このガイドでは、S3 バケットからデータをフェッチするクローラーを作成する方法について説明します。
S3 バケットからデータをフェッチするクローラーを作成するにはどうすればよいですか?
AWS でクローラーを作成するには、「」にアクセスしてください。 AWS グルー Amazon ダッシュボードからのサービス:
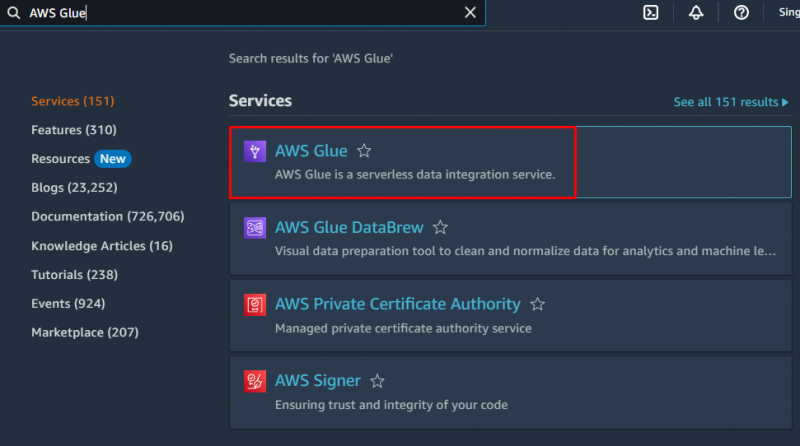
クリックしてください ' データベース データカタログセクションの「」ボタンをクリックしてデータベースを作成します。
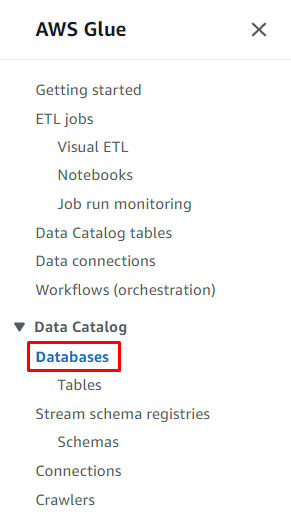
クリックしてください ' データベースの追加 」ボタンをクリックして設定を開始します。
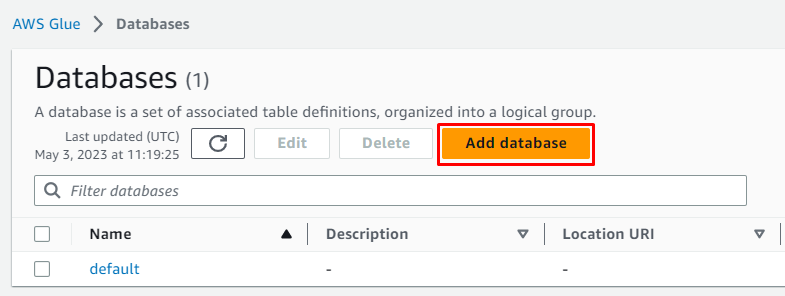
データベースの名前を入力し、すべてをオプションのままにしてから、「」をクリックします。 データベースの作成 ' ボタン:
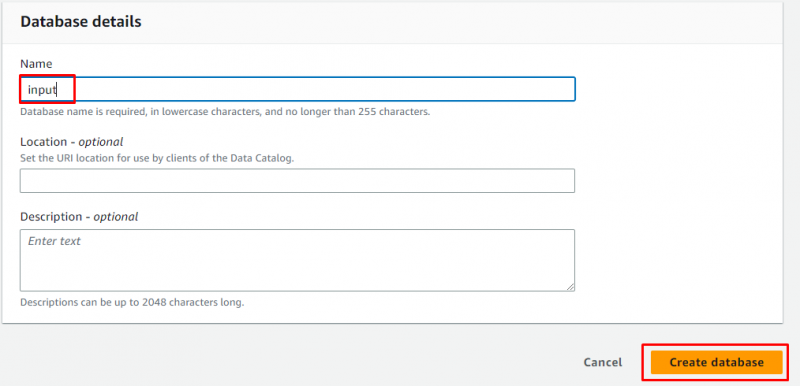
データベースが正常に作成されました。
その後は、「」に向かうだけです。 クローラー 」ページを左側のパネルからクリックして開きます。
クリックしてください ' クローラーの作成 ' ボタン:

クローラーの名前を入力し、「」をクリックします。 次 ' ボタン:

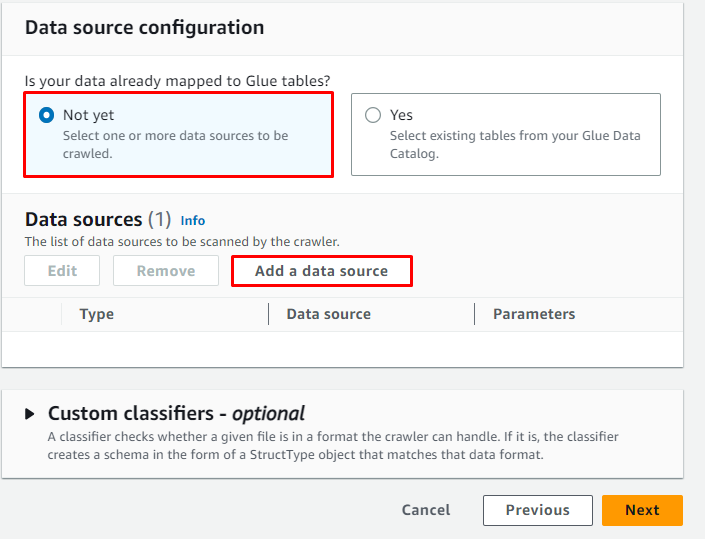
クリックしてください ' データソースを追加する 」ボタンをクリックしてデータのソースを選択します。
データが保存されているパスを確認するには、S3 サービスにアクセスします。
データがアップロードされる S3 バケットに移動します。ユーザーができることは、 作成 バケツと アップロード AWS S3 ダッシュボードからのデータ:

クリックしてください ' S3 を参照 」ボタンをクリックしてデータのパスを選択します。
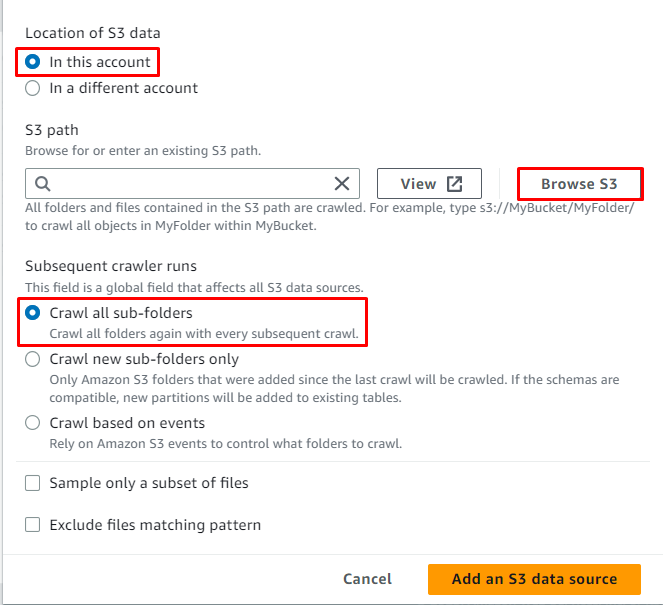
データが入っているフォルダーを選択し、「」をクリックします。 選ぶ ' ボタン:

S3 パスが選択されました。「」をクリックします。 S3 データソースを追加する ' ボタン:

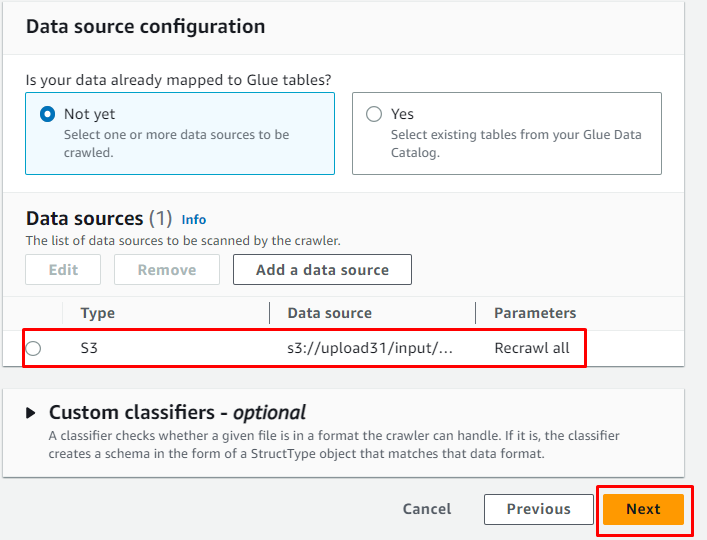
データソースが追加されたら、「」をクリックするだけです。 次 ' ボタン:
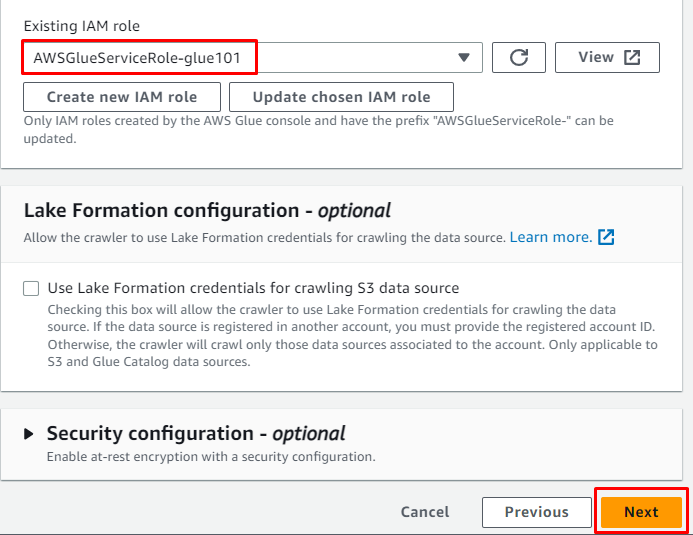
IAM ロールを追加し、「」をクリックします。 次 ' ボタン:
前に作成したターゲット データベースを入力し、テーブルの名前を入力します。
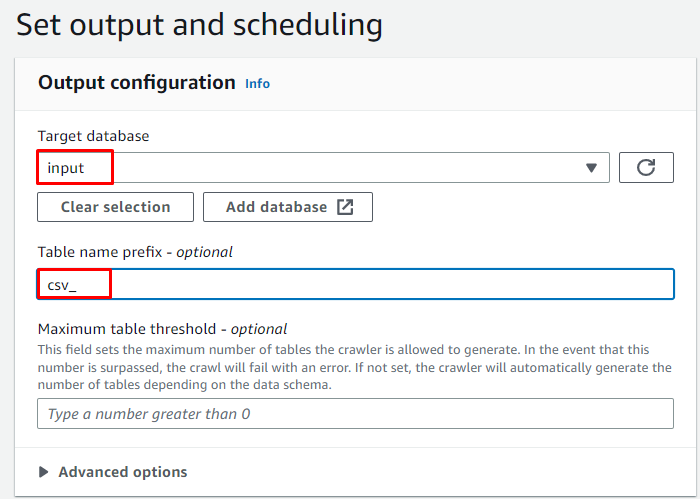
クローラーのオンデマンド スケジュールを選択し、「」をクリックします。 次 ' ボタン:
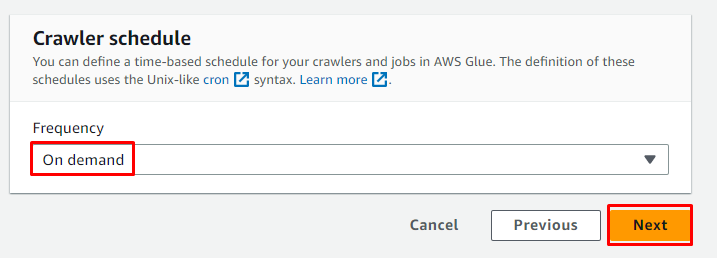
クローラーを確認し、「」をクリックします。 クローラーの作成 ' ボタン:
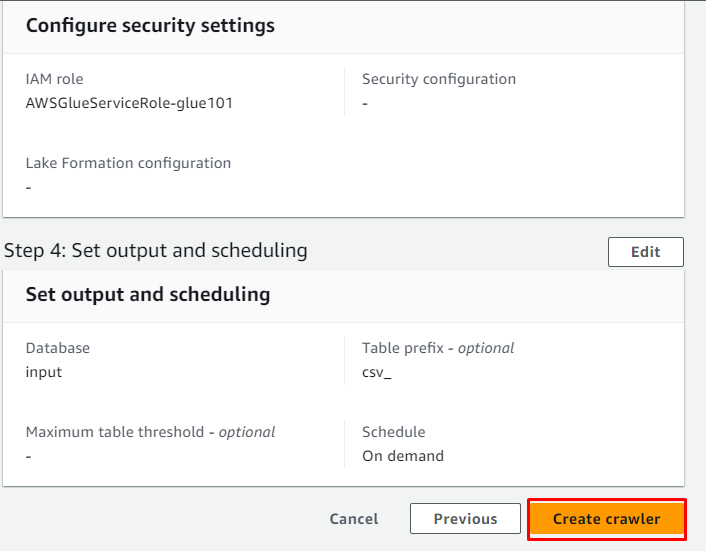
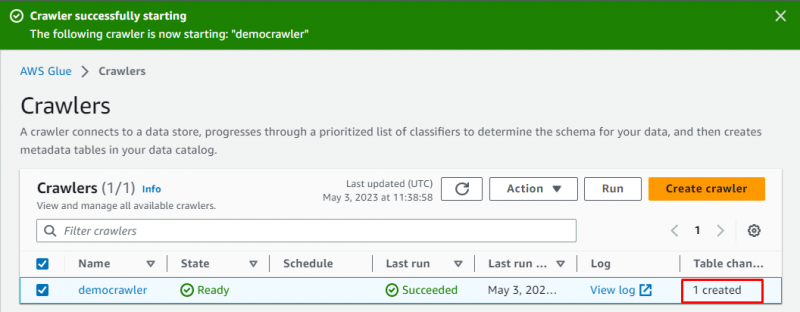
クローラーが正常に作成されました。「」をクリックします。 走る 」ボタンを選択した後、次のようにします。

クローラーの実行には少し時間がかかり、データがフェッチされ、データを保存するテーブルが作成されます。
「」に向かってください。 テーブル Glue ダッシュボードの「」ページ:
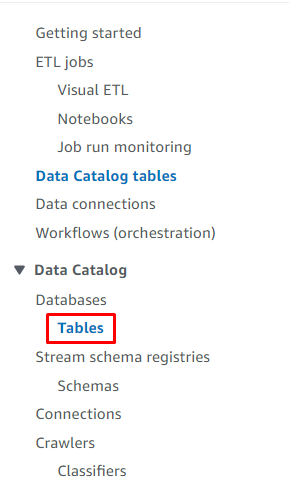
名前をクリックしてテーブルを選択します。
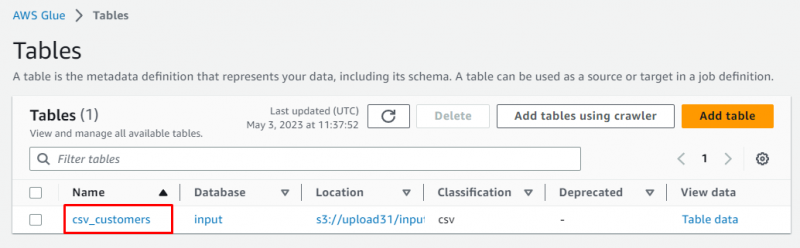
取得したデータのメタデータを含むストーリーの詳細が表示されます。
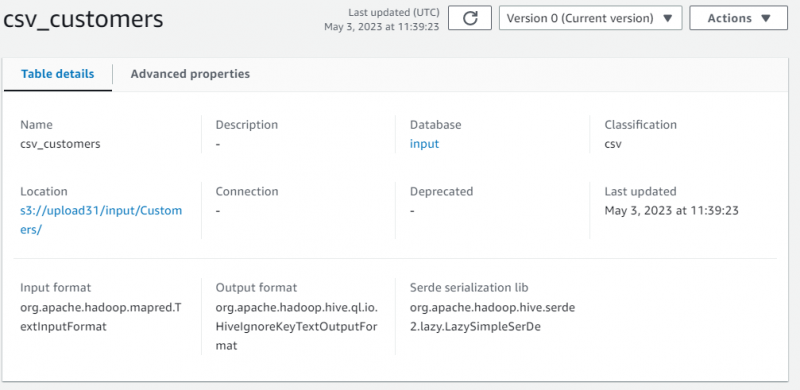
ページを下にスクロールしてセクションを選択し、データを含む表を表示します。
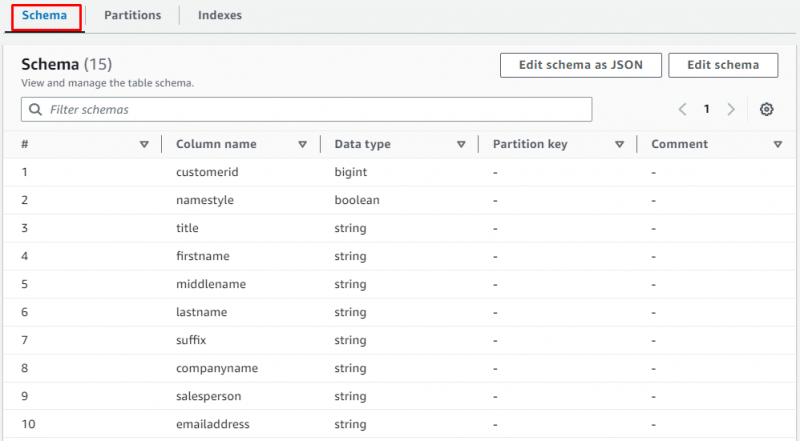
S3 バケットからデータをフェッチするクローラーの作成についてはこれですべてです。
結論
S3 バケットからデータをフェッチするクローラを作成するには、クロールされたデータが保存されるデータベースを AWS Glue 上に作成します。データのソース (S3 バケット) とターゲット データベースを指定して、Glue ダッシュボードからクローラーを構成します。このガイドで詳しく説明されているように、クローラーを実行し、S3 バケットからデータベース テーブルにデータをフェッチします。