概要
この投稿では次のことを説明します。
- LangChain の OpenAI Functions エージェントにメモリを追加する方法
- ステップ 1: フレームワークのインストール
- ステップ 2: 環境のセットアップ
- ステップ 3: ライブラリのインポート
- ステップ 4: データベースの構築
- ステップ 5: データベースのアップロード
- ステップ 6: 言語モデルの構成
- ステップ 7: メモリの追加
- ステップ 8: エージェントの初期化
- ステップ 9: エージェントのテスト
- 結論
LangChain の OpenAI Functions エージェントにメモリを追加するにはどうすればよいですか?
OpenAI は 2015 年に設立された人工知能 (AI) 組織で、当初は非営利団体でした。 AIによる自然言語処理(NLP)がチャットボットや言語モデルでブームとなっていることから、マイクロソフトは2020年以来巨額の財産を投資してきた。
OpenAI エージェントを構築すると、開発者はインターネットからより読みやすく要点を絞った結果を取得できるようになります。エージェントにメモリを追加すると、エージェントはチャットのコンテキストをよりよく理解できるようになり、以前の会話もメモリに保存できるようになります。 LangChain の OpenAI 関数エージェントにメモリを追加するプロセスを学習するには、次の手順を実行するだけです。
ステップ 1: フレームワークのインストール
まず、LangChain の依存関係を次からインストールします。 「ラングチェーン実験的」 次のコードを使用したフレームワーク:
pip インストール ラングチェーン - 実験的な
をインストールします 「グーグル検索結果」 Google サーバーから検索結果を取得するモジュール:
pip インストール Google - 検索 - 結果 
また、LangChain で言語モデルを構築するために使用できる OpenAI モジュールをインストールします。
pip インストール openai 
ステップ 2: 環境のセットアップ
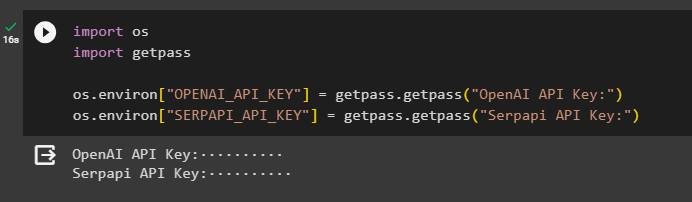
モジュールを取得したら、API キーを使用して環境をセットアップします。 OpenAI そして セルパピ アカウント:
輸入 あなた輸入 ゲットパス
あなた。 約 [ 「OPENAI_API_KEY」 】 = ゲットパス。 ゲットパス ( 「OpenAI API キー:」 )
あなた。 約 [ 「SERPAPI_API_KEY」 】 = ゲットパス。 ゲットパス ( 「Serpapi API キー:」 )
上記のコードを実行して両方の環境にアクセスするための API キーを入力し、Enter キーを押して確認します。
ステップ 3: ライブラリのインポート
セットアップが完了したので、LangChain からインストールされた依存関係を使用して、メモリとエージェントの構築に必要なライブラリをインポートします。
ラングチェーンから。 鎖 輸入 LLMMathChainラングチェーンから。 llms 輸入 OpenAI
#インターネット経由で Google から検索するためのライブラリを取得します
ラングチェーンから。 公共事業 輸入 SerpAPIラッパー
ラングチェーンから。 公共事業 輸入 SQLデータベース
langchain_experimental より。 SQL 輸入 SQLデータベースチェーン
#ツールを構築するためのライブラリを取得 のために エージェントの初期化
ラングチェーンから。 エージェント 輸入 エージェントタイプ 、 道具 、 エージェントの初期化
ラングチェーンから。 チャットモデル 輸入 チャットオープンAI
ステップ 4: データベースの構築
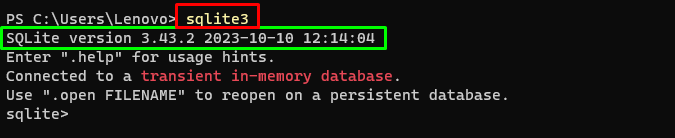
このガイドを進めるには、データベースを構築し、エージェントに接続してそこから回答を抽出する必要があります。データベースを構築するには、これを使用して SQLite をダウンロードする必要があります ガイド 次のコマンドを使用してインストールを確認します。
スクライト3上記のコマンドを実行すると、 Windowsターミナル インストールされている SQLite のバージョンを表示します (3.43.2):
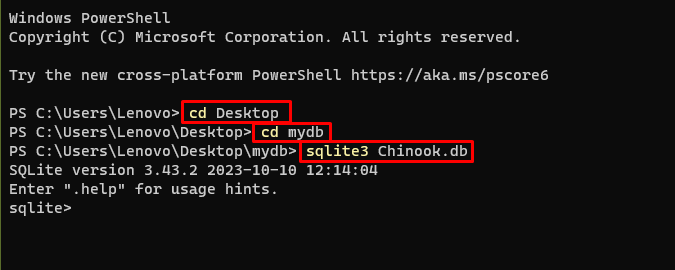
その後、データベースが構築および保存されるコンピューター上のディレクトリに移動するだけです。
cd デスクトップcd mydb
sqlite3 チヌーク。 データベース
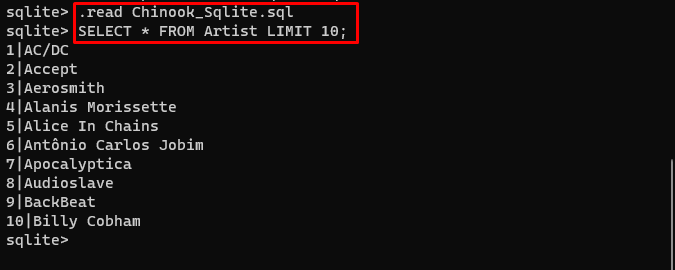
ユーザーはデータベースの内容をここから簡単にダウンロードできます。 リンク ディレクトリに移動し、次のコマンドを実行してデータベースを構築します。
。 読む Chinook_Sqlite。 SQL選択する * アーティストLIMITより 10 ;
データベースが正常に構築されたので、ユーザーはさまざまなクエリを使用してデータベースからデータを検索できます。
ステップ 5: データベースのアップロード
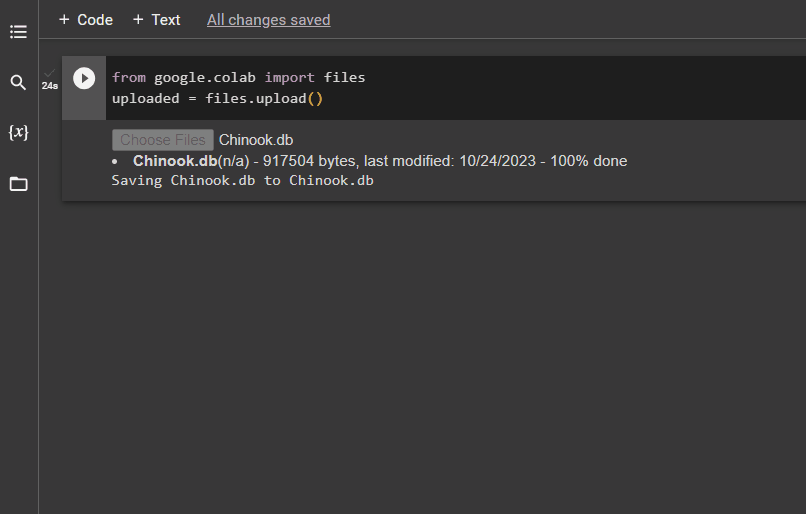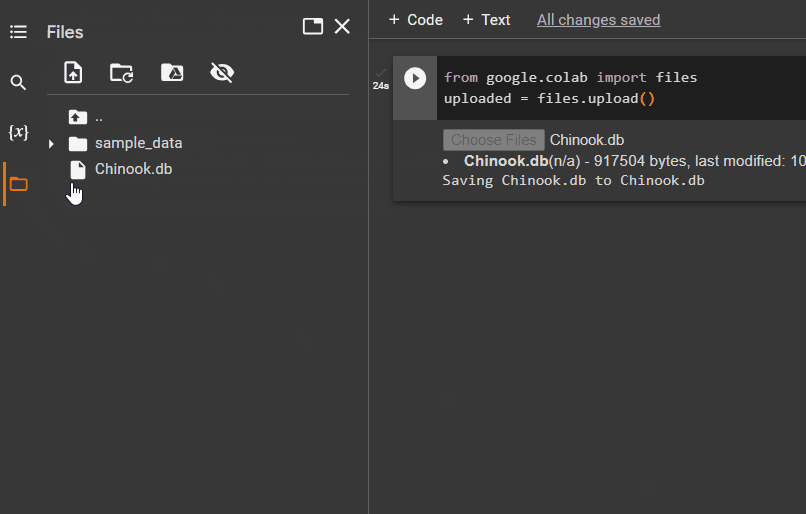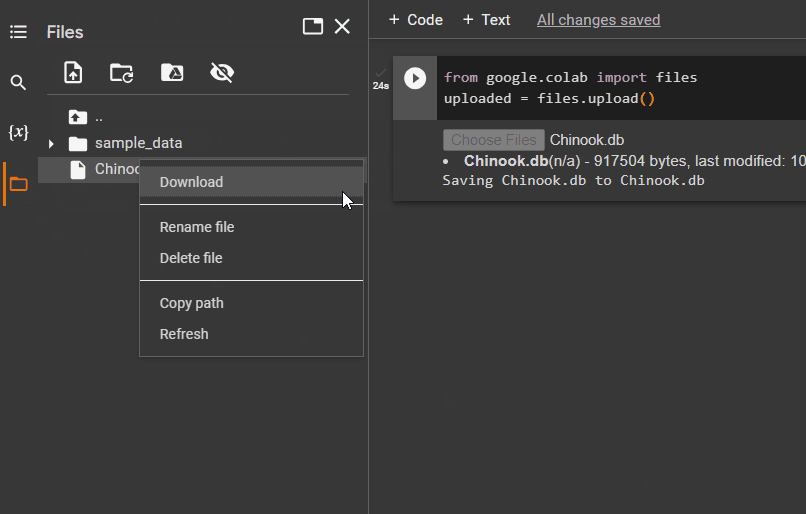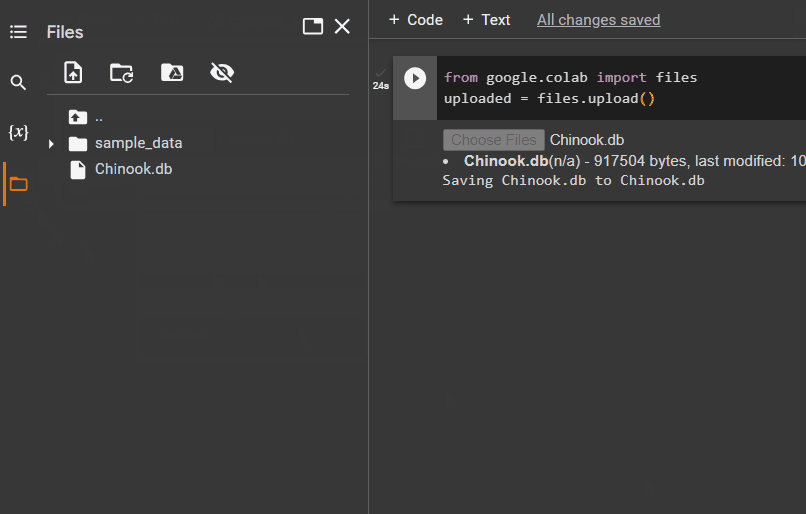
データベースが正常に構築されたら、 「.db」 次のコードを使用して、ファイルを Google Collaboratory に送信します。
グーグルから。 他 輸入 ファイルアップロードされた = ファイル。 アップロード ( )
をクリックしてローカル システムからファイルを選択します。 「ファイルを選択」 上記のコードを実行した後、ボタンをクリックします。
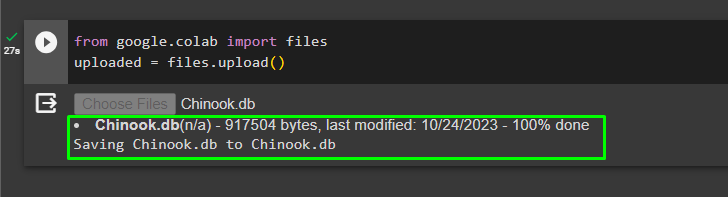
ファイルがアップロードされたら、次のステップで使用するファイルのパスをコピーするだけです。
ステップ 6: 言語モデルの構成
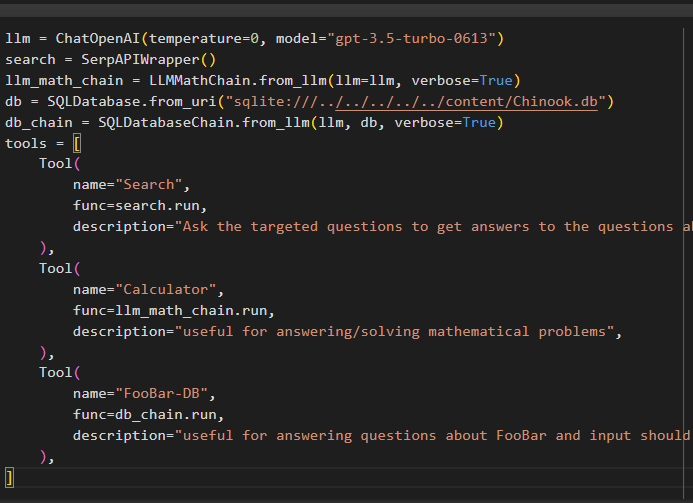
次のコードを使用して、言語モデル、チェーン、ツール、およびチェーンを構築します。
llm = チャットオープンAI ( 温度 = 0 、 モデル = 「gpt-3.5-ターボ-0613」 )検索 = SerpAPIラッパー ( )
llm_math_chain = LLMMathChain。 from_llm ( llm = llm 、 冗長な = 真実 )
データベース = SQLデータベース。 from_uri ( 「sqlite:///../../../../../content/Chinook.db」 )
db_chain = SQLデータベースチェーン。 from_llm ( llm 、 データベース 、 冗長な = 真実 )
ツール = [
道具 (
名前 = '検索' 、
機能 = 検索。 走る 、
説明 = 「最近の出来事に関する質問への答えを得るために、的を絞った質問をする」 、
) 、
道具 (
名前 = '電卓' 、
機能 = llm_math_chain。 走る 、
説明 = 「数学の問題に答える/解くのに役立ちます」 、
) 、
道具 (
名前 = 「FooBar-DB」 、
機能 = db_chain。 走る 、
説明 = 「FooBar に関する質問に答えるのに役立ちます。入力は完全なコンテキストを含む質問の形式である必要があります。」 、
) 、
]
- の llm 変数には、ChatOpenAI() メソッドとモデルの名前を使用した言語モデルの構成が含まれます。
- 検索 変数には、エージェント用のツールを構築するための SerpAPIWrapper() メソッドが含まれています。
- を構築します llm_math_chain LLMMathChain() メソッドを使用して数学ドメインに関連する答えを取得します。
- db 変数には、データベースの内容が含まれるファイルのパスが含まれます。ユーザーは最後の部分のみを変更する必要があります。 「コンテンツ/Chinook.db」 を維持するパスの 「sqlite:///../../../../../」 同じ。
- を使用してデータベースからのクエリに応答するための別のチェーンを構築します。 db_chain 変数。
- 次のようなツールを設定します 検索 、 電卓 、 そして FooBar-DB 答えの検索、数学の質問への答え、データベースからのクエリのそれぞれに使用します。
ステップ 7: メモリの追加
OpenAI 機能を構成したら、メモリを構築してエージェントに追加するだけです。
ラングチェーンから。 プロンプト 輸入 メッセージプレースホルダーラングチェーンから。 メモリ 輸入 会話バッファメモリ
エージェント_kwargs = {
「extra_prompt_messages」 : [ メッセージプレースホルダー ( 変数名 = 'メモリ' ) ] 、
}
メモリ = 会話バッファメモリ ( メモリキー = 'メモリ' 、 return_messages = 真実 )
ステップ 8: エージェントの初期化
構築して初期化する最後のコンポーネントはエージェントであり、次のようなすべてのコンポーネントが含まれています。 llm 、 道具 、 OPENAI_FUNCTIONS など、このプロセスで使用されるものは次のとおりです。
エージェント = エージェントの初期化 (ツール 、
llm 、
エージェント = エージェントタイプ。 OPENAI_FUNCTIONS 、
冗長な = 真実 、
エージェント_kwargs = エージェント_kwargs 、
メモリ = メモリ 、
)
ステップ 9: エージェントのテスト
最後に、「」を使用してチャットを開始してエージェントをテストします。 こんにちは ' メッセージ:
エージェント。 走る ( 'こんにちは' ) 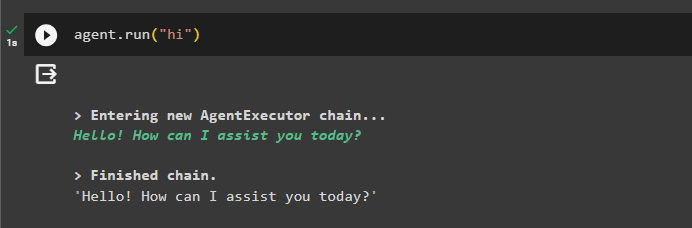
エージェントを実行してメモリに情報を追加します。
エージェント。 走る ( 「私の名前はジョン・スノウです」 ) 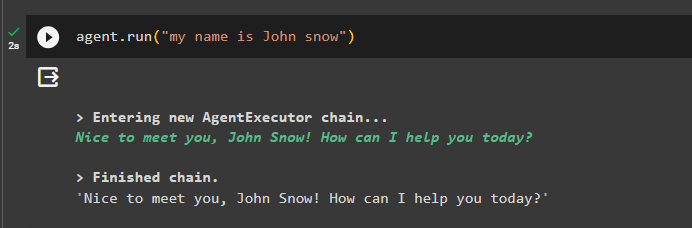
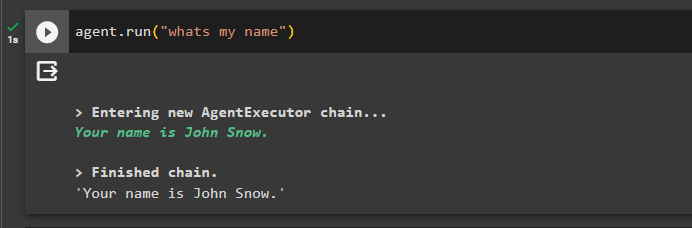
次に、前のチャットに関する質問をして記憶力をテストします。
エージェント。 走る ( '私の名前は何ですか' )エージェントはメモリから取得した名前で応答したため、メモリはエージェントで正常に実行されています。
それは今のところすべてです。
結論
LangChain の OpenAI 関数エージェントにメモリを追加するには、モジュールをインストールしてライブラリをインポートするための依存関係を取得します。その後、データベースを構築して Python ノートブックにアップロードするだけで、モデルで使用できるようになります。モデル、ツール、チェーン、データベースをエージェントに追加して初期化する前に、それらを構成します。メモリをテストする前に、ConversationalBufferMemory() を使用してメモリを構築し、それをエージェントに追加してからテストします。このガイドでは、LangChain の OpenAI 関数エージェントにメモリを追加する方法について詳しく説明しました。