「pandas」はpython環境向けの高性能ツールです。これは、データ分析用の「オープン」ソース コードです。 pandas join および pandas merge メソッドは、2 つのデータフレームを結合して 1 つのデータフレームにするために使用されます。パンダの両方の方法の違いは、パンダの「結合」関数がインデックスを使用してデータフレームを結合することです。パンダの「マージ」機能は、インデックスと必要な列を自分で選択できる列メソッドを使用してデータフレームを結合します。 pandas の join メソッドと比較して、pandas の merge メソッドが主に使用されます。実装に使用するソフトウェアは「spyder」ソフトウェアです。これは、pandas join method() および pandas merge() メソッド関数のコード実装に利点を提供する Python 環境にあります。
Pandas Join() メソッドの構文
「df1. 加入 ( df2 ) 」上記構文の「df」は「dataframe」の略です。メソッドを呼び出すための「ドット結合」関数を使用した構文には、2 つのデータフレームがあります。 2 つのデータフレームを結合する pandas メソッドです。インデックスを使用してデータフレームを 1 つに結合することで機能します。
Pandas Merge() メソッドの構文
「df1. マージ ( df2 、 の上 = 「列名」 ) 」pandas のマージ メソッドの構文には、「df1」と「df2」の 2 つのデータフレームがあります。 「ドットマージ」機能は、列の外観を反転させて両方のデータフレームを結合する方法を呼び出しています。
panda merge と pandas join のメソッドを使用するために、2 つのデータフレームを結合する次の方法について説明します。
- Pandas Join メソッドが重複しています。
- パンダは、インデックスのリセットを使用してメソッドに参加します。
- パンダのマージ方法(列「左右」)。
- パンダのマージ方法が明示的です。
Pandas Merge および Pandas Join メソッドの実装のためのデータフレームの作成
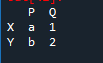
まず、データフレームを作成する必要があります。そのために、「スパイダー」ツールを使用します。それを開いた後、コードを書き始めます。パンダ ライブラリ アソシエーションの「pd」としてパンダをインポートします。データフレーム変数は、対応する「x」、「y」、「p」、および「q」であり、「a」は値が「1」、「b」は値が「2」として割り当てられています。

出力は、割り当てられた値で作成された「df」です。データと同じくらい大きくすることができます。
別のデータフレームの作成
パンダの結合とパンダのマージの方法を明確に理解するために、別のデータフレームを作成する必要があります。ここでは、上記の「df」と同じように「df」を作成していますが、変数に代入される値が異なるだけです。 「h」、「j」、「s」、「d」があり、値「b」に値「8」、「Y」に値「3」を割り当てます。

出力は、作成された単純な「df」を示しています。

例 # 01: Pandas Join メソッド (重複)
次に、pandas join メソッドを使用して 2 つのデータフレームを結合する方法を見ていきます。この方法では、データフレームから作業したい列を選択できます。 「df」の列「左」が重複している例を取り上げたので、データの重複を克服するために「接尾辞」でこれを修正できます。ここで使用する変数は、「x」、「z」、「v」、「d」です。 「p」、「o」、「l」、および「y」に、値が「3」、「6」、「7」、および「9」として割り当てられます。 「.join」は、右の「df」接尾辞を持つ左結合に設定された整列でメソッドを呼び出します。 」。コードで使用されている「接尾辞」は、データフレームに同じ名前の「キー」を持つ 2 つの列があり、データと重複しないためです。
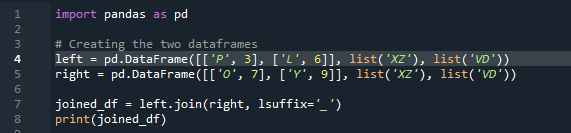
pandas join メソッドを使用して 2 つの「df」を結合する方法で、出力に重複データは表示されません。
例 # 02: インデックス リセットを使用した Pandas Join メソッド
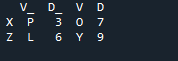
この例では、2 つのデータフレームを結合するのに役立つメソッド join で「キー」として使用するパラメーター「on」を持つ列を個別に指定します。組み合わせることは、このパラメーターで行われます。また、それらを結合するには、2 つの「df」のうちの 1 つのインデックスが類似している必要があります。類似した種類のデータまたは同じ目的で使用されるデータをまとめて処理することができます。これは、右から使用して、引き続きインデックスを使用します。変数は、「s」、「t」、「u」、「v」、「n」、「w」、「k」、および「q」です。割り当てられる値は、「3」、「6」、「7」、および「9」です。 「ドットインデックスのリセット」は、「df」のインデックスをリセットする pandas のメソッドです。リセット インデックスは、データフレーム データが長くなるまで、データフレーム リストのすべての整数を 0 から設定します。
これは、パンダのインデックス「キー」結合方法で表示される出力です。
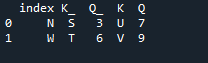
例 # 03: Pandas Merge メソッド (列「左と右」)
merge メソッドは、パンダの join メソッドと同様の操作を実行します。どちらの方法も、同様のデータフレームでデータを結合するためのものです。マージ方法は、キーを指定する必要があるため、より用途が広いです。データフレームの作業に応じて、左右の列で指定することもできます。コード内の変数は、「s」、「d」、「g」、「f」、「k」、「j」、「b」、および「q」です。割り当てられる値は、「9」、「5」、「6」、および「7」です。外部の「結合」実装は、pandas マージ メソッド関数のパラメーター「how」を使用して、両方の「df」で行われます。
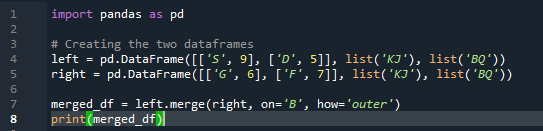
表示される出力は、2 つのデータフレームのマージされたデータを示しています。 「NaN」は「数字ではない」を表します。つまり、データに数字が割り当てられていない場合、「NaN」はそこにあることを示します。
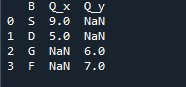
例 # 04: Merge メソッドを明示的に
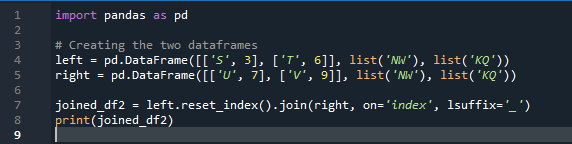
ここで、この例では、マージ方法はインデックスの破棄であり、データフレームにはインデックス値が想定されていません。明示的な指定がフォローアップされる場合、実行する必要がある作業に従ってこのメソッドを実行します。左インデックスまたは右インデックスに基づいてデータをパラメーターとマージします。このデータフレームの変数は、「t」、「r」、「I」、「u」、「h」、「o」、「e」、および「e」です。割り当てられる値は、「2」、「4」、「6」、および「4」です。必要に応じて列を選択する pandas マージ メソッドの上記の例は、2 つのデータフレームを結合する最も見栄えがよく、価値のある方法です。コード行の最後で、マージ キーがデータセット内で一意であることを確認します。
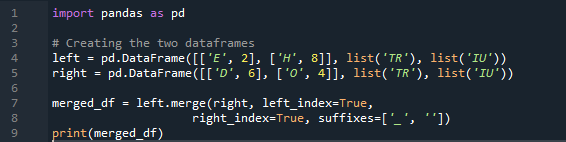
以下の出力では、インデックスなしではインデックスが表示されませんが、関数は左右のインデックスに基づいて実行されます。
結論
merge() メソッドと join() メソッドはどちらも非常に便利で効果的なメソッドです。これらの関数は両方とも、同じデータフレーム上の 2 つの別個のデータフレームを結合するために使用されますが、場合によって使用方法が異なります。この記事では、pandas の結合方法とマージ方法の主な違いを学びました。例を実行し、pandas 結合方法を理解した後、より柔軟でデータベース スタイルの結合が必要な場合は、pandas マージ方法を使用することが望ましいという知識で結論付けます。一方、データフレームをインデックスと広範囲に結合したい場合は、パンダの join() メソッド関数を使用できます。