指定されたデータセットが 1 つの CSV ファイルにない場合があります。それらはすべて異なる Excel シートにあります。複数のデータセットではなく、単一のデータセットに対してすべての計算アクティビティまたは前処理アクティビティを実行する方が望ましいことは既にご存じでしょう。前処理タスクに費やす必要がある時間を削減または節約します。また、データ アナリストやデータ サイエンティストは、利用可能なデータの分析や調査を開始する前に、多数の CSV ファイルを結合する必要があるため、過負荷になることがよくあります。一方、すべてのファイルが単一または同じデータ ソースから取得され、同じ列/変数名とデータ構造を持つとは限りません。この投稿では、2 つ以上の CSV ファイルを類似または異なる列構造で結合する方法を説明します。
CSV ファイルを結合する理由
データセットは、特定の主題に関連する値または数値のコレクションまたはグループである場合があります。たとえば、特定のクラスの各生徒のテスト結果は、データセットの一例です。データセットはサイズが大きいため、カテゴリごとに個別の CSV ファイルに保存されることがよくあります。たとえば、特定の病気について患者を検査する必要がある場合、性別、医療記録、年齢、病気の重症度など、すべての要素を考慮する必要があります。側面。また、計算または前処理タスクを実行する際は、複数のデータセットではなく、単一のデータセットを操作および管理することをお勧めします。メモリやその他の計算リソースを節約します
Python で CSV ファイルを結合するには?
Python で 2 つ以上の CSV ファイルを結合する方法は複数あります。以下のセクションでは、append()、concat()、および merge() 関数などを使用して、CSV ファイルを pandas データフレームに結合し、データフレームを単一の CSV ファイルに変換します。複数の CSV ファイルを、類似または可変の列構造と組み合わせる方法を説明します。
方法 1: CSV を類似の構造または列と組み合わせる
現在の作業ディレクトリには、「test1」と「test2」の 2 つの CSV ファイルがあります。
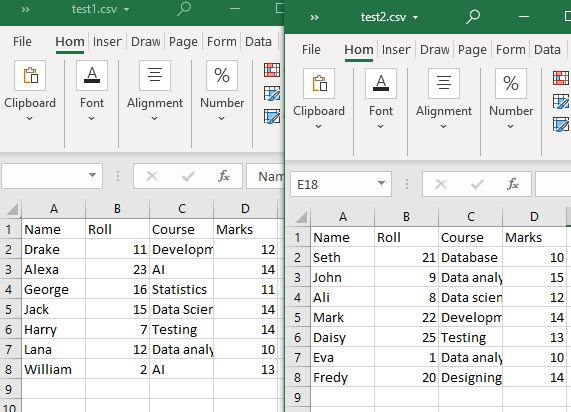
例 # 1: append() 関数の使用
どちらの CSV ファイルも同じ構造です。このメソッドでは glob() 関数を使用して、作業ディレクトリ内の CSV ファイルのみを一覧表示します。次に、「pandas.DataFrame.append()」を使用して CSV ファイルを読み取ります (共通のテーブル構造を持つ)。

出力:
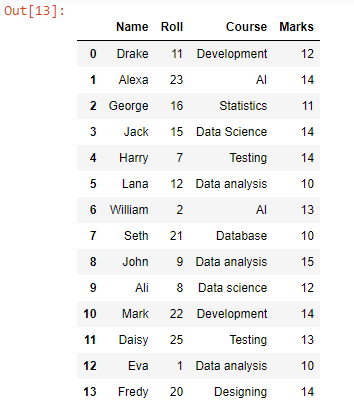
append 関数を使用して、test1.csv のデータ行の下に test2.csv の各データ行を追加または追加しました。ファイルのすべてのデータ行が結合されていることがわかります。このデータフレームを CSV に変換するには、to_csv() 関数を使用できます。

これにより、作業ディレクトリに「test1」と「test2」の CSV ファイルを結合した CSV ファイルが、指定された名前、つまり merged.csv で作成されます。
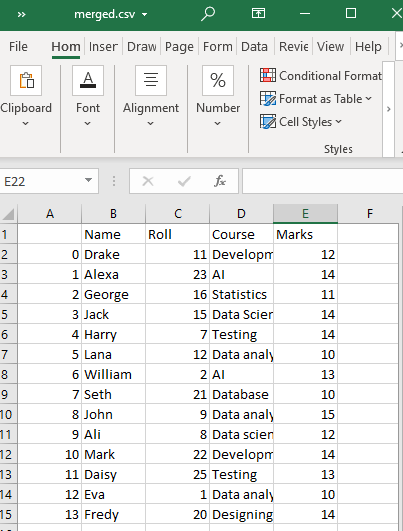
例 2: concat() 関数の使用
最初に pandas モジュールをインポートします。 map メソッドは、pd.read_csv() を使用して、渡された各 CSV ファイルを読み取ります。これらのマッピングされたファイル(CSV ファイル)は、デフォルトで関数 pd.concat() を使用して行軸に沿って結合されます。 CSV ファイルを横方向に結合したい場合は、axis=1 を渡すことができます。 ignore index = True を指定すると、結合されたデータフレームの連続したインデックス値も作成されます。

pd.read_csv() は concat() 関数内に渡され、連結後に CSV ファイルを pandas データフレームに読み込みます。
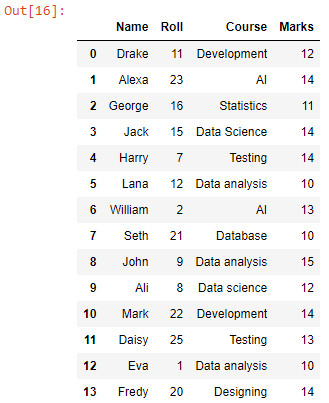
作業ディレクトリ内のすべての CSV ファイルのデータを結合したデータフレームを取得しました。では、CSVファイルに変換してみましょう。
結合された CSV が現在のディレクトリに作成されます。
方法 2: CSV を異なる構造または列と組み合わせる
最初の方法で、同じ列と構造を持つ CSV ファイルを結合することについて説明しました。この方法では、異なる列と構造を持つ CSV ファイルを結合します。
例 # 1: merge() 関数の使用
pandas モジュールの「pandas.merge()」関数は、2 つの CSV ファイルを結合できます。マージとは、単に共有列または属性に基づいて 2 つのデータセットを 1 つのデータセットに結合することを指します。
4 つの異なる結合方法でデータフレームをマージできます。
- インナー
- 右
- 左
- アウター
これらのタイプのマージを実行するには、2 つの CSV ファイルを使用します。
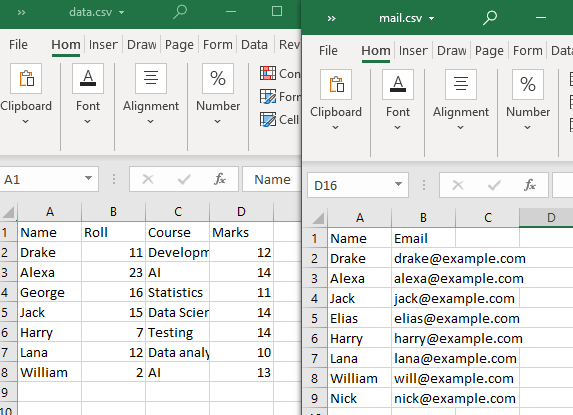
両方の CSV ファイルで少なくとも 1 つの属性または列を共有する必要があることに注意してください。ご覧のとおり、列「名前」とその属性の一部は、両方の CSV ファイルで共有されています。
内部結合を使用したマージ
merge() 関数でパラメーター how='inner' を指定すると、指定された列に従って 2 つのデータフレームが結合され、両方の元のデータフレームで同一または同じ値を持つ行のみを含む新しいデータフレームが提供されます。
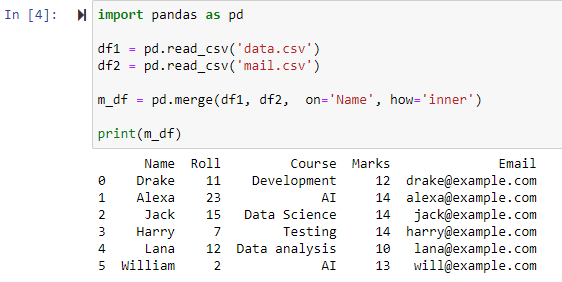
関数が両方の CSV ファイルをマージし、列「名前」の共通属性に基づいて行を返したことがわかります。
右外部結合を使用したマージ
パラメータ how='right' が指定されている場合、パラメータ「on」に指定した列に基づいて両方のデータフレームが結合されます。そして、左側のデータフレームに値が含まれていない行を含む、右側のデータフレームのすべての行を含む新しいデータフレームが返され、左側のデータフレームの列の値が NAN に設定されます。
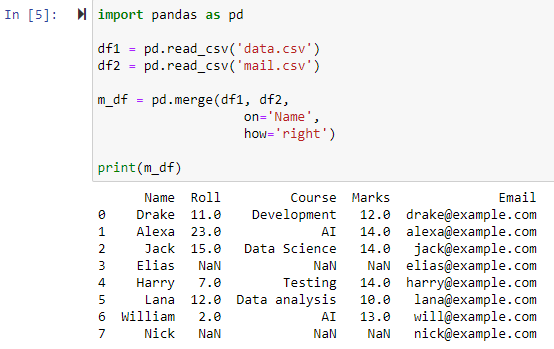
左外部結合を使用したマージ
パラメータが「左」として指定されている場合、「on」パラメータを使用して指定された列に基づいて 2 つのデータフレームが結合され、左のデータフレームのすべての行と NAN を含む行を含む新しいデータフレームが返されます。または右側のデータフレームの値を null にし、右側のデータフレーム列の値を NAN に設定します。
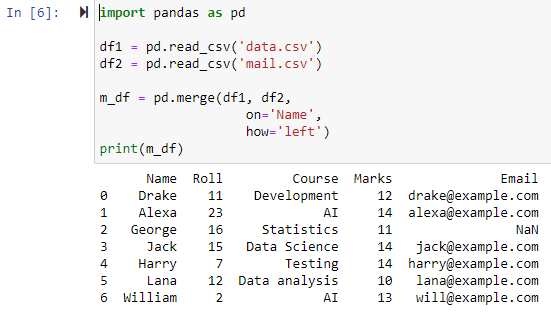
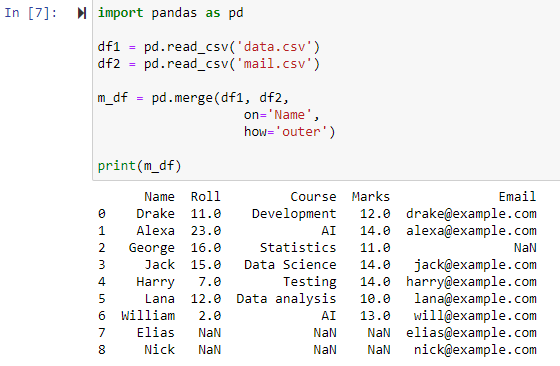
完全外部結合を使用したマージ
how='outer' が指定されている場合、2 つのデータフレームは 'on' パラメータに指定された列に応じて結合され、df1 と df2 の両方のデータフレームからの行を含む新しいデータフレームが返され、すべての行の値として NAN が設定されます。データフレームの 1 つにデータが存在しない場合。
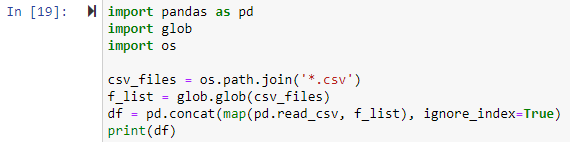
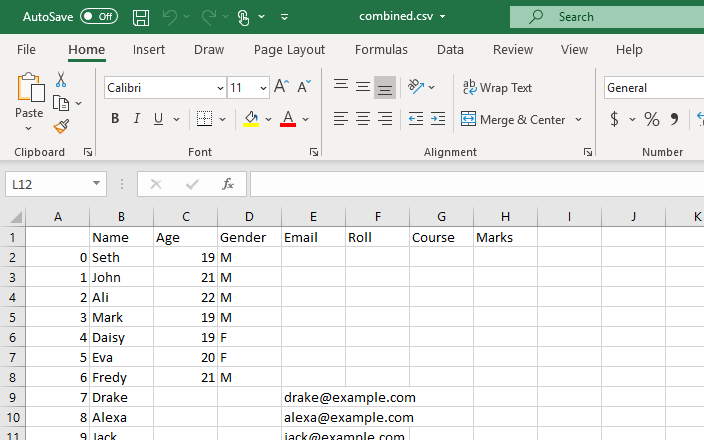
例 2: 作業ディレクトリ内のすべての CSV ファイルを結合する
この方法では、glob モジュールを使用して、すべての .csv ファイルを pandas DataFrame に結合します。すべてのライブラリを最初にインポートする必要がありました。次に、結合する各 CSV ファイルのパスを設定します。ファイル パスは、次の例の os.path.join() 関数の最初の引数であり、2 番目の引数は、結合するパス コンポーネントまたは .csv ファイルのいずれかです。ここで、「*.csv」という表現は、.csv ファイル拡張子で終わる作業ディレクトリ内の各ファイルを検索して返します。 glob.glob(結合されたファイル) 関数は、結合されたファイルの名前のリストを入力として受け入れ、結合/結合されたすべてのファイルのリストを出力します。
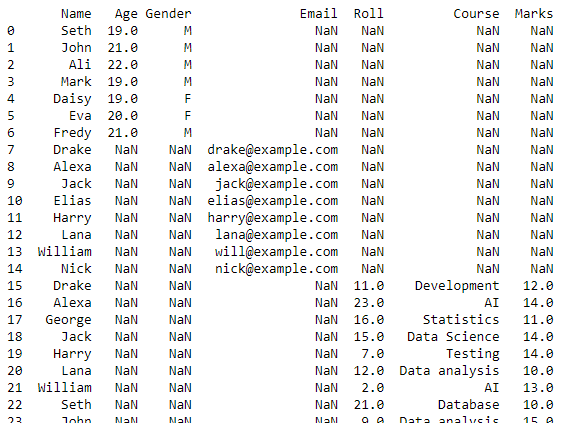
このスクリプトは、作業ディレクトリ内のすべての CSV ファイルのデータを組み合わせたデータフレームを返します。
このデータフレームは CSV ファイルに変換され、この変換には to_csv() 関数が使用されます。この新しい CSV ファイルは、現在の作業ディレクトリに格納されているすべての CSV ファイルから作成された結合 CSV ファイルになります。
結論
この投稿では、CSV ファイルを結合する必要がある理由について説明しました。 Python で 2 つ以上の CSV ファイルを結合する方法について説明しました。このチュートリアルは 2 つのセクションに分かれています。最初のセクションでは、append() 関数と concat() 関数を使用して、同じ構造または列名の CSV ファイルを結合する方法を説明しました。 2 番目のセクションでは、異なる列と構造の CSV ファイルを結合するために、merge() メソッド、os.path.join()、および glob メソッドを使用しました。