ループを持つ連結リストの終了ノードは、NULL ではなく、同じリスト内の別のノードを参照します。次のポインタをたどって繰り返しアクセスできる連結リストにノードがある場合、そのリストは次のようになります。サイクルがあります。
通常、リンク リストの最後のノードは、リストの結論を示すために NULL 参照を参照します。ただし、ループのある連結リストでは、リストの終了ノードは開始ノード、内部ノード、またはそれ自体を参照します。したがって、このような状況では、次のノードの参照を NULL に設定して、ループを識別して終了する必要があります。リンクされたリストのループの検出部分は、この記事で説明されています。
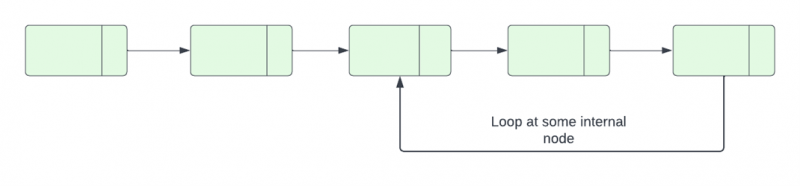
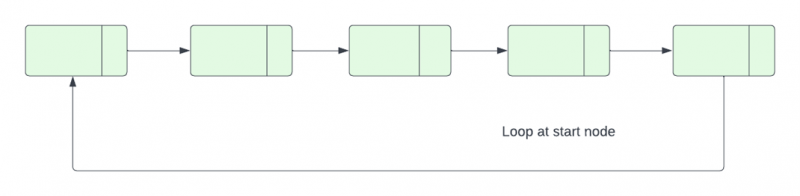
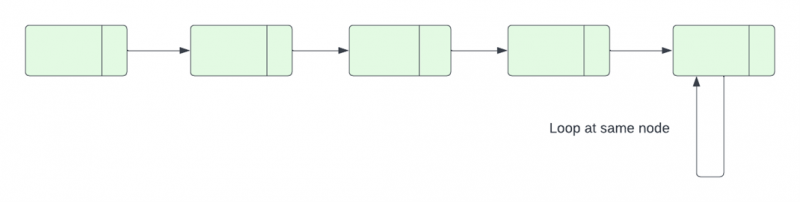
C++ では、連結リスト内のループを見つける方法は多数あります。
ハッシュテーブルベースのアプローチ : このアプローチでは、訪問したノードのアドレスをハッシュ テーブルに格納します。再度アクセスしたときに、ノードがハッシュ テーブルに既に存在する場合、リンクされたリストにループが存在します。
フロイドのサイクルアプローチ : 「うさぎと亀」のアルゴリズム。一般にフロイドの周期探索アルゴリズムとして知られています。この手法では、2 つのポインターを使用します。一方は他方よりゆっくりと動き、もう一方はより速く動きます。リンクされたリストにループがある場合、より速いポインターは最終的に遅いポインターを追い越し、ループの存在を明らかにします。
再帰的方法 : このメソッドは、自分自身を何度も呼び出すことにより、リンクされたリストを調べます。現在のノードが以前にアクセスされている場合、リンクされたリストにはループが含まれます。
スタックベースのアプローチ : このアプローチは、訪問したノードのアドレスをスタックに格納します。ノードが再度アクセスされたときにノードがスタック内にすでに存在する場合、リンクされたリストにループが存在します。
概念を理解するために、それぞれのアプローチを詳しく説明しましょう。
アプローチ 1: HashSet アプローチ
ハッシュを利用するのが最も簡単な方法です。ここでは、ノード アドレスのハッシュ テーブルを保持しながら、リストを 1 つずつ調べます。したがって、ハッシュ テーブルに既に含まれている現在のノードの次のアドレスに遭遇した場合、ループが発生します。それ以外の場合、NULL に遭遇した場合 (つまり、リンク リストの最後に到達した場合)、リンク リストにループはありません。
この戦略を実装するのは非常に簡単です。
リンクされたリストをトラバースしながら、unordered_hashmap を利用し、それにノードを追加し続けます。
ここで、すでにマップに表示されているノードに遭遇すると、ループの開始点に到達したことがわかります。
-
- さらに、各ステップで 2 つのポインターを保持し、 ヘッドノード 現在のノードを指し、 lastNode 繰り返しながら、現在のノードの前のノードを指します。
- 私たちのように ヘッドノード 現在、ループの開始ノードを指しており、 lastNode head が指していたノードを指していました (つまり、それは lastNode ループの)、私たちの ヘッドノード 現在、ループの開始ノードを指しています。
- l を設定することでループが壊れます。 astNode->次 == NULL .
これにより、ループの最初のノードを参照する代わりに、終了ループ ノードが NULL を指し始めます。
ハッシュ方式の平均時間と空間の複雑さは O(n) です。読者は、プログラミング言語での組み込みの Hashing DataStructure の実装によって、ハッシングで衝突が発生した場合の合計時間の計算量が決まることに常に注意する必要があります。
上記のメソッド (HashSet) の C++ プログラム実装:
#include
名前空間 std を使用します。
構造体ノード {
int 値;
構造体ノード * 次;
} ;
ノード * 新しいノード ( 整数値 )
{
ノード * tempNode = 新しいノード;
tempNode- > 値 = 値;
tempNode- > 次 = NULL;
戻る tempNode;
}
/// 潜在的なループを特定して排除する
/// の この関数を持つ連結リスト。
void functionHashMap ( ノード * ヘッドノード )
{
/// ハッシュマップを実装する unordered_map を作成
unordered_map < ノード * 、整数 > hash_map;
/// lastNode へのポインター
ノード * lastNode = NULL;
その間 ( ヘッドノード ! =ヌル ) {
/// ノードがマップにない場合は、追加します。
もしも ( hash_map.find ( ヘッドノード ) == hash_map.end ( ) ) {
hash_map [ ヘッドノード ] ++;
lastNode = headNode;
headNode = headNode- > 次;
}
/// 循環があれば、 設定 最終ノード の NULL への次のポインタ。
それ以外 {
lastNode->next = NULL;
壊す;
}
}
}
// リンクされたリストを表示
void display(Node* headNode)
{
while (headNode != NULL) {
cout << headNode->value << ' ';
headNode = headNode->next;
}
cout << endl;
}
/* メイン機能*/
int main()
{
Node* headNode = newNode(48);
headNode->next = headNode;
headNode->next = newNode(18);
headNode->next->next = newNode(13);
headNode->next->next->next = newNode(2);
headNode->next->next->next->next = newNode(8);
/* linkedList にループを作成します */
headNode->next->next->next->next->next = headNode->next->next;
functionHashMap(headNode);
printf('ループなしの連結リスト \n');
表示 (headNode);
0 を返します。
}
出力:
ループなしの連結リスト
48 18 13 2 8
コードの段階的な説明を以下に示します。
-
- コードには、すべての一般的な C++ ライブラリを含む bits/stdc++.h> ヘッダー ファイルが含まれています。
- 「ノード」と呼ばれる構造体が構築され、リスト内の次のノードへの参照と「値」と呼ばれる整数の 2 つのメンバーがあります。
- 入力として整数値を使用し、「next」ポインタを NULL に設定すると、関数「newNode」はその値で新しいノードを作成します。
- 関数 ' functionHashMap' が定義されており、リンク リストの先頭ノードへのポインターを入力として受け取ります。
- 'の中に 関数ハッシュマップ ‘hash_map’ という名前の unordered_map が作成され、ハッシュ マップ データ構造を実装するために使用されます。
- リストの最後のノードへのポインターは NULL に初期化されます。
- while ループを使用して、リンクされたリストをトラバースします。これは、ヘッド ノードから始まり、ヘッド ノードが NULL になるまで続きます。
- 現在のノード (headNode) がまだハッシュ マップに存在しない場合、lastNode ポインターは while ループ内の現在のノードに更新されます。
- 現在のノードがマップにある場合は、リンクされたリストにループが存在することを意味します。ループを削除するには、次のポインター lastNode に設定されています ヌル while ループが壊れています。
- リンクされたリストの先頭ノードは、「display」と呼ばれる関数の入力として使用されます。この関数は、リスト内の各ノードの値を最初から最後まで出力します。
- の中に 主要 関数、ループを作成します。
- 関数「functionHashMap」は、headNode ポインターを入力として呼び出され、リストからループを削除します。
- 変更されたリストは、'display' 関数を使用して表示されます。
アプローチ 2: フロイドのサイクル
カメとウサギのアルゴリズムとして知られるフロイドのサイクル検出アルゴリズムは、リンクされたリストでサイクルを見つけるこの方法の基礎を提供します。さまざまな速度でリストをトラバースする「低速」ポインターと「高速」ポインターは、この手法で使用される 2 つのポインターです。高速ポインターは 2 ステップ進みますが、低速ポインターは反復ごとに 1 ステップ進みます。 2 つの点が向かい合った場合、リンクされたリストにサイクルが存在します。
1. リンク リストのヘッド ノードで、fast と slow という 2 つのポインターを初期化します。
2. ループを実行して、リンクされたリストを移動します。高速ポインターは、各反復のステップで低速ポインターの前に 2 つの場所に移動する必要があります。
3. 高速ポインタがリストの最後に到達した場合 (fastPointer == NULL または fastPointer->next == NULL)、リンクされたリストにループは発生しません。そうでない場合、高速ポインターと低速ポインターが最終的に一致します。これは、リンクされたリストにループがあることを意味します。
上記のメソッドの C++ プログラムの実装 (フロイドのサイクル):
#include
名前空間 std を使用します。
/* リンク リスト ノード */
構造体ノード {
int データ;
構造体ノード * 次;
} ;
/* ループを削除する関数。 */
ボイド削除ループ ( 構造体ノード * 、構造体ノード * ) ;
/* これ 関数 リストループを見つけて排除します。それは得ます 1
もしも ループがあった の リスト; それ以外 、それを返します 0 . */
int detectAndDeleteLoop ( 構造体ノード * リスト )
{
構造体ノード * slowPTR = リスト、 * fastPTR = リスト;
/// 確認を繰り返す もしも ループはそこにあります。
その間 ( スローPTR && fastPTR && fastPTR- > 次 ) {
slowPTR = slowPTR- > 次;
fastPTR = fastPTR- > 次- > 次;
/* ある時点で slowPTR と fastPTR が出会った場合 それから そこには
ループです */
もしも ( slowPTR == fastPTR ) {
削除ループ ( slowPTR、リスト ) ;
/* 戻る 1 ループが発見されたことを示します。 */
戻る 1 ;
}
}
/* 戻る 0 ループが発見されていないことを示します。 */
戻る 0 ;
}
/* 連結リストからループを削除する関数。
loopNode がループ ノードの 1 つを指しており、headNode が指している
リンクリストの開始ノードへ */
ボイド削除ループ ( 構造体ノード * loopNode、構造体ノード * ヘッドノード )
{
構造体ノード * ptr1 = loopNode;
構造体ノード * ptr2 = loopNode;
/// ノード数を数える の ループ。
符号なし整数 k = 1 、 私;
その間 ( ptr1- > 次 ! =ptr2 ) {
ptr1 = ptr1- > 次;
k++;
}
/// headNode へのポインターを 1 つ修正する
ptr1 = headNode;
/// そして、headNode の後の k ノードへのもう 1 つのポインター
ptr2 = headNode;
ために ( 私= 0 ;私 < k; i++ )
ptr2 = ptr2- > 次;
/* 両方のポイントを同時に移動すると、
彼らはループで衝突します の開始ノード。 */
while (ptr2 != ptr1) {
ptr1 = ptr1->next;
ptr2 = ptr2->next;
}
// ノードを取得します' s 最後 ポインター。
その間 ( ptr2- > 次 ! = ptr1 )
ptr2 = ptr2- > 次;
/* ループを閉じるには、 設定 その後の
ループへのノード の終端ノード。 */
ptr2->next = NULL;
}
/* リンクリスト表示機能 */
void displayLinkedList(struct Node* node)
{
// ループ削除後、連結リストを表示
while (ノード != NULL) {
cout << node->data << ' ';
ノード = ノード-> 次;
}
}
struct Node* newNode(int key)
{
struct Node* temp = new Node();
temp->data = キー;
temp->next = NULL;
戻り温度;
}
// メインコード
int main()
{
struct Node* headNode = newNode(48);
headNode->next = newNode(18);
headNode->next->next = newNode(13);
headNode->next->next->next = newNode(2);
headNode->next->next->next->next = newNode(8);
/* ループを作成します */
headNode->next->next->next->next->next = headNode->next->next;
// リンクされたリストにループを表示します
//displayLinkedList(headNode);
detectAndDeleteLoop(headNode);
cout << 'ループなしのリンク リスト \n';
displayLinkedList(headNode);
0 を返します。
}
出力:
ループなしのリンクされたリスト
48 18 13 2 8
説明:
-
- 「bits/stdc++.h」や「std::cout」などの関連ヘッダーが最初に含まれます。
- 次に、リンクされたリスト内のノードを表す「Node」構造体が宣言されます。リスト内の次のノードにつながる次のポインターが、各ノードの整数データ フィールドと共に含まれます。
- 次に、「deleteLoop」と「detectAndDeleteLoop」という 2 つの関数を定義します。最初のメソッドを使用してリンク リストからループを削除し、2 番目の関数を使用してリスト内でループを検出すると、最初のプロシージャを呼び出してループを削除します。
- メイン関数で 5 つのノードを持つ新しい連結リストを作成し、最後のノードの次のポインターを 3 番目のノードに設定してループを確立します。
- 次に、リンク リストのヘッド ノードを引数として渡しながら、「detectAndDeleteLoop」メソッドを呼び出します。ループを識別するために、この関数は「低速ポインターと高速ポインター」アプローチを使用します。リストの先頭から始まる 2 つのポインタ、slowPTR と fastPTR を使用します。高速ポインターは一度に 2 つのノードを移動しますが、低速ポインターは一度に 1 つのノードのみを移動します。リストにループが含まれている場合、高速ポインターは最終的に低速ポインターを追い越し、2 つの点が同じノードで衝突します。
- この関数は、ループが見つかった場合に「deleteLoop」関数を呼び出し、リストの先頭ノードと、低速ポインターと高速ポインターの交点を入力として提供します。このプロシージャは、リストのヘッド ノードへの 2 つのポインタ、ptr1 および ptr2 を確立し、ループ内のノードの数をカウントします。それに続いて、1 つのポインター k ノードを進めます。ここで、k はループ内のノードの総数です。次に、それらがループの開始点で出会うまで、一度に 1 つのノードで両方のポイントを進めます。次に、ループの最後にあるノードの次のポインターを NULL に設定することによって、ループが中断されます。
- ループを削除した後、リンクされたリストを最終ステップとして表示します。
アプローチ 3: 再帰
再帰は、問題をより小さく、より簡単な部分問題に分割することによって問題を解決する手法です。再帰は、リストの最後に到達するまでリスト内の次のノードの関数を継続的に実行することによってループが見つかった場合に、単一リンク リストをトラバースするために使用できます。
単一リンクリストでは、再帰を使用してループを見つける基本原則は、リストの先頭から開始し、現在のノードを各ステップで訪問済みとしてマークし、関数 for を再帰的に呼び出して次のノードに進むことです。そのノード。メソッドは再帰的に呼び出されるため、完全なリンク リストを反復処理します。
以前に訪問済みとしてマークされたノードが関数によって検出された場合、リストにはループが含まれます。この場合、関数は true を返すことができます。訪問したノードを通過せずにリストの最後に到達した場合、メソッドは false を返すことができます。これは、ループがないことを示します。
再帰を利用して 1 つのリンク リスト内のループを見つけるこの手法は、簡単に使用および理解できますが、時間と空間の複雑さの点で最も効果的な手法ではない可能性があります。
上記のメソッド (再帰) の C++ プログラム実装:
#include
名前空間 std を使用します。
構造体ノード {
int データ;
ノード * 次;
ブールが訪れました。
} ;
/// リンクリストのループ検出 関数
booldetectLoopLinkedList ( ノード * ヘッドノード ) {
もしも ( ヘッド ノード == NULL ) {
戻る 間違い ; /// リンクされたリストが空の場合、基本 場合
}
/// ループがある もしも 現在のノードは
/// すでに訪問済みです。
もしも ( headNode- > 訪れた ) {
戻る 真実 ;
}
/// 現在のノードに訪問マークを追加します。
headNode- > 訪れた = 真実 ;
/// コードの呼び出し ために 後続のノードを繰り返し
戻る detectLoopLinkedList ( headNode- > 次 ) ;
}
int メイン ( ) {
ノード * headNode = 新しいノード ( ) ;
ノード * secondNode = 新しいノード ( ) ;
ノード * thirdNode = 新しいノード ( ) ;
headNode- > データ = 1 ;
headNode- > 次 = 2 番目のノード;
headNode- > 訪れた = 間違い ;
secondNode- > データ = 2 ;
secondNode- > 次 = サードノード;
secondNode- > 訪れた = 間違い ;
thirdNode- > データ = 3 ;
thirdNode- > 次 = NULL; /// ループなし
thirdNode- > 訪れた = 間違い ;
もしも ( detectLoopLinkedList ( ヘッドノード ) ) {
カウト << 「連結リストでループが検出されました」 << エンドル;
} それ以外 {
カウト << 「リンクされたリストでループが検出されませんでした」 << エンドル;
}
/// ループの作成
thirdNode- > 次 = 2 番目のノード;
もしも ( detectLoopLinkedList ( ヘッドノード ) ) {
カウト << 「連結リストでループが検出されました」 << エンドル;
} それ以外 {
カウト << 「リンクされたリストでループが検出されませんでした」 << エンドル;
}
戻る 0 ;
}
出力:
ループが検出されませんでした の 連結リスト
ループが検出されました の 連結リスト
説明:
-
- 関数 detectLoopLinkedList() このプログラムでは、連結リストの先頭を入力として受け入れます。
- 関数は再帰を使用して、リンクされたリストを反復処理します。再帰の基本的なケースとして、現在のノードが NULL かどうかを判断することから始めます。その場合、メソッドは false を返し、ループが存在しないことを示します。
- 次に、現在のノードの「訪問済み」プロパティの値がチェックされ、以前に訪問されたかどうかが確認されます。アクセスされている場合は true を返し、ループが見つかったことを示します。
- この関数は、「visited」プロパティを true に変更することにより、現在のノードが既にアクセスされている場合、そのノードをアクセス済みとしてマークします。
- 次に、現在のノードが以前に訪問されたかどうかを確認するために、訪問済み変数の値がチェックされます。以前に使用されていた場合、ループが存在する必要があり、関数は true を返します。
- 最後に、関数は次のノードを渡すことで、リスト内の次のノードで自分自身を呼び出します。 headNode->next 引数として。 再帰的に 、これは、ループが見つかるか、すべてのノードが訪問されるまで実行されます。つまり、リンクされたリスト内の次のノードを再帰的に呼び出す前に、現在のノードが一度も訪問されていない場合、関数は訪問済み変数を true に設定します。
- このコードは 3 つのノードを構築し、それらを結合してリンク リストを生成します。 メイン機能 .方法 detectLoopLinkedList() その後、リストのヘッド ノードで呼び出されます。プログラムは「 リンクされたリストでループが差し引かれました ' もしも detectLoopLinkedList() true を返します。それ以外の場合、「 リンクされたリストでループが検出されませんでした 」。
- 次に、コードは、最後のノードの次のポインターを 2 番目のノードに設定することによって、リンクされたリストにループを挿入します。次に、関数の結果に応じて実行されます detectLoopLinkedList() 再び、次のいずれかを生成します “ リンクされたリストでループが差し引かれました ' また ' リンクされたリストでループが検出されませんでした 」
アプローチ 4: スタックの使用
リンクされたリスト内のループは、スタックと「深さ優先検索」(DFS) メソッドを使用して見つけることができます。基本的な概念は、リンクされたリストを反復処理し、まだアクセスされていない場合は各ノードをスタックにプッシュすることです。スタック上に既に存在するノードが再び検出されると、ループが認識されます。
手順の簡単な説明は次のとおりです。
-
- 空のスタックと変数を作成して、アクセスしたノードを記録します。
- リンクされたリストを一番上からスタックにプッシュします。頭が訪問されていることに注意してください。
- リスト内の次のノードをスタックにプッシュします。このノードに訪問マークを追加します。
- リストをトラバースしながら、新しいノードをそれぞれスタックにプッシュして、アクセスしたことを示します。
- 検出された場合、以前にアクセスしたノードがスタックの一番上にあるかどうかを確認します。その場合、ループが検出され、スタック内のノードによってループが識別されます。
- ノードをスタックからポップし、ループが見つからない場合はリストをトラバースし続けます。
上記のメソッドの C++ プログラムの実装 (スタック)
#include
#include <スタック>
名前空間 std を使用します。
構造体ノード {
int データ;
ノード * 次;
} ;
/// ループ検知機能 の リンクされたリスト
booldetectLoopLinkedList ( ノード * ヘッドノード ) {
スタック < ノード *> スタック;
ノード * tempNode = headNode;
その間 ( 一時ノード ! =ヌル ) {
/// もしも スタックの一番上の要素が一致する
/// 現在のノードとスタックが空ではない
もしも ( ! スタック。空 ( ) && スタックトップ ( ) == 一時ノード ) {
戻る 真実 ;
}
スタックプッシュ ( 一時ノード ) ;
tempNode = tempNode- > 次;
}
戻る 間違い ;
}
int メイン ( ) {
ノード * headNode = 新しいノード ( ) ;
ノード * secondNode = 新しいノード ( ) ;
ノード * thirdNode = 新しいノード ( ) ;
headNode- > データ = 1 ;
headNode- > 次 = 2 番目のノード;
secondNode- > データ = 2 ;
secondNode- > 次 = サードノード;
thirdNode- > データ = 3 ;
thirdNode- > 次 = NULL; /// ループなし
もしも ( detectLoopLinkedList ( ヘッドノード ) ) {
カウト << 「連結リストでループが検出されました」 << エンドル;
} それ以外 {
カウト << 「リンクされたリストでループが検出されませんでした」 << エンドル;
}
/// ループの作成
thirdNode- > 次 = 2 番目のノード;
もしも ( detectLoopLinkedList ( ヘッドノード ) ) {
カウト << 「連結リストでループが検出されました」 << エンドル;
} それ以外 {
カウト << 「リンクされたリストでループが検出されませんでした」 << エンドル;
}
出力:
ループが検出されませんでした の 連結リスト
ループが検出されました の 連結リスト
説明:
このプログラムは、スタックを使用して、片方向リストにループがあるかどうかを調べます。
- 1. 入出力ストリーム ライブラリとスタック ライブラリは両方とも 1 行目に存在します。
2. 標準の名前空間が 2 行目に含まれているため、「std::」を前に付けなくても、入出力ストリーム ライブラリの関数にアクセスできます。
3. 次の行は、「data」と呼ばれる整数と「next」と呼ばれる別のノードへのポインターの 2 つのメンバーで構成される構造体 Node を定義します。
4. リンクされたリストの先頭は、次の行で定義されるメソッド detectLoopLinkedList() の入力です。この関数は、ループが見つかったかどうかを示すブール値を生成します。
5. 「stack」と呼ばれるノード ポインタのスタックと、headNode の値で初期化される「tempNode」という名前のノードへのポインタは、両方とも関数内で作成されます。
6. 次に、tempNode が null ポインターでない限り、while ループに入ります。
(a) スタックの最上位要素は、空でないことを確認するために現在のノードと一致する必要があります。ループが見つかったためにこれが当てはまる場合は true を返します。
(b) 上記の条件が false の場合、現在のノード ポインタがスタックにプッシュされ、tempNode がリンク リスト内の次のノードに設定されます。
7. ループが観察されなかったので、while ループの後に false を返します。
8. 3 つの Node オブジェクトを作成し、main() 関数で初期化します。最初の例ではループがないため、各ノードの「次の」ポインタを適切に設定します。
結論:
結論として、リンクされたリスト内のループを検出する最良の方法は、特定のユース ケースと問題の制約によって異なります。 Hash Table と Floyd のサイクル検索アルゴリズムは効率的な方法であり、実際に広く使用されています。スタックと再帰はあまり効率的ではありませんが、より直感的な方法です。