概要
この投稿では次のことを説明します。
- LangChain のエージェントとそのツールの両方にメモリを追加する方法
- ステップ 1: フレームワークのインストール
- ステップ 2: 環境のセットアップ
- ステップ 3: ライブラリのインポート
- ステップ 4: ReadOnlyMemory の追加
- ステップ 5: ツールのセットアップ
- ステップ 6: エージェントの構築
- 方法 1: ReadOnlyMemory を使用する
- 方法 2: エージェントとツールの両方に同じメモリを使用する
- 結論
LangChain のエージェントとそのツールの両方にメモリを追加するにはどうすればよいですか?
エージェントとツールにメモリを追加すると、モデルのチャット履歴を使用できるようになり、より適切に動作できるようになります。メモリがあれば、エージェントはどのツールをいつ導入するかを効率的に決定できます。 「」を使用することをお勧めします。 読み取り専用メモリ 」をエージェントとツールの両方に適用するため、変更できなくなります。 LangChain のエージェントとツールの両方にメモリを追加するプロセスを学習するには、以下の手順を実行してください。
ステップ 1: フレームワークのインストール
まず、インストールします ラングチェーン実験的 モジュールを使用して、エージェントの言語モデルとツールを構築するための依存関係を取得します。 LangChain Experimental は、主に実験やテストに使用されるモデルを構築するための依存関係を取得するモジュールです。
pip インストール ラングチェーン - 実験的な
入手 グーグル検索結果 OpenAI の依存関係を含むモジュールを使用して、インターネットから最も関連性の高い回答を取得します。
pip インストール openai google - 検索 - 結果
ステップ 2: 環境のセットアップ
インターネットから回答を取得するモデルを構築するには、 OpenAI そして セルパピ キー:
輸入 あなた
輸入 ゲットパス
あなた。 約 [ 「OPENAI_API_KEY」 】 = ゲットパス。 ゲットパス ( 「OpenAI API キー:」 )
あなた。 約 [ 「SERPAPI_API_KEY」 】 = ゲットパス。 ゲットパス ( 「Serpapi API キー:」 )
ステップ 3: ライブラリのインポート
環境をセットアップした後、ライブラリをインポートして、エージェント用のツールとそれらと統合するための追加メモリを構築します。次のコードは、エージェント、メモリ、LLMS、チェーン、プロンプト、およびユーティリティを使用して、必要なライブラリを取得します。
ラングチェーンから。 エージェント 輸入 ゼロショットエージェント 、 道具 、 エージェントエグゼキュータラングチェーンから。 メモリ 輸入 会話バッファメモリ 、 読み取り専用共有メモリ
ラングチェーンから。 llms 輸入 OpenAI
#ライブラリを入手 のために LangChainを使用してチェーンを構築する
ラングチェーンから。 鎖 輸入 LLMチェーン
ラングチェーンから。 プロンプト 輸入 プロンプトテンプレート
#ライブラリを入手 のために インターネットから情報を得る
ラングチェーンから。 公共事業 輸入 SerpAPIラッパー
ステップ 4: ReadOnlyMemory の追加
ユーザーが入力するとすぐにエージェントがタスクの実行を開始できるようにテンプレートを構成します。その後、 「ConversationBufferMemory()」 モデルのチャット履歴を保存し、初期化します。 「読み取り専用メモリ」 エージェントとそのツールの場合:
テンプレート = 「」 「これは人間とボットの間の会話です。{チャット履歴}
#正確かつ簡単な要約を抽出するための構造を設定する
{input} のチャットを要約します。
」 「」
プロンプト = プロンプトテンプレート ( 入力変数 = [ '入力' 、 「チャット履歴」 】 、 テンプレート = テンプレート )
メモリ = 会話バッファメモリ ( メモリキー = 「チャット履歴」 )
読み取り専用メモリ = 読み取り専用共有メモリ ( メモリ = メモリ )
すべてのコンポーネントを統合する #summary チェーン のために 会話の要約を取得する
サマリーチェーン = LLMチェーン (
llm = OpenAI ( ) 、
プロンプト = プロンプト 、
冗長な = 真実 、
メモリ = 読み取り専用メモリ 、
)
ステップ 5: ツールのセットアップ
次に、検索や概要などのツールを設定して、チャットの概要とともにインターネットから回答を取得します。
検索 = SerpAPIラッパー ( )ツール = [
道具 (
名前 = '検索' 、
機能 = 検索。 走る 、
説明 = 「最近の出来事に関する対象を絞った質問に対する適切な応答」 、
) 、
道具 (
名前 = 'まとめ' 、
機能 = サマリーチェーン。 走る 、
説明 = 「チャットを要約するのに役立ちます。このツールへの入力は、この要約を読む人を表す文字列である必要があります。」 、
) 、
】
ステップ 6: エージェントの構築
ツールが必要なタスクを実行し、インターネットから回答を抽出する準備ができたら、すぐにエージェントを構成します。 ” 接頭語 」変数は、エージェントがタスクをツールに割り当てる前に実行され、「 サフィックス 」は、ツールが答えを抽出した後に実行されます。
接頭語 = 「」 「人間と会話し、次のツールにアクセスして、次の質問にできる限り答えてください。」 「」サフィックス = 「」 '始める!'
#構造 のために エージェントがメモリを使用しながらツールの使用を開始する
{ チャット履歴 }
質問 : { 入力 }
{ エージェント_スクラッチパッド } 「」 」
プロンプト = ZeroShotAgent.create_prompt(
#質問のコンテキストを理解するためにプロンプト テンプレートを設定します
ツール、
プレフィックス=接頭辞、
サフィックス=接尾辞、
input_variables=[' 入力 '、' チャット履歴 '、' エージェント_スクラッチパッド ']、
)
方法 1: ReadOnlyMemory を使用する
エージェントがツールを実行するように設定されると、ReadOnlyMemory を備えたモデルが 好ましい 答えを取得するチェーンを構築して実行する方法とそのプロセスは次のとおりです。
ステップ 1: チェーンの構築
このメソッドの最初のステップは、チェーンと実行プログラムを構築することです。 「ゼロショットエージェント()」 その議論とともに。の 「LLMChain()」 llm 引数とプロンプト引数を使用して、言語モデル内のすべてのチャット間の接続を構築するために使用されます。エージェントは、llm_chain、tools、およびverboseを引数として使用し、エージェントとそのツールの両方をメモリで実行するためのagent_chainを構築します。
llm_chain = LLMチェーン ( llm = OpenAI ( 温度 = 0 ) 、 プロンプト = プロンプト )エージェント = ゼロショットエージェント ( llm_chain = llm_chain 、 ツール = ツール 、 冗長な = 真実 )
エージェントチェーン = エージェントエグゼキュータ。 from_agent_and_tools (
エージェント = エージェント 、 ツール = ツール 、 冗長な = 真実 、 メモリ = メモリ
)
ステップ 2: チェーンのテスト
電話してください エージェントチェーン run() メソッドを使用してインターネットから質問します。
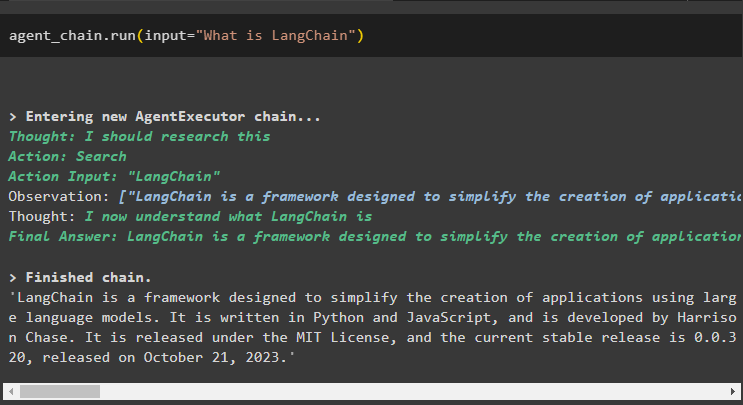
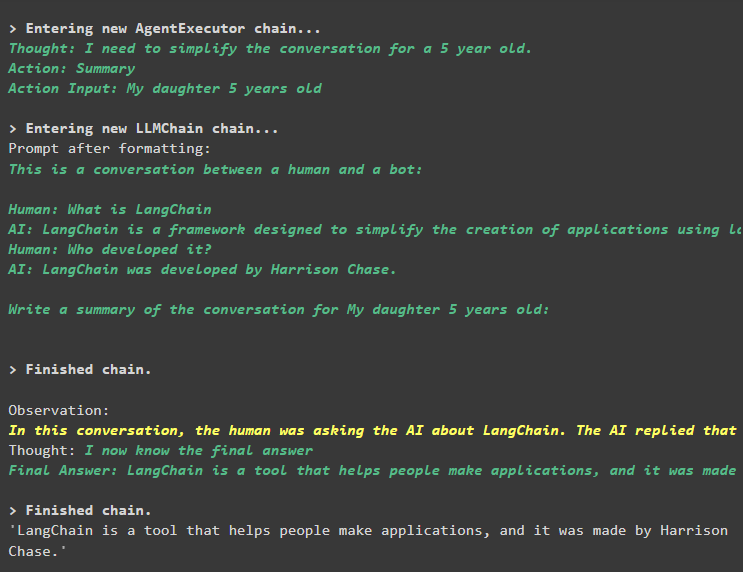
エージェントチェーン。 走る ( 入力 = 「ラングチェーンとは何ですか?」 )エージェントは検索ツールを使用してインターネットから回答を抽出しました。
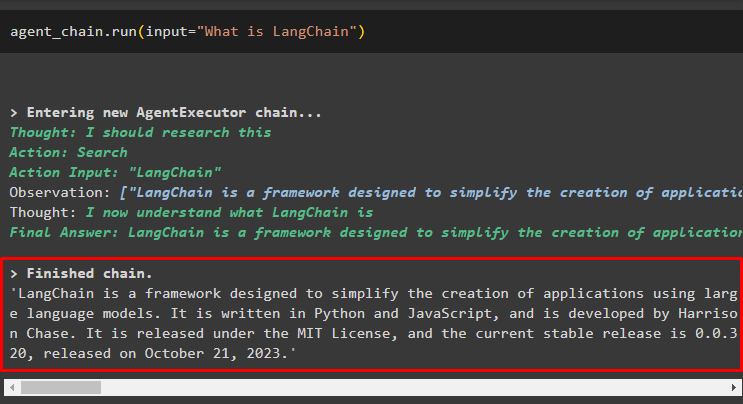
ユーザーは、不明瞭なフォローアップの質問をして、エージェントに接続されているメモリをテストできます。
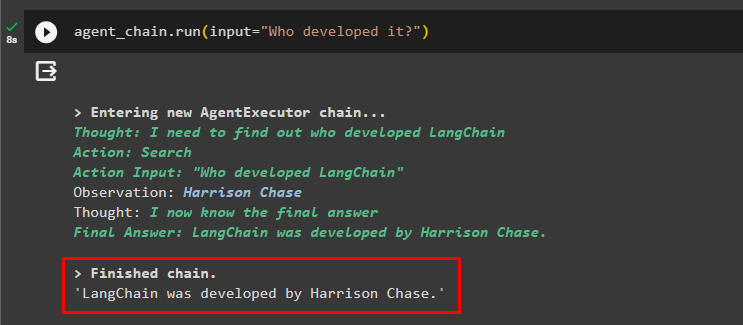
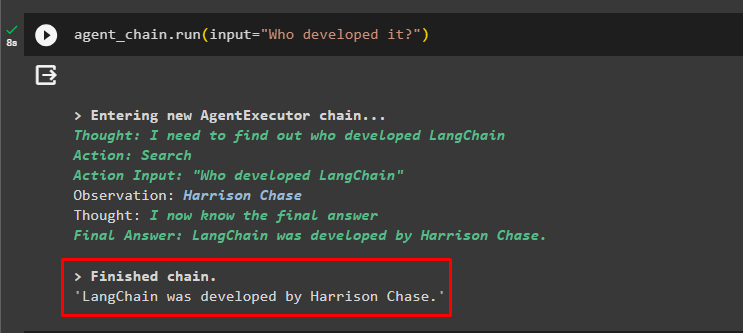
エージェントチェーン。 走る ( 入力 = 「誰が開発したの?」 )エージェントは前のチャットを使用して質問のコンテキストを理解し、次のスクリーンショットに示すように回答を取得しました。
エージェントはツール (summary_chain) を使用して、エージェントのメモリを使用して以前に抽出したすべての回答の概要を抽出します。
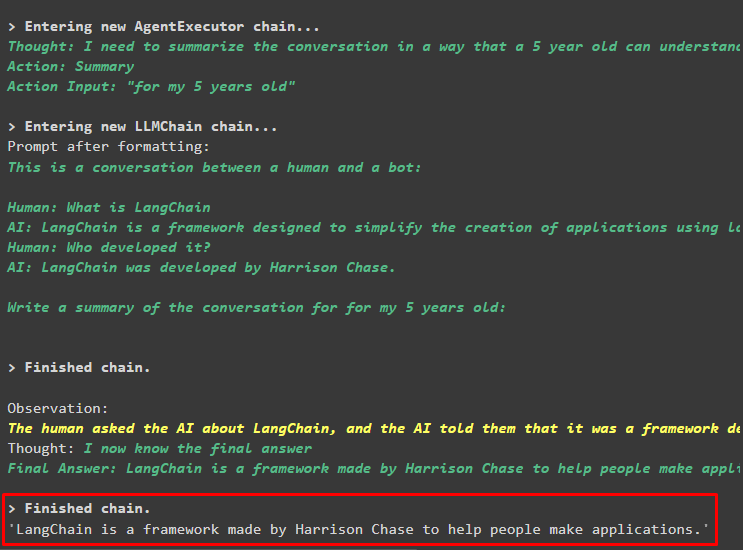
エージェントチェーン。 走る (入力 = 「ありがとう! 5 歳の息子のために、会話を要約して」
)

出力
次のスクリーンショットには、5 歳児向けに以前に寄せられた質問の概要が表示されています。
ステップ 3: メモリをテストする
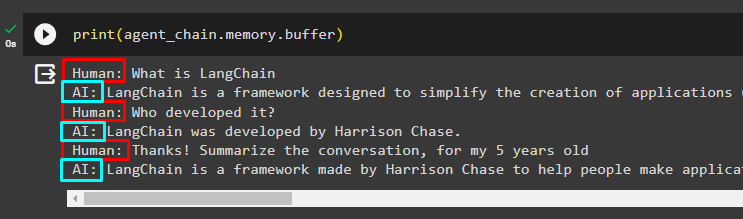
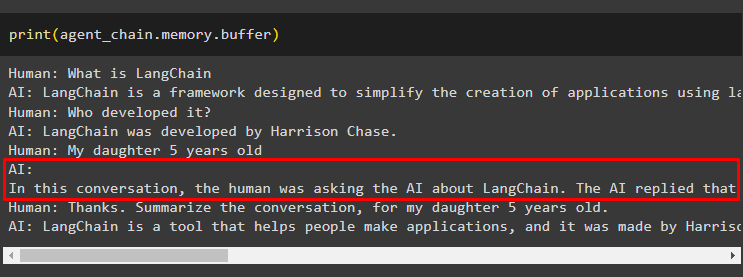
次のコードを使用して、バッファ メモリを出力し、バッファ メモリに保存されているチャットを抽出します。
印刷する ( エージェントチェーン。 メモリ 。 バッファ )次のスニペットには、変更を加えずに正しい順序でチャットが表示されています。
方法 2: エージェントとツールの両方に同じメモリを使用する
プラットフォームによって推奨されていない 2 番目の方法は、エージェントとツールの両方にバッファ メモリを使用する方法です。このツールはメモリに保存されているチャットを変更することができ、大規模な会話では誤った出力が返される可能性があります。
ステップ 1: チェーンの構築
テンプレートの完全なコードを使用して、エージェント用のツールとチェーンを構築します。今回は ReadOnlyMemory が追加されていないため、小さな変更が加えられています。
テンプレート = 「」 「これは人間とボットの間の会話です。{チャット履歴}
{input} の会話の概要を書きます。
」 「」
#チャットの構造を構築する インターフェース チェーン付きのメモリを追加してプロンプト テンプレートを使用する
プロンプト = プロンプトテンプレート ( 入力変数 = [ '入力' 、 「チャット履歴」 】 、 テンプレート = テンプレート )
メモリ = 会話バッファメモリ ( メモリキー = 「チャット履歴」 )
サマリーチェーン = LLMチェーン (
llm = OpenAI ( ) 、
プロンプト = プロンプト 、
冗長な = 真実 、
メモリ = メモリ 、
)
#ツールを構築する ( 検索と要約 ) のために エージェントの構成
検索 = SerpAPIラッパー ( )
ツール = [
道具 (
名前 = '検索' 、
機能 = 検索。 走る 、
説明 = 「最近の出来事に関する対象を絞った質問に対する適切な応答」 、
) 、
道具 (
名前 = 'まとめ' 、
機能 = サマリーチェーン。 走る 、
説明 = 「チャットの概要を取得するのに役立ち、この概要を読む人を表す文字列をこのツールに入力する必要があります。」 、
) 、
】
#手順を説明します のために エージェントがツールを使用して情報を抽出する のために チャット
接頭辞 = 「」 「次のツールにアクセスして、人間と会話し、可能な限り最善の方法で質問に答えます。」 「」
サフィックス = 「」 '始める!'
#構造 のために エージェントがメモリを使用しながらツールの使用を開始する
{ チャット履歴 }
質問 : { 入力 }
{ エージェント_スクラッチパッド } 「」 」
プロンプト = ZeroShotAgent.create_prompt(
#質問のコンテキストを理解するためにプロンプト テンプレートを設定します
ツール、
プレフィックス=接頭辞、
サフィックス=接尾辞、
input_variables=[' 入力 '、' チャット履歴 '、' エージェント_スクラッチパッド ']、
)
#エージェント エグゼキューターの構築中にすべてのコンポーネントを統合します
llm_chain = LLMChain(llm=OpenAI(温度=0)、プロンプト=プロンプト)
エージェント = ZeroShotAgent(llm_chain=llm_chain、tools=ツール、verbose=True)
Agent_chain = AgentExecutor.from_agent_and_tools(
エージェント = エージェント、ツール = ツール、冗長 = True、メモリ = メモリ
)
ステップ 2: チェーンのテスト
次のコードを実行します。
エージェントチェーン。 走る ( 入力 = 「ラングチェーンとは何ですか?」 )答えは正常に表示され、メモリに保存されます。
文脈をあまり説明せずに、フォローアップの質問をします。
エージェントチェーン。 走る ( 入力 = 「誰が開発したの?」 )エージェントはメモリを使用して質問を変換し、回答を出力します。
エージェントに接続されたメモリを使用してチャットの概要を取得します。
エージェントチェーン。 走る (入力 = 「ありがとう! 5 歳の息子のために、会話を要約して」
)
出力
概要は正常に抽出され、ここまではすべて同じように見えますが、変更は次のステップで行われます。
ステップ 3: メモリをテストする
次のコードを使用して、メモリからチャット メッセージを抽出します。
印刷する ( エージェントチェーン。 メモリ 。 バッファ )このツールは、元々尋ねられていなかった別の質問を追加することで履歴を変更しました。これは、モデルが質問を理解するときに発生します。 自問する 質問。ツールはユーザーからの質問であると誤って認識し、別のクエリとして扱います。したがって、追加の質問もメモリに追加され、会話のコンテキストを取得するために使用されます。
それは今のところすべてです。
結論
LangChain のエージェントとそのツールの両方にメモリを追加するには、モジュールをインストールして依存関係を取得し、そこからライブラリをインポートします。その後、会話メモリ、言語モデル、ツール、メモリを追加するエージェントを構築します。の 推奨される方法 メモリを追加するには、エージェントとそのツールに ReadOnlyMemory を使用してチャット履歴を保存します。ユーザーは、 会話記憶 エージェントとツールの両方に。しかし、彼らは得ます 混乱した 時々、メモリ内のチャットを変更します。