することによってフィボナッチ数を再帰的に計算します。基本ケース (0 または 1) に達するまで再帰呼び出しを行い、既知の値を返します。他の「n」については、「(n-1)」と「(n-2)」の 2 つの再帰呼び出しの結果を合計することによってフィボナッチ数が計算されます。
この実装はフィボナッチ数を計算するのが簡単ですが、最も効率的ではありません。後の手順では、プロファイリング ツールを使用してパフォーマンス制限を特定し、最適化して実行時間を短縮します。
CProfile を使用したコードのプロファイリング
ここで、「cProfile」を使用して「フィボナッチ」関数のプロファイルを作成します。このプロファイリング演習では、各関数呼び出しにかかる時間についての洞察が得られます。
cプロファイラー = cプロフィール。 プロフィール ( )cプロファイラー。 有効にする ( )
結果 = フィボナッチ ( 30 )
cプロファイラー。 無効にする ( )
cプロファイラー。 print_stats ( 選別 = '累積的な' )
このセグメントでは、「cProfile」オブジェクトを初期化し、プロファイリングをアクティブ化し、「n=30」で「fibonacci」関数をリクエストし、プロファイリングを非アクティブ化し、累積時間でソートされた統計を表示します。この初期プロファイリングにより、どの関数が最も時間を消費しているかについての概要が得られます。
! pip インストール line_profiler輸入 cプロフィール
輸入 ラインプロファイラー
確かに フィボナッチ ( n ) :
もし n <= 1 :
戻る n
それ以外 :
戻る フィボナッチ ( n - 1 ) + フィボナッチ ( n - 2 )
cプロファイラー = cプロフィール。 プロフィール ( )
cプロファイラー。 有効にする ( )
結果 = フィボナッチ ( 30 )
cプロファイラー。 無効にする ( )
cプロファイラー。 print_stats ( 選別 = '累積的な' )
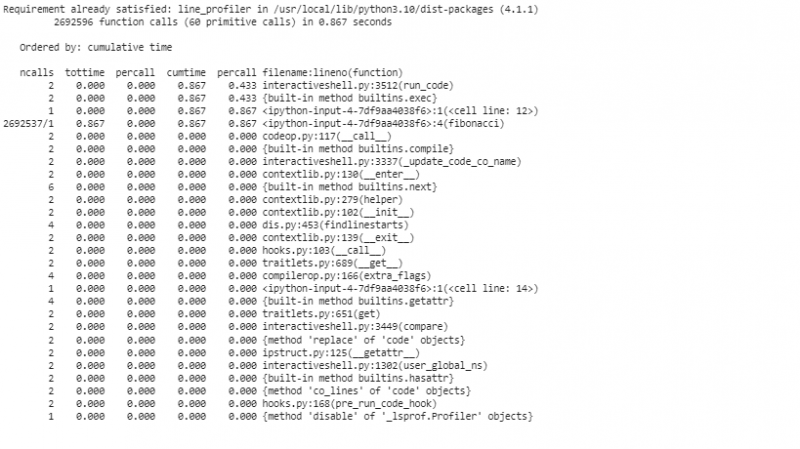
より詳細な分析のために line_profiler を使用してコードを 1 行ずつプロファイリングするには、「line_profiler」を使用してコードを 1 行ずつセグメント化します。 「line_profiler」を使用する前に、Colab リポジトリにパッケージをインストールする必要があります。
! pip インストール line_profiler「line_profiler」の準備ができたので、それを「fibonacci」関数に適用できます。
%load_ext line_profiler確かに フィボナッチ ( n ) :
もし n <= 1 :
戻る n
それ以外 :
戻る フィボナッチ ( n - 1 ) + フィボナッチ ( n - 2 )
%lprun -f フィボナッチ フィボナッチ ( 30 )
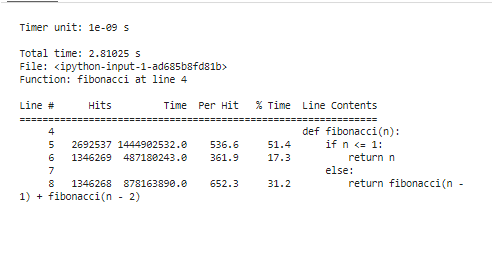
このスニペットは、「line_profiler」拡張機能をロードすることから始まり、「fibonacci」関数を定義し、最後に「%lprun」を利用して「n=30」で「fibonacci」関数をプロファイリングします。実行時間を行ごとにセグメント化し、コードがリソースを消費する場所を正確に明らかにします。
プロファイリング ツールを実行して結果を分析すると、コードのパフォーマンス特性を示す一連の統計が表示されます。これらの統計には、各関数内で費やされた合計時間とコードの各行の継続時間が含まれます。たとえば、フィボナッチ関数は、同じ値を複数回再計算するためにもう少し多くの時間を費やしていることがわかります。これは冗長な計算であり、メモ化または反復アルゴリズムの採用によって最適化を適用できる明確な領域です。
次に、フィボナッチ関数で潜在的な最適化を特定した最適化を行います。この関数は同じフィボナッチ数を複数回再計算するため、不必要な冗長性が生じ、実行時間が遅くなることがわかりました。
これを最適化するために、メモ化を実装します。メモ化は、以前に計算された結果 (この場合はフィボナッチ数) を保存し、必要に応じて再計算する代わりにそれらを再利用する最適化手法です。これにより、冗長な計算が削減され、特にフィボナッチ数列のような再帰関数のパフォーマンスが向上します。
フィボナッチ関数でメモ化を実装するには、次のコードを作成します。
# 計算されたフィボナッチ数を保存する辞書fib_cache = { }
確かに フィボナッチ ( n ) :
もし n <= 1 :
戻る n
# 結果がすでにキャッシュされているかどうかを確認する
もし n で fib_キャッシュ:
戻る fib_cache [ n 】
それ以外 :
# 結果を計算してキャッシュする
fib_cache [ n 】 = フィボナッチ ( n - 1 ) + フィボナッチ ( n - 2 )
戻る fib_cache [ n 】 、
「fibonacci」関数のこの修正バージョンでは、以前に計算されたフィボナッチ数を保存するための「fib_cache」辞書を導入します。フィボナッチ数を計算する前に、それがすでにキャッシュ内にあるかどうかを確認します。存在する場合は、キャッシュされた結果を返します。それ以外の場合は、計算してキャッシュに保持してから返します。
プロファイリングと最適化を繰り返す
最適化 (この場合はメモ化) を実装した後、プロファイリング プロセスを繰り返して、変更の影響を確認し、コードのパフォーマンスが向上したことを確認することが重要です。
最適化後のプロファイリング
同じプロファイリング ツール「cProfile」と「line_profiler」を使用して、最適化されたフィボナッチ関数をプロファイリングできます。新しいプロファイリング結果を以前の結果と比較することで、最適化の有効性を測定できます。
「cProfile」を使用して最適化された「フィボナッチ」関数をプロファイリングする方法は次のとおりです。
cプロファイラー = cプロフィール。 プロフィール ( )cプロファイラー。 有効にする ( )
結果 = フィボナッチ ( 30 )
cプロファイラー。 無効にする ( )
cプロファイラー。 print_stats ( 選別 = '累積的な' )
「line_profiler」を使用して、行ごとにプロファイルを作成します。
%lprun -f フィボナッチ フィボナッチ ( 30 )コード:
# 計算されたフィボナッチ数を保存する辞書fib_cache = { }
確かに フィボナッチ ( n ) :
もし n <= 1 :
戻る n
# 結果がすでにキャッシュされているかどうかを確認する
もし n で fib_キャッシュ:
戻る fib_cache [ n 】
それ以外 :
# 結果を計算してキャッシュする
fib_cache [ n 】 = フィボナッチ ( n - 1 ) + フィボナッチ ( n - 2 )
戻る fib_cache [ n 】
cプロファイラー = cプロフィール。 プロフィール ( )
cプロファイラー。 有効にする ( )
結果 = フィボナッチ ( 30 )
cプロファイラー。 無効にする ( )
cプロファイラー。 print_stats ( 選別 = '累積的な' )
%lprun -f フィボナッチ フィボナッチ ( 30 )
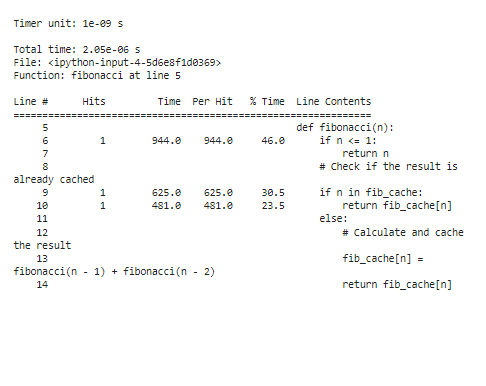
最適化後にプロファイリング結果を分析すると、特に「n」値が大きい場合に、実行時間が大幅に短縮されます。メモ化のおかげで、関数がフィボナッチ数の再計算に費やす時間が大幅に短縮されたことがわかります。
これらの手順は、最適化プロセスにおいて不可欠です。最適化には、プロファイリングから得られた観察結果に基づいて、情報に基づいてコードを変更することが含まれます。また、プロファイリングを繰り返すことで、最適化によって期待されるパフォーマンスの向上が確実に得られます。プロファイリング、最適化、検証を繰り返すことで、Python コードを微調整してパフォーマンスを向上させ、アプリケーションのユーザー エクスペリエンスを向上させることができます。
結論
この記事では、Google Colab 環境内でプロファイリング ツールを使用して Python コードを最適化する例について説明しました。セットアップでサンプルを初期化し、必須のプロファイリング ライブラリをインポートし、サンプル コードを作成し、「cProfile」と「line_profiler」の両方を使用してプロファイリングし、結果を計算し、最適化を適用して、コードのパフォーマンスを繰り返し調整しました。