パンダは NaN 値を埋めます
データ フレーム内の列に NaN または None 値がある場合、「fillna()」または「replace()」関数を使用してそれらをゼロ (0) で埋めることができます。
塗りつぶし()
NA/NaN 値は、「fillna()」関数を使用して提供されたアプローチで埋められます。次の構文を考慮することで利用できます。
1 つの列に NaN 値を入力する場合、構文は次のようになります。

完全な DataFrame の NaN 値を入力する必要がある場合、構文は次のとおりです。

交換()
NaN 値の 1 つの列を置き換えるために提供される構文は次のとおりです。

一方、DataFrame の NaN 値全体を置き換えるには、次の構文を使用する必要があります。

この記事では、Pandas DataFrame で NaN 値を埋めるために、これらの両方のメソッドの実用的な実装を調べて学習します。
例 1: Pandas の「Fillna()」メソッドを使用して NaN 値を埋める
この図は、Pandas の「DataFrame.fillna()」関数を適用して、指定された DataFrame の NaN 値を 0 で埋める方法を示しています。欠損値を 1 つの列に埋めることも、DataFrame 全体に値を埋めることもできます。ここでは、これらの両方の手法について説明します。
これらの戦略を実行するには、プログラムを実行するための適切なプラットフォームを取得する必要があります。そこで、「Spyder」ツールを使用することにしました。 「pandas」ツールキットをプログラムにインポートすることから Python コードを開始しました。これは、Pandas 機能を使用して DataFrame を構築し、その DataFrame の欠損値を埋める必要があるためです。 「pd」は、プログラム全体で「pandas」のエイリアスとして使用されます。
これで、Pandas 機能にアクセスできるようになりました。まず、その「pd.DataFrame()」関数を使用して DataFrame を生成します。このメソッドを呼び出して、3 つの列で初期化しました。これらのコラムのタイトルは「M1」「M2」「M3」です。 「M1」列の値は、「1」、「なし」、「5」、「9」、および「3」です。 「M2」のエントリは、「なし」、「3」、「8」、「4」、および「6」です。 「M3」はデータを「1」、「2」、「3」、「5」、「なし」として保存します。 「pd.DataFrame()」メソッドが呼び出されたときに、この DataFrame を格納できる DataFrame オブジェクトが必要です。 「不足している」DataFrame オブジェクトを作成し、「pd.DataFrame()」関数から取得した結果によって割り当てました。次に、Python の「print()」メソッドを使用して、Python コンソールに DataFrame を表示しました。
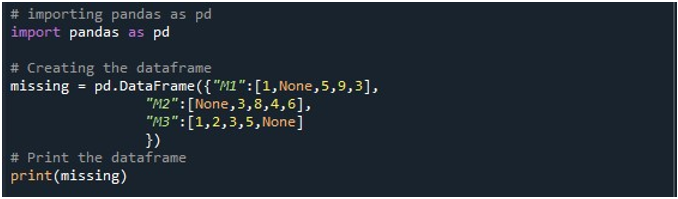
このコードのチャンクを実行すると、3 つの列を持つ DataFrame がターミナルで表示されます。ここでは、3 つの列すべてに null 値が含まれていることがわかります。
Pandas の「fillna()」関数を適用して欠損値を 0 で埋めるために、いくつかの null 値を持つ DataFrame を作成しました。それを行う方法を学びましょう。
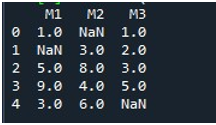
DataFrame を表示した後、Pandas の「fillna()」関数を呼び出しました。ここでは、欠損値を 1 つの列に埋める方法を学習します。この構文は、チュートリアルの冒頭で既に説明されています。 DataFrame の名前を指定し、特定の列のタイトルを「.fillna()」関数で指定しました。このメソッドの括弧の間に、null の場所に配置される値を指定しました。 DataFrame 名は「missing」で、ここで選択した列は「M2」です。 「fillna()」のカッコ内の値は「0」です。最後に、「print()」関数を呼び出して、更新された DataFrame を表示しました。

ここでは、NaN 値が 0 で埋められているため、DataFrame の「M2」列に欠損値が保持されていないことがわかります。
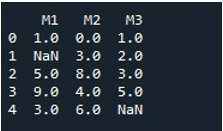
同じメソッドで DataFrame 全体の NaN 値を埋めるために、「fillna()」を呼び出しました。これは非常に簡単です。 「fillna()」関数で DataFrame 名を指定し、括弧の間に関数値「0」を割り当てました。最後に、「print()」関数によって、塗りつぶされた DataFrame が表示されました。

これにより、すべての値が 0 で補充されるため、NaN 値のない DataFrame が得られます。
例 2: Pandas の「Replace()」メソッドを使用して NaN 値を埋める
記事のこの部分では、DataFrame に NaN 値を入力する別の方法を示します。 Pandas の「replace()」関数を使用して、単一の列と完全な DataFrame に値を入力します。
「Spyder」ツールでコードを書き始めます。まず、必要なライブラリをインポートしました。ここでは、Pandas ライブラリをロードして、Python プログラムが Pandas メソッドを使用できるようにしました。ロードした 2 番目のライブラリは NumPy で、「np」にエイリアスします。 NumPy は「replace()」メソッドで不足しているデータを処理します。
次に、「ねじ」、「釘」、「ドリル」の 3 つの列を持つ DataFrame を生成しました。各列の値はそれぞれ与えられます。 「ねじ」列には、「112」、「234」、「なし」、および「650」の値があります。 「爪」の欄には、「123」「145」「なし」「711」があります。最後に、「ドリル」列には「312」、「なし」、「500」、および「なし」の値があります。 DataFrame は「tool」DataFrame オブジェクトに格納され、「print()」メソッドを使用して表示されます。
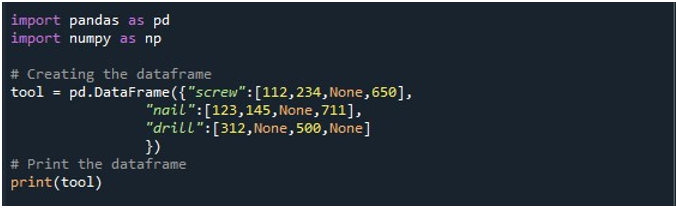
レコードに 4 つの NaN 値を持つ DataFrame は、次の出力画像で確認できます。
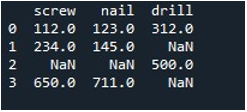
ここで、Pandas の「replace()」メソッドを使用して、DataFrame の 1 つの列に null 値を入力します。このタスクでは、「replace()」関数を呼び出しました。 DataFrame の名前「tool」と列「screw」を「.replace()」メソッドで指定しました。中かっこの間に、DataFrame の「np.nan」エントリの値「0」を設定します。 「print()」メソッドを使用して、出力を表示します。

結果の DataFrame は、「スクリュー」列の NaN エントリが 0 に置き換えられた最初の列を示しています。
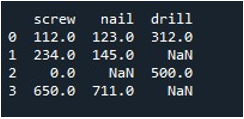
ここで、DataFrame 全体に値を入力する方法を学習します。 「replace()」メソッドを DataFrame の名前で呼び出し、np.nan エントリで置き換えたい値を提供しました。最後に、更新された DataFrame を「print()」関数で出力しました。

これにより、レコードが欠落していない結果の DataFrame が得られます。
結論
DataFrame で不足しているエントリを処理することは基本であり、複雑さを軽減し、データ分析プロセスでデータを挑戦的に処理するために必要な要件です。 Pandas は、この問題に対処するためのいくつかのオプションを提供します。このガイドでは、2 つの便利な戦略を取り上げました。 「Spyder」ツールを使用して両方の手法を実践し、サンプルコードを実行して、物事を少し理解しやすくします。これらの機能の知識を得ることで、Pandas のスキルを磨くことができます。