このガイドでは、LangChain で会話の概要を使用するプロセスを説明します。
LangChain で会話の概要を使用するには?
LangChain は、チャットや会話の完全な概要を抽出できる ConversationsummaryMemory のようなライブラリを提供します。これを使用すると、チャット内のすべてのメッセージやテキストを読まなくても、会話の主な情報を取得できます。
LangChain で会話の概要を使用するプロセスを学ぶには、次の手順に進んでください。
ステップ 1: モジュールをインストールする
まず、次のコードを使用して、LangChain フレームワークをインストールし、その依存関係またはライブラリを取得します。
pip インストール ラングチェーン
次に、pip コマンドを使用して LangChain をインストールした後、OpenAI モジュールをインストールします。
pip インストール openai 
モジュールをインストールした後は、 環境をセットアップする OpenAI アカウントから API キーを取得した後、次のコードを使用します。
輸入 あなた輸入 ゲットパス
あなた 。 約 [ 「OPENAI_API_KEY」 ] = ゲットパス 。 ゲットパス ( 「OpenAI API キー:」 )
ステップ 2: 会話の概要を使用する
LangChain からライブラリをインポートして、会話の概要を使用するプロセスを開始します。
から ラングチェーン。 メモリ 輸入 会話概要記憶 、 チャットメッセージ履歴から ラングチェーン。 llms 輸入 OpenAI
ConversationsummaryMemory() メソッドと OpenAI() メソッドを使用してモデルのメモリを構成し、そこにデータを保存します。
メモリ = 会話概要記憶 ( llm = OpenAI ( 温度 = 0 ) )メモリ。 コンテキストの保存 ( { '入力' : 'こんにちは' } 、 { '出力' : 'こんにちは' } )
を呼び出してメモリを実行します。 ロードメモリ変数() メモリからデータを抽出するメソッド:
メモリ。 ロードメモリ変数 ( { } ) 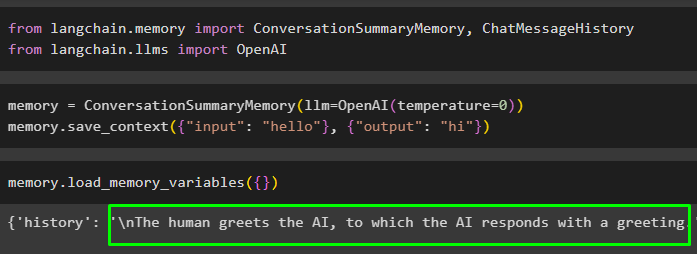
ユーザーは、各エンティティのような個別のメッセージを含む会話形式でデータを取得することもできます。
メモリ = 会話概要記憶 ( llm = OpenAI ( 温度 = 0 ) 、 return_messages = 真実 )メモリ。 コンテキストの保存 ( { '入力' : 'こんにちは' } 、 { '出力' : 「こんにちは!調子はどうですか?」 } )
AI と人間のメッセージを個別に取得するには、load_memory_variables() メソッドを実行します。
メモリ。 ロードメモリ変数 ( { } ) 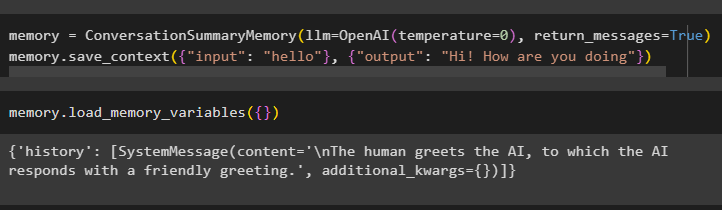
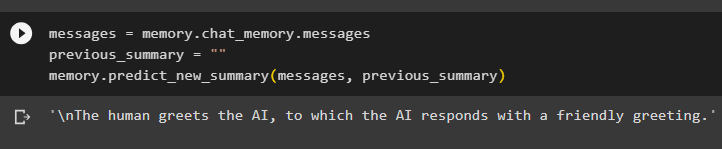
会話の概要をメモリに保存し、メモリを実行してチャット/会話の概要を画面に表示します。
メッセージ = メモリ。 チャットメモリ 。 メッセージ前の概要 = 「」
メモリ。 予測_新しい_概要 ( メッセージ 、 前の概要 )
ステップ 3: 既存のメッセージで会話の概要を使用する
ユーザーは、ChatMessageHistory() メッセージを使用して、クラスまたはチャットの外に存在する会話の概要を取得することもできます。これらのメッセージをメモリに追加すると、会話全体の概要が自動的に生成されます。
歴史 = チャットメッセージ履歴 ( )歴史。 add_user_message ( 'こんにちは' )
歴史。 add_ai_message ( 'やあ!' )
OpenAI() メソッドを使用して LLM などのモデルを構築し、 チャットメモリ 変数:
メモリ = 会話概要記憶。 from_messages (llm = OpenAI ( 温度 = 0 ) 、
チャットメモリ = 歴史 、
return_messages = 真実
)
バッファを使用してメモリを実行し、既存のメッセージの概要を取得します。
メモリ。 バッファ 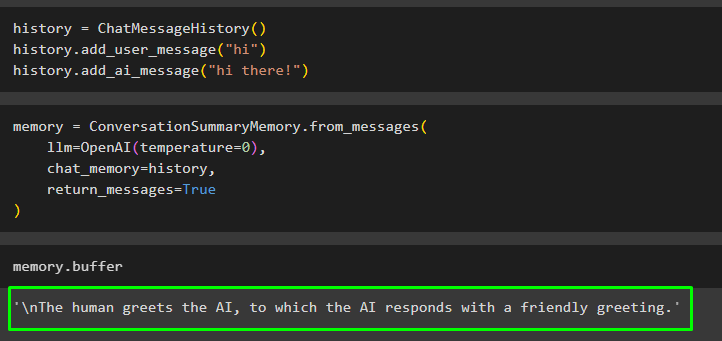
次のコードを実行して、チャット メッセージを使用してバッファ メモリを構成して LLM を構築します。
メモリ = 会話概要記憶 (llm = OpenAI ( 温度 = 0 ) 、
バッファ = '''人間は機械に自分自身について尋ねます
システムは、AI は人間の可能性を実現するのに役立つため、永久に構築されると答えます。」 、
チャットメモリ = 歴史 、
return_messages = 真実
)
ステップ 4: 会話の要約をチェーンで使用する
次のステップでは、LLM を使用してチェーン内で会話の概要を使用するプロセスについて説明します。
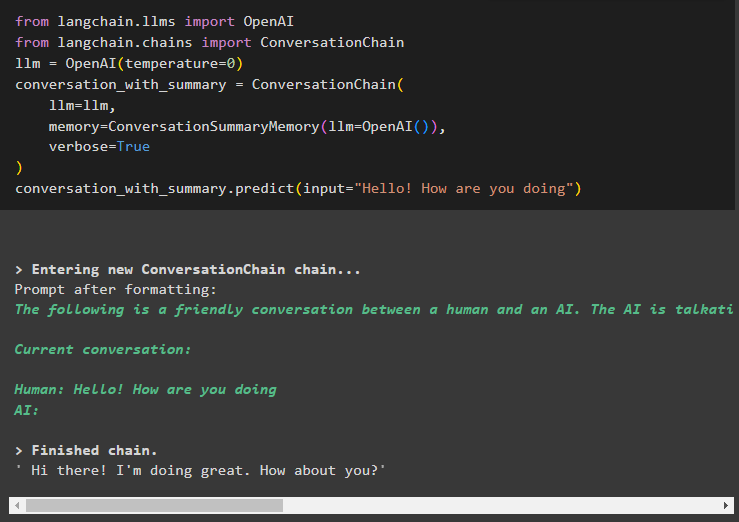
から ラングチェーン。 llms 輸入 OpenAIから ラングチェーン。 鎖 輸入 会話チェーン
llm = OpenAI ( 温度 = 0 )
会話と概要 = 会話チェーン (
llm = llm 、
メモリ = 会話概要記憶 ( llm = OpenAI ( ) ) 、
冗長な = 真実
)
会話と概要。 予測する ( 入力 = 'こんにちは、どうしてる' )
ここでは、丁寧な質問から会話を始めることでチェーンの構築を開始しました。
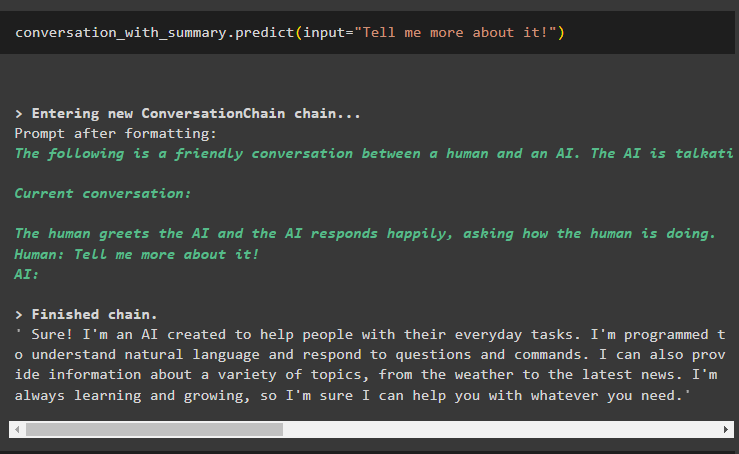
ここで、最後の出力についてもう少し詳しく質問して、それを拡張して会話に入ります。
会話と概要。 予測する ( 入力 = 'それについてもっと教えて!' )モデルは、AI テクノロジーまたはチャットボットの詳細な紹介で最後のメッセージを説明しています。
前の出力から関心のある点を抽出して、会話を特定の方向に導きます。
会話と概要。 予測する ( 入力 = 「すごいですね、このプロジェクトはどれくらい素晴らしいですか?」 )ここでは、会話概要メモリ ライブラリを使用してボットから詳細な回答を取得しています。
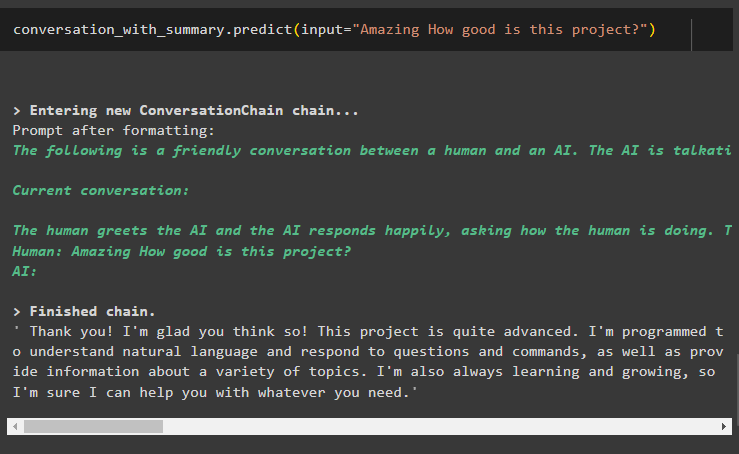
LangChain での会話の概要の使用については以上です。
結論
LangChain で会話概要メッセージを使用するには、環境のセットアップに必要なモジュールとフレームワークをインストールするだけです。環境が設定できたら、インポートします。 会話概要記憶 OpenAI() メソッドを使用して LLM を構築するためのライブラリ。その後、会話の概要を使用して、前の会話の概要である詳細な出力をモデルから抽出するだけです。このガイドでは、LangChain モジュールを使用して会話概要メモリを使用するプロセスについて詳しく説明しました。