概要
この投稿では次のことを説明します。
LangChain のエージェントを使用して MRKL システムをレプリケートする方法
- ステップ 1: フレームワークのインストール
- ステップ 2: OpenAI 環境の設定
- ステップ 3: ライブラリのインポート
- ステップ 4: データベースの構築
- ステップ 5: データベースのアップロード
- ステップ 6: ツールの構成
- ステップ 7: エージェントの構築とテスト
- ステップ 8: MRKL システムを複製する
- ステップ 9: ChatModel の使用
- ステップ 10: MRKL エージェントをテストする
- ステップ 11: MRKL システムを複製する
LangChain のエージェントを使用して MRKL システムをレプリケートするにはどうすればよいですか?
LangChain を使用すると、ユーザーは言語モデルまたはチャットボットの複数のタスクを実行するために使用できるエージェントを構築できます。エージェントは、言語モデルに関連付けられたメモリ内のすべてのステップとともに作業を保存します。これらのテンプレートを使用すると、エージェントは MRKL などのシステムの動作を複製し、再構築することなく最適化された結果を得ることができます。
LangChain のエージェントを使用して MRKL システムをレプリケートするプロセスを学習するには、リストされている手順を実行するだけです。
ステップ 1: フレームワークのインストール
まず、langchain-experimental コマンドで pip を使用して、LangChain 実験モジュールをインストールします。
pip install langchain-experimental
OpenAI モジュールをインストールして、MRKL システムの言語モデルを構築します。
pip インストール openai 
ステップ 2: OpenAI 環境の設定
os および getpass ライブラリをインポートして、ユーザーに OpenAI および SerpAPI アカウントの API キーの提供を求める操作にアクセスします。
輸入 あなた輸入 ゲットパス
あなた 。 約 [ 「OPENAI_API_KEY」 】 = ゲットパス 。 ゲットパス ( 「OpenAI API キー:」 )
あなた 。 約 [ 「SERPAPI_API_KEY」 】 = ゲットパス 。 ゲットパス ( 「Serpapi API キー:」 )
ステップ 3: ライブラリのインポート
LangChain の依存関係を使用して、言語モデル、ツール、エージェントを構築するために必要なライブラリをインポートします。
から ラングチェーン。 鎖 輸入 LLMMathChainから ラングチェーン。 llms 輸入 OpenAI
から ラングチェーン。 公共事業 輸入 SerpAPIラッパー
から ラングチェーン。 公共事業 輸入 SQLデータベース
から langchain_experimental。 SQL 輸入 SQLデータベースチェーン
から ラングチェーン。 エージェント 輸入 エージェントの初期化 、 道具
から ラングチェーン。 エージェント 輸入 エージェントタイプ
ステップ 4: データベースの構築
MRKL は、外部の知識ソースを使用してデータから情報を抽出します。この投稿では SQLite を使用しています。これを使用してダウンロードできます。 ガイド データベースを構築します。次のコマンドは、SQLite のインストールされているバージョンを表示することで、SQLite のダウンロード プロセスを確認します。
スクライト3 
コマンド プロンプトを使用してデータベースを作成するには、ディレクトリ内で次のコマンドを使用します。
CD デスクトップCD マイデータベース
sqlite3 チヌーク。 データベース
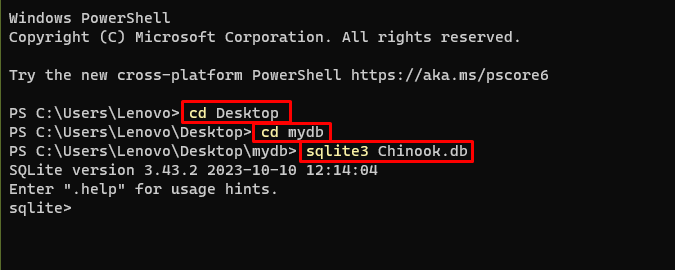
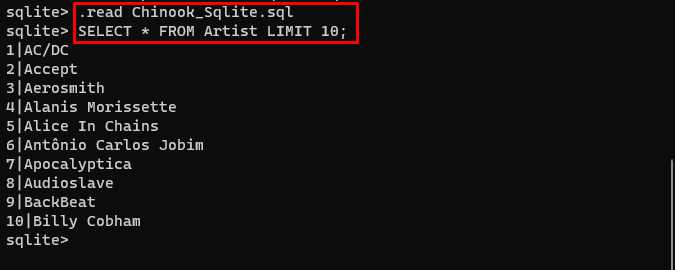
ダウンロード データベース ファイルを作成してディレクトリに保存し、次のコマンドを使用して「 .db ' ファイル:
。 読む Chinook_Sqlite。 SQLアーティスト制限から * を選択 10 ;
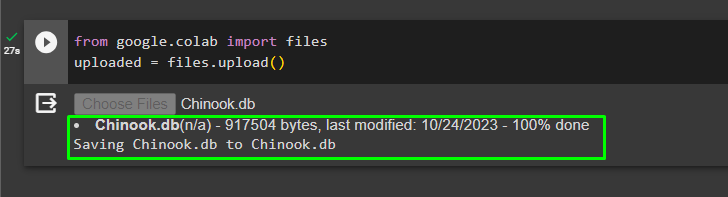
ステップ 5: データベースのアップロード
データベースが正常に作成されたら、Google コラボレーションにファイルをアップロードします。
から グーグル。 他 輸入 ファイルアップロードされた = ファイル。 アップロード ( )
ユーザーは、ノートブック上のアップロードされたファイルにアクセスして、ドロップダウン メニューからそのパスをコピーできます。
ステップ 6: ツールの構成
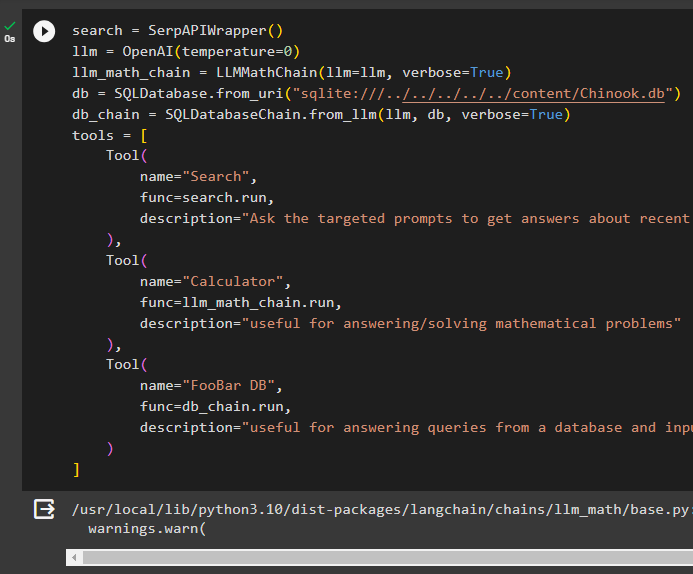
データベースを構築した後、エージェントの言語モデル、ツール、チェーンを構成します。
検索 = SerpAPIラッパー ( )llm = OpenAI ( 温度 = 0 )
llm_math_chain = LLMMathChain ( llm = llm 、 冗長な = 真実 )
データベース = SQLデータベース。 from_uri ( 「sqlite:///../../../../../content/Chinook.db」 )
db_chain = SQLデータベースチェーン。 from_llm ( llm 、 データベース 、 冗長な = 真実 )
ツール = [
道具 (
名前 = '検索' 、
機能 = 検索。 走る 、
説明 = 「ターゲットを絞ったプロンプトに質問して、最近の出来事についての答えを得る」
) 、
道具 (
名前 = '電卓' 、
機能 = llm_math_chain。 走る 、
説明 = 「数学の問題に答える/解くのに役立ちます」
) 、
道具 (
名前 = 「フーバーDB」 、
機能 = db_chain。 走る 、
説明 = 「データベースからのクエリに答えるのに便利で、入力された質問には完全なコンテキストが必要です」
)
】
- を定義します llm を使用した変数 OpenAI() 言語モデルを取得するメソッド。
- の 検索 を呼び出すツールです SerpAPIWrapper() その環境にアクセスするためのメソッド。
- の LLMMathChain() メソッドは、数学の問題に関連する答えを得るために使用されます。
- を定義します データベース 内のファイルのパスを含む変数 SQLデータベース() 方法。
- の SQLDatabaseChain() メソッドを使用してデータベースから情報を取得できます。
- 次のようなツールを定義します 検索 、 電卓 、 そして フーバー DB さまざまなソースからデータを抽出するエージェントを構築する場合:
ステップ 7: エージェントの構築とテスト
ツール、llm、エージェントを使用して MRKL システムを初期化し、ユーザーの質問に対する回答を取得します。
ミスタークル = エージェントの初期化 ( ツール 、 llm 、 エージェント = エージェントタイプ。 ZERO_SHOT_REACT_DESCRIPTION 、 冗長な = 真実 )run() メソッドを使用し、質問を引数として使用して MRKL システムを実行します。
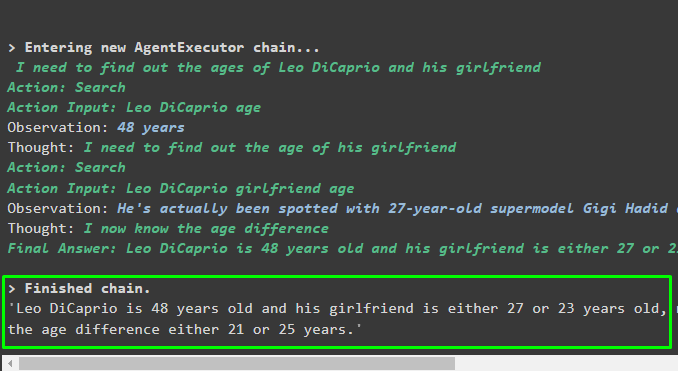
mrkl。 走る ( 「レオ・ディカプリオと彼のガールフレンドの現在の年齢は何歳ですか?彼らの年齢差もわかります」 )出力
エージェントは、システムが最終回答を抽出するために使用する完全なパスを含む最終回答を生成しました。
ステップ 8: MRKL システムを複製する
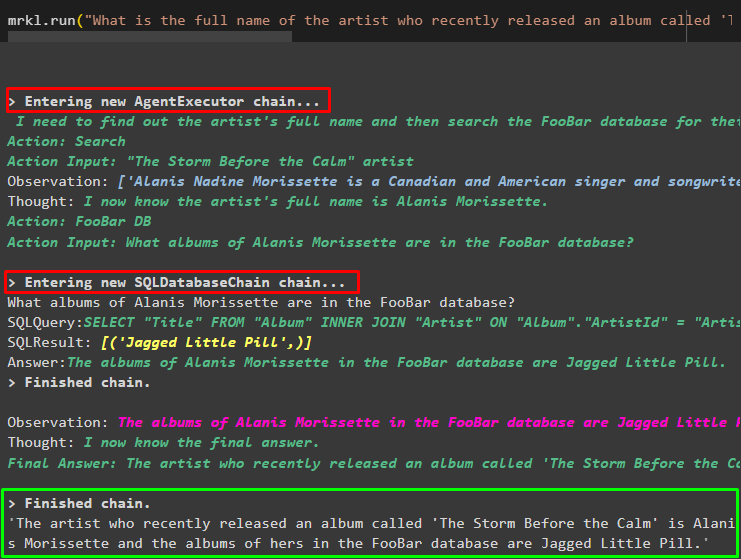
さて、単に使用してください ミスタークル run() メソッドでキーワードを使用して、データベースなどのさまざまなソースから回答を取得します。
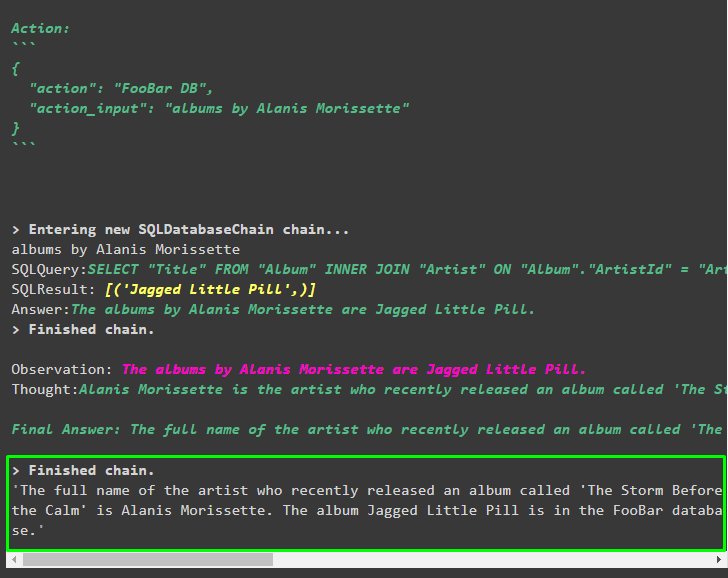
mrkl。 走る ( 「最近リリースされた『The Storm Before the Calm』というアルバムのアーティストのフルネームは何ですか?FooBar データベースにありますか?またデータベースにどのアルバムが登録されていますか?」 )エージェントは質問を自動的に SQL クエリに変換し、データベースから回答を取得します。エージェントは正しいソースを検索して答えを取得し、クエリを組み立てて情報を抽出します。
ステップ 9: ChatModel の使用
ユーザーは、ChatOpenAI() メソッドを使用して言語モデルを簡単に変更して ChatModel にし、それとともに MRKL システムを使用できます。
から ラングチェーン。 チャットモデル 輸入 チャットオープンAI検索 = SerpAPIラッパー ( )
llm = チャットオープンAI ( 温度 = 0 )
llm1 = OpenAI ( 温度 = 0 )
llm_math_chain = LLMMathChain ( llm = llm1 、 冗長な = 真実 )
データベース = SQLデータベース。 from_uri ( 「sqlite:///../../../../../content/Chinook.db」 )
db_chain = SQLデータベースチェーン。 from_llm ( llm1 、 データベース 、 冗長な = 真実 )
ツール = [
道具 (
名前 = '検索' 、
機能 = 検索。 走る 、
説明 = 「ターゲットを絞ったプロンプトに質問して、最近の出来事についての答えを得る」
) 、
道具 (
名前 = '電卓' 、
機能 = llm_math_chain。 走る 、
説明 = 「数学の問題に答える/解くのに役立ちます」
) 、
道具 (
名前 = 「フーバーDB」 、
機能 = db_chain。 走る 、
説明 = 「データベースからのクエリに答えるのに便利で、入力された質問には完全なコンテキストが必要です」
)
】
ステップ 10: MRKL エージェントをテストする
その後、エージェントをビルドし、initialize_agent() メソッドを使用して mrkl 変数で初期化します。 tools、llm、agent、verbose などのコンポーネントを統合するメソッドのパラメーターを追加して、出力に完全なプロセスを取得します。
ミスタークル = エージェントの初期化 ( ツール 、 llm 、 エージェント = エージェントタイプ。 CHAT_ZERO_SHOT_REACT_DESCRIPTION 、 冗長な = 真実 )次のスクリーンショットに示すように、mrkl システムを実行して質問を実行します。
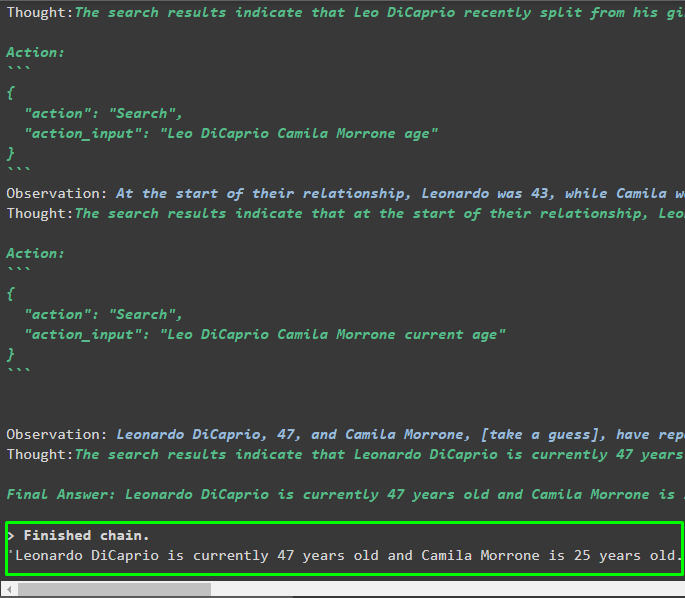
mrkl。 走る ( 「レオ・ディカプリオの彼女は誰ですか?現在の年齢は何歳ですか?」 ) 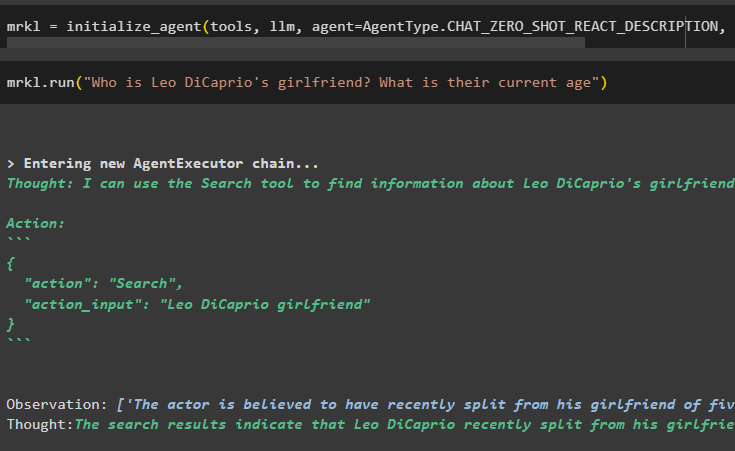
出力
次のスニペットは、エージェントによって抽出された最終的な回答を示しています。
ステップ 11: MRKL システムを複製する
MRKL システムを使用するには、自然言語の質問を指定して run() メソッドを呼び出し、データベースから情報を抽出します。
mrkl。 走る ( 「最近リリースされた『The Storm Before the Calm』というアルバムのアーティストのフルネームは何ですか?FooBar データベースにありますか?またデータベースにどのアルバムが登録されていますか?」 )出力
次のスクリーンショットに示すように、エージェントはデータベースから抽出された最終回答を表示しました。
LangChain のエージェントを使用して MRKL システムを複製するプロセスは以上です。
結論
LangChain のエージェントを使用して MRKL システムを複製するには、モジュールをインストールして、ライブラリをインポートするための依存関係を取得します。ライブラリは、ツールを使用して複数のソースから回答を取得するための言語モデルまたはチャット モデルを構築するために必要です。エージェントは、インターネット、データベースなどのさまざまなソースから出力を抽出するツールを使用するように構成されています。このガイドでは、LangChain のエージェントを使用して MRKL システムを複製するプロセスについて詳しく説明しました。