グループ集計は MongoDB でどのように機能しますか?
$group 演算子を使用して、指定された _id 式に従って入力ドキュメントをグループ化する必要があります。次に、個別のグループごとに合計値を含む単一のドキュメントを返す必要があります。実装を開始するために、MongoDB に「Books」コレクションを作成しました。 「Books」コレクションの作成後、さまざまなフィールドに関連付けられたドキュメントを挿入しました。ドキュメントは、実行されるクエリが以下に示されているように、insertMany() メソッドを介してコレクションに挿入されます。
>db.Books.insertMany([{
_id:1,
タイトル:「アンナ・カレーニナ」
価格: 290,
年: 1879,
order_status: '在庫あり',
著者: {
「名前」:「レオ・トルストイ」
}
}、
{
_id:2,
タイトル:「モッキンバードを殺すために」、
価格: 500,
年: 1960、
order_status: '在庫切れ',
著者: {
「名前」:「ハーパー・リー」
}
}、
{
_id:3,
タイトル:「見えない男」
価格: 312,
年: 1953,
order_status: '在庫あり',
著者: {
「名前」:「ラルフ・エリソン」
}
}、
{
_id:4,
タイトル:「最愛の人」
価格: 370,
年: 1873年、
order_status: 'out_of_stock',
著者: {
「名前」:「トニ・モリソン」
}
}、
{
_id:5,
タイトル:「物事はバラバラになる」、
価格: 200,
年: 1958年、
order_status: '在庫あり',
著者: {
「名前」:「チヌア・アチェベ」
}
}、
{
_id:6,
タイトル:「色の紫」、
価格: 510,
年: 1982、
order_status: '在庫切れ',
著者: {
「名前」:「アリス・ウォーカー」
}
}
]))
出力が「true」と認識されるため、ドキュメントはエラーに遭遇することなく「Books」コレクションに正常に保存されます。ここで、「Books」コレクションのこれらのドキュメントを使用して、「$group」集計を実行します。

例 # 1: $group 集計の使用
$group 集計の簡単な使用法を次に示します。集約クエリは、最初に '$group' 演算子を入力し、次に '$group' 演算子がさらに式を取得して、グループ化されたドキュメントを生成します。
>db.Books.aggregate([
{ $group:{ _id:'$author.name'} }
]))
上記の $group 演算子のクエリは、「_id」フィールドで指定され、すべての入力ドキュメントの合計値を計算します。次に、「_id」フィールドには、「_id」フィールドで別のグループを形成する「$author.name」が割り当てられます。累積値を計算しないため、$author.name の個別の値が返されます。 $group 集計クエリを実行すると、次の出力が得られます。 _id フィールドには、author.names の値があります。

例 # 2: $push アキュムレータでの $group 集計の使用
$group 集計の例では、既に上で述べた任意のアキュムレータを使用しています。しかし、アキュムレータは $group 集計で使用できます。アキュムレータ演算子は、「_id」で「グループ化」されたもの以外の入力ドキュメント フィールドで使用されるものです。式のフィールドを配列にプッシュしたい場合、「$group」演算子で「$push」アキュムレータが呼び出されます。この例は、「$group」の「$push」アキュムレータをより明確に理解するのに役立ちます。
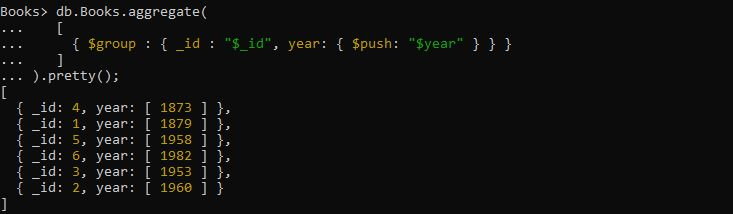
>db.Books.aggregate([
{ $group : { _id : '$_id', year: { $push: '$year' } } }
]
)。可愛い();
ここでは、配列内の特定の書籍の発行年をグループ化します。これを行うには、上記のクエリを適用する必要があります。集計クエリには、「$group」演算子がフィールド式「_id」と「year」フィールド式を取り、$push アキュムレータを使用してグループ年を取得する式が提供されます。この特定のクエリから取得された出力は、年フィールドの配列を作成し、返されたグループ化されたドキュメントをその中に格納します。
例 # 3: 「$min」アキュムレータでの $group 集計の使用
次に、コレクション内のすべてのドキュメントから一致する最小値を取得するために $group 集計で使用される「$min」アキュムレータがあります。 $min アキュムレータのクエリ式を以下に示します。
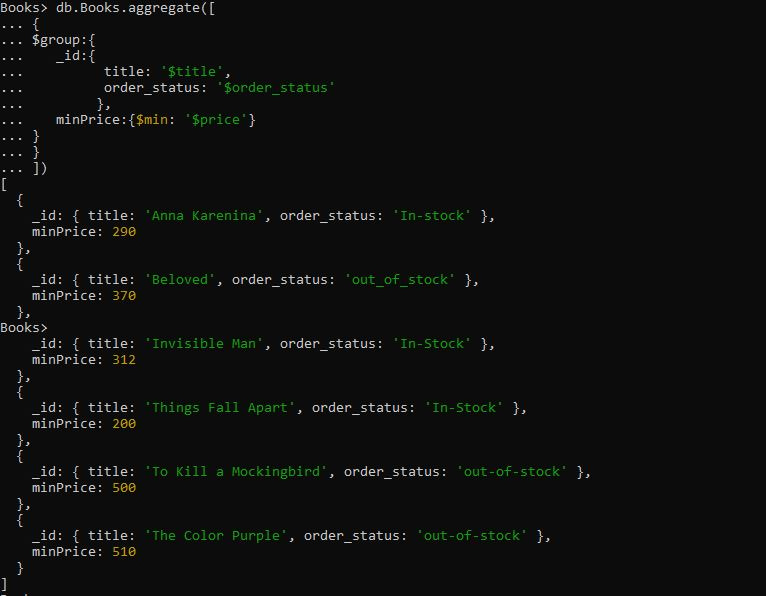
>db.Books.aggregate([{
$グループ:{
_id:{
タイトル: '$タイトル',
order_status: '$order_status'
}、
minPrice:{$min: '$price'}
}
}
]))
クエリには、「title」フィールドと「order_status」フィールドのドキュメントをグループ化した「$group」集計式があります。次に、グループ化されていないフィールドから最低価格値を取得してドキュメントをグループ化する $min アキュムレータを提供しました。以下の $min アキュムレータのクエリを実行すると、タイトルと order_status でグループ化されたドキュメントが順番に返されます。最低価格が最初に表示され、ドキュメントの最高価格が最後に配置されます。
例 # 4: $sum アキュムレータで $group 集計を使用する
$group 演算子を使用してすべての数値フィールドの合計を取得するために、$sum アキュムレータ操作が展開されます。コレクション内の数値以外の値は、このアキュムレータによって考慮されます。さらに、ここでは $group 集計とともに $match 集計を使用しています。 $match 集計は、ドキュメントで指定されたクエリ条件を受け入れ、一致したドキュメントを $group 集計に渡します。$group 集計は、各グループのドキュメントの合計を返します。 $sum アキュムレータのクエリを以下に示します。
>db.Books.aggregate([{ $match:{ order_status:'In-Stock'}},
{ $group:{ _id:'$author.name', totalBooks: { $sum:1 } }
}])
上記の集計のクエリは、ステータスが「在庫あり」で入力として $group に渡されるすべての「order_status」に一致する $match 演算子で始まります。次に、$group 演算子には、在庫にあるすべての書籍の合計を出力する $sum アキュムレータ式があります。 「$sum:1」は、同じグループに属する各ドキュメントに 1 を追加することに注意してください。ここでの出力は、「在庫あり」に関連付けられた「order_status」を持つ 2 つのグループ化されたドキュメントのみを示しています。

例 # 5: $group 集約を $sort 集約と一緒に使用する
ここでの $group 演算子は、グループ化されたドキュメントの並べ替えに使用される「$sort」演算子と共に使用されます。次のクエリには、並べ替え操作の 3 つの手順があります。最初は $match ステージ、次に $group ステージ、最後はグループ化されたドキュメントをソートする $sort ステージです。
>db.Books.aggregate([{ $match:{ order_status:'在庫切れ'}},
{ $group:{ _id:{ authorName :'$author.name'}, totalBooks: { $sum:1} } },
{ $sort:{ authorName:1}}
]))
ここでは、「order_status」が在庫切れである一致したドキュメントを取得しています。次に、一致したドキュメントが $group ステージに入力され、フィールド「authorName」と「totalBooks」でドキュメントがグループ化されます。 $group 式は、「在庫切れ」の書籍の総数に対する $sum アキュムレータに関連付けられています。グループ化されたドキュメントは、$sort 式を使用して昇順で並べ替えられます。ここでの「1」は昇順を示します。指定された順序で並べ替えられたグループ ドキュメントは、次の出力で取得されます。

例 # 6: 個別の値に $group 集計を使用する
集計手順では、$group 演算子を使用してアイテムごとにドキュメントをグループ化し、個別のアイテム値を抽出します。 MongoDB でこのステートメントのクエリ式を考えてみましょう。
>db.Books.aggregate( [ { $group : { _id : '$title' } } ] ).pretty();集計クエリが Books コレクションに適用され、グループ ドキュメントの個別の値が取得されます。ここの $group は、「タイトル」フィールドを入力したので、個別の値を出力する _id 式を取ります。グループ ドキュメントの出力は、_id フィールドに対するタイトル名のグループを持つこのクエリを実行すると取得されます。

結論
このガイドの目的は、MongoDB データベースでドキュメントをグループ化するための $group 集計演算子の概念を明確にすることです。 MongoDB 集計アプローチは、グループ化現象を改善します。 $group 演算子の構文構造は、サンプル プログラムで示されています。 $group 演算子の基本的な例に加えて、この演算子を $push、$min、$sum などのいくつかのアキュムレータ、および $match や $sort などの演算子と共に使用しました。