ターミナル コンソールで Linux の iconv ユーティリティを見てみましょう。そのため、「-l」フラグを指定して「iconv」命令を実行し、既知で最もよく使用されるすべてのコード化文字セットを端末画面に表示しました。コード化された文字セットとそのエイリアスが表示されます。少し下にスクロールすると、コード化された文字セットの長いリストが表示されます。
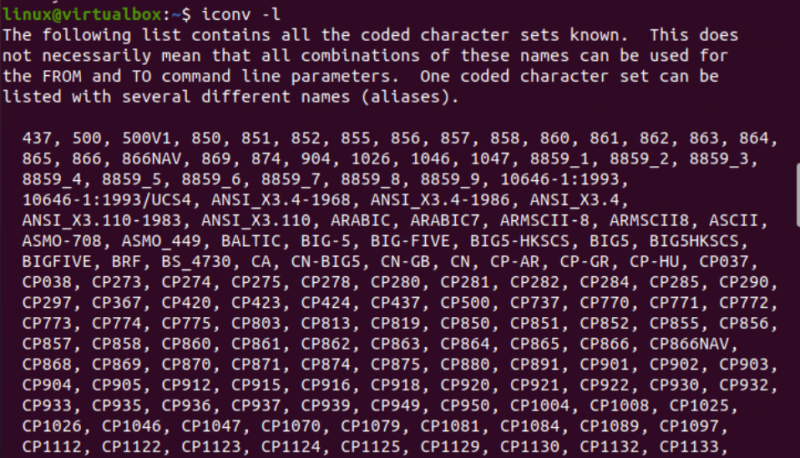
それでは、Linux での iconv コマンドの実装を開始しましょう。まず、あるタイプのファイルを別のタイプに変換するには、システムにさまざまなタイプのファイルが必要です。このように、コンソール端末で「touch」クエリを使用して、Java 型、C 型、およびテキスト型の 3 つの異なるファイルを作成しています。現在のディレクトリの内容を一覧表示すると、その中に新しく生成されたファイルが見つかります。
この後、「file」クエリと各ファイルの名前を使用して、各ファイルのタイプを個別に調べます。このクエリでは、各ファイルのコーディング文字セットのタイプを個別に表示するために、「-I」オプションが必要です。 「-I」オプションを使用するのを忘れた場合は、代わりに「—mime」フラグを使用してください。 「-I」フラグと「—mime」フラグはどちらも同じように機能します。
ここで、「txt」タイプのファイルに対して「file」命令を実行した後、「US-ASCII」文字タイプのエンコーディングを取得しました。 Java ファイルと C ファイルに同じ命令を使用すると、両方のファイルに「BINARY」文字タイプのエンコーディングが含まれていることがわかります。それに加えて、この命令は、これら 3 つのファイルがすべて空であることを示しています。
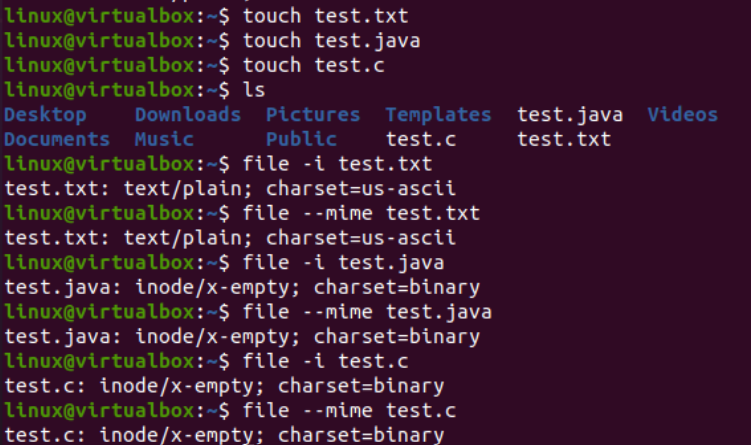
次に、コンソールで iconv 命令を使用して、特定の文字セット エンコーディング ファイルを別の文字セット エンコーディングに変換する方法を説明します。その前に、コードまたはデータをファイルに追加する必要があります。そのため、「text.java」ファイル内に Java コードを追加し、「text.c」ファイル内に C コードを追加し、「test.txt」ファイル内にテキスト データを追加しました。ここでは cat クエリを使用して、以下に示すように 3 つのファイルすべての内容を表示しています。
データが正常に追加されたので、これらのファイルの文字セット エンコーディングが再び表示されます。そのため、「-I」フラグとファイル名 (つまり、test.txt、test.java、および test.c) を使用して、シェル内で同じファイル命令を試しました。これらの 3 つの命令を 3 つのファイルすべてに対して個別に実行すると、Java ファイルと C ファイルの文字セット エンコーディングが更新され、テキスト ファイル (つまり US-ASCII) は同じままであることがわかります。 Java および C ファイルのエンコーディングは、以前は「バイナリ」でした。今は「US-ASCII」です。また、テキスト ファイルにはプレーン テキスト データが含まれているのに対し、他の 2 つのコード ファイルにはコンテンツとしてスクリプトが含まれていることがわかります。

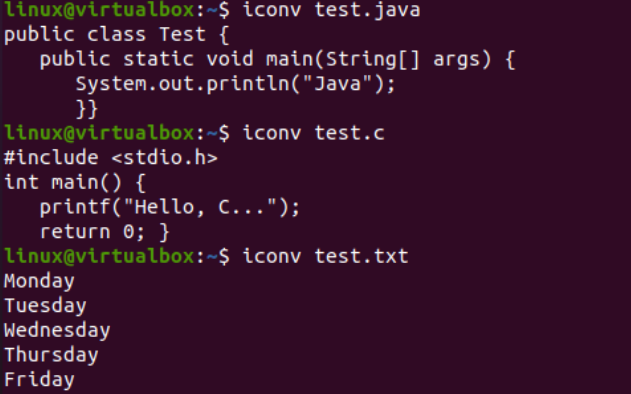
この記事に必要な実際のタスクを実行する時が来ました。つまり、シェルで iconv コマンドを使用して、あるエンコーディングを別のエンコーディングに変換します。したがって、「sudo」権限を持つシェル端末内で「iconv」命令を使用しています。このコマンドの「-f」オプションは「from」を表し、「-t」オプションは「to」を表します。つまり、あるエンコーディングから別のエンコーディングへの変換です。
「-f」オプションの後に、ファイルがすでに持っているエンコーディング、つまり US-ASCII を指定する必要があります。 「-t」オプションの後に、古いエンコーディング、つまり UNICODE に置き換えたいエンコーディングを指定する必要があります。オブジェクト イメージを作成するには、ソースとして使用するファイルの名前を –o オプションで指定する必要があります。オブジェクト画像は、同じタイプで新しいエンコーディングと同じデータを持つ別のファイル、つまり「new.c」になります。
次の命令を実行すると、同じディレクトリに新しいファイルが作成されます。つまり、「ls」クエリのとおりです。ここで、iconv 命令を使用して生成された新しいファイルの文字セット エンコーディングを確認します。ここでも、「-I」オプションと新しいファイル名、つまり new.c を指定して「file」命令を使用します。
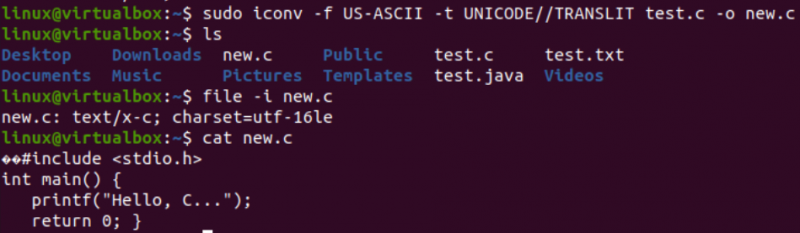
この新しいファイルの文字セットは、古いファイルの文字セット、つまり UTF-16LE 文字セットとは異なっていることがわかります。これは、new.c ファイルの iconv 命令を使用して、US-ASCII エンコーディングを UNICODE エンコーディングに変換したためです。 「cat」クエリは、ファイル内に同じ C コードを表示しましたが、既に示したように、いくつかの Unicode 文字で始まりました。
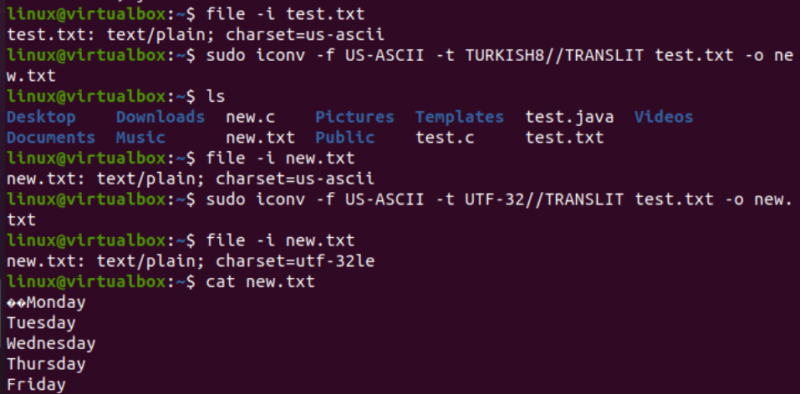
非常によく似た方法で、test.txt テキスト ファイルのエンコーディングを変更します。ファイル命令は、US-ASCII 文字セット エンコーディングがあることを示しています。 test.txt ファイルのエンコーディングを US-ASCII から TURKISH8 に変換するために、iconv コマンドがまったく同じ形式で使用されています。 US-ASCII がトルコ語に変更されていないことがわかります。
この後、同じコマンドを使用して、同じファイルの US-ASCII から UTF-32 文字セット エンコーディングをカバーしました。今回は、それが機能します。これは、あるエンコーディング セットを別のエンコーディング セットに変換する際に問題が発生したり、別のエンコーディングがサポートされていない場合があるためです。
結論
この記事では、iconv Linux 命令を使用して、エイリアスを使用してあるエンコーディング文字セットを別のエンコーディング文字セットに変換する方法について説明しました。このように、さまざまな種類のファイルをいくつか作成する必要がありました。