LangChain は、大規模言語モデルまたは LLM を構築するためのライブラリと依存関係をインポートするために使用できるフレームワークです。言語モデルは、会話のコンテキストを取得するための観察として、メモリを使用してデータまたは履歴をデータベースに保存します。メモリは最新のメッセージを保存するように構成されているため、モデルはユーザーによって与えられたあいまいなプロンプトを理解できます。
このブログでは、LangChain を介して LLMChain でメモリを使用するプロセスについて説明します。
LangChain を通じて LLMChain のメモリを使用するには?
メモリを追加し、LangChain を通じて LLMChain で使用するには、LangChain から ConversationBufferMemory ライブラリをインポートして使用できます。
LangChain を通じて LLMChain のメモリを使用するプロセスを学習するには、次のガイドを参照してください。
ステップ 1: モジュールをインストールする
まず、pip コマンドを使用して LangChain をインストールし、メモリを使用するプロセスを開始します。
pip インストール ラングチェーン
OpenAI モジュールをインストールして、LLM またはチャット モデルを構築するための依存関係またはライブラリを取得します。
pip インストール openai
環境をセットアップする OpenAI の場合は、OS ライブラリと getpass ライブラリをインポートして API キーを使用します。
私たちを輸入してくださいgetpass をインポートする
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API キー:')
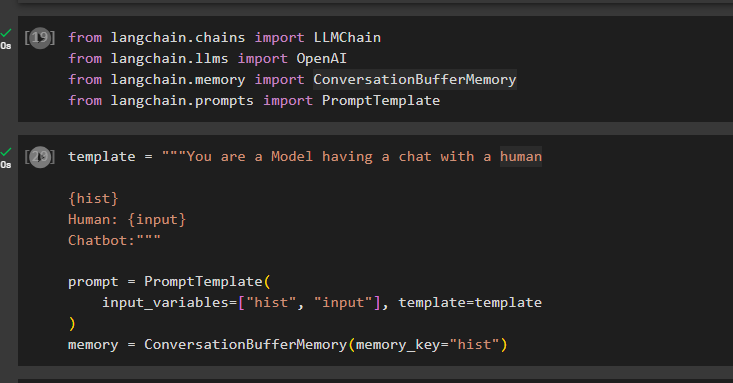
ステップ 2: ライブラリのインポート
環境をセットアップしたら、LangChain から ConversationBufferMemory などのライブラリをインポートするだけです。
langchain.chains から LLMChain をインポートlangchain.llms から OpenAI をインポート
langchain.memory から ConversationBufferMemory をインポート
langchain.prompts から PromptTemplate をインポート
ユーザーからクエリを取得するための「input」やバッファ メモリにデータを保存するための「hist」などの変数を使用して、プロンプトのテンプレートを構成します。
template = '''あなたは人間とチャットするモデルです{履歴}
人間: {入力}
チャットボット:「」
プロンプト = プロンプトテンプレート(
input_variables=['hist', 'input'], template=テンプレート
)
メモリ = ConversationBufferMemory(memory_key='hist')
ステップ 3: LLM の構成
クエリのテンプレートが構築されたら、複数のパラメーターを使用して LLMChain() メソッドを構成します。
llm = OpenAI()llm_chain = LLMChain(
llm=llm、
プロンプト=プロンプト、
冗長=真、
メモリー=記憶、
)
ステップ 4: LLMChain のテスト
その後、入力変数を使用して LLMChain をテストし、ユーザーからのプロンプトをテキスト形式で取得します。
llm_chain.predict(input='こんにちは、友人') 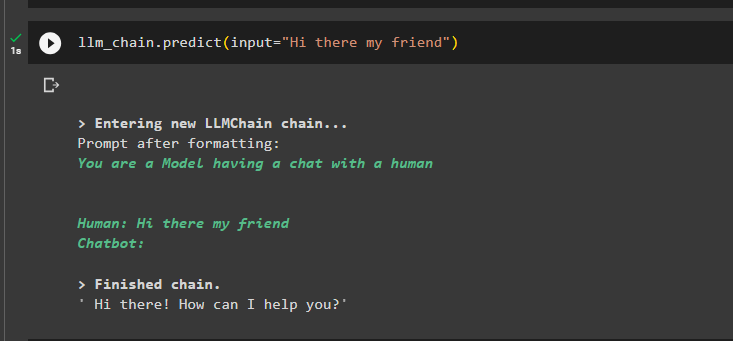
コンテキストを使用して出力を抽出するために、別の入力を使用してメモリに保存されているデータを取得します。
llm_chain.predict(input='良いです! 私は元気です - 調子はどうですか') 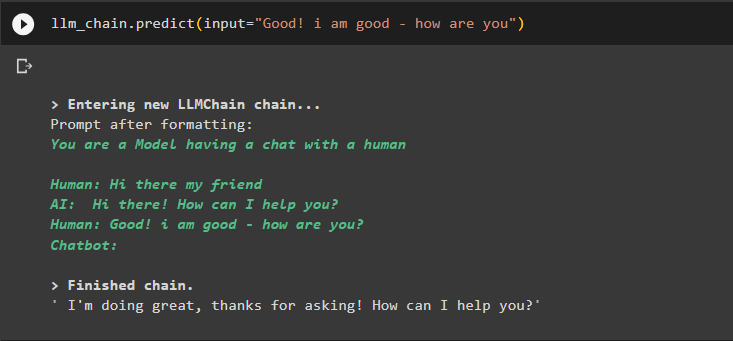
ステップ 5: チャット モデルにメモリを追加する
ライブラリをインポートすることで、チャット モデルベースの LLMChain にメモリを追加できます。
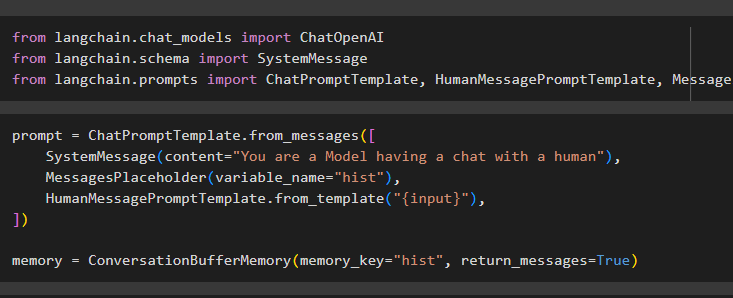
langchain.chat_models から ChatOpenAI をインポートlangchain.schema から SystemMessage をインポート
langchain.prompts から ChatPromptTemplate、HumanMessagePromptTemplate、MessagesPlaceholder をインポート
ConversationBufferMemory() を使用してプロンプト テンプレートを構成し、さまざまな変数を使用してユーザーからの入力を設定します。
プロンプト = ChatPromptTemplate.from_messages([SystemMessage(content='あなたは人間とチャットしているモデルです'),
MessagesPlaceholder(variable_),
HumanMessagePromptTemplate.from_template('{input}'),
])
メモリ = ConversationBufferMemory(memory_key='hist', return_messages=True)
ステップ 6: LLMChain の構成
LLMChain() メソッドをセットアップして、さまざまな引数とパラメーターを使用してモデルを構成します。
llm = ChatOpenAI()chat_llm_chain = LLMChain(
llm=llm、
プロンプト=プロンプト、
冗長=真、
メモリー=記憶、
)
ステップ 7: LLMChain のテスト
最後に、入力を使用して LLMChain をテストするだけで、モデルがプロンプトに従ってテキストを生成できるようになります。
chat_llm_chain.predict(input='こんにちは、友よ') 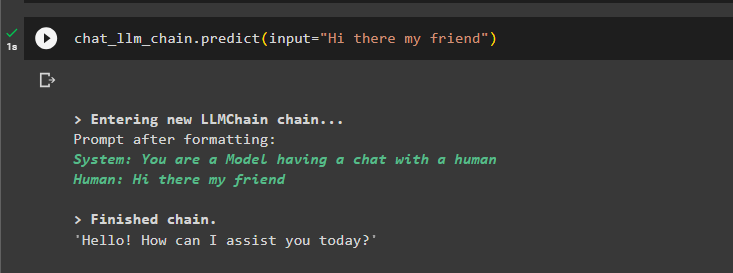
モデルは以前の会話をメモリに保存し、クエリの実際の出力の前にそれを表示します。
llm_chain.predict(input='良いです! 私は元気です - 調子はどうですか') 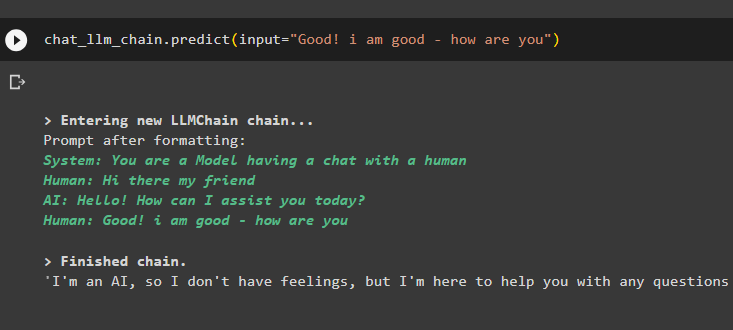
LangChain を使用した LLMChain でのメモリの使用については以上です。
結論
LangChain フレームワークを通じて LLMChain のメモリを使用するには、モジュールをインストールして、モジュールから依存関係を取得する環境をセットアップするだけです。その後、LangChain からライブラリをインポートするだけで、前の会話を保存するためにバッファー メモリが使用されます。ユーザーは、LLMChain を構築し、入力を提供してチェーンをテストすることで、チャット モデルにメモリを追加することもできます。このガイドでは、LangChain を通じて LLMChain のメモリを使用するプロセスについて詳しく説明しました。