このガイドでは、AWS サービスを使用した相互検証とその仕組みについて説明します。
相互検証とは何ですか?
相互検証により、開発者はさまざまな機械学習モデルを比較し、実際の動作の感覚を得ることができます。これは、ユーザーが特定のデータまたはシナリオに対してどちらの機械学習 (ML) モデルまたは深層学習 (DL) モデルがより適切に機能するかを判断するのに役立ちます。 1 つのデータセットに複数のモデルを使用できる状況があります。この場合、開発者は相互検証を使用して適合モデルを取得し、最適化された結果を取得します。
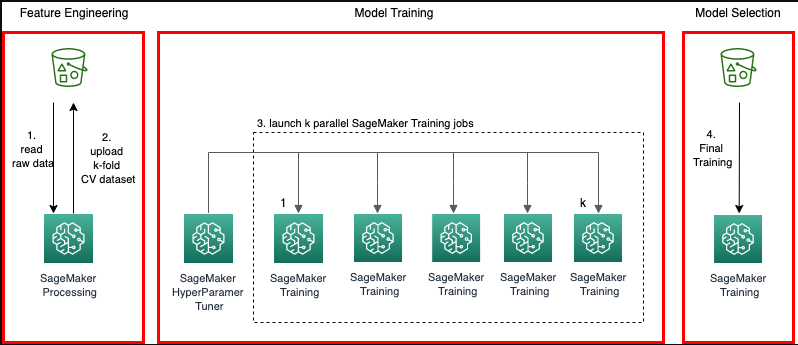
相互検証はどのように機能しますか?
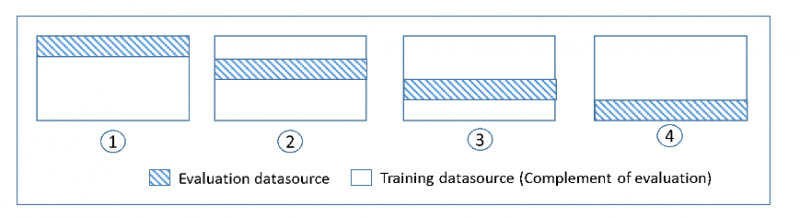
データセット上の ML モデルを確認するには、ユーザーはモデルの特徴を推定する必要があります。これはアルゴリズムのトレーニングと呼ばれます。もう 1 つチェックすべきことは、モデルのパフォーマンスがどの程度優れているかを確認するためのモデルの評価であり、これはモデルのテストと呼ばれます。すべてのデータでモデルをテストすることは得策ではありませんが、より良い結果を得るために、データの 75% をトレーニングに使用し、25% をテストに使用します。相互検証では、データの 25% ごとにテストを実行して、どのブロックのパフォーマンスが最も優れているかを確認します。
Amazon SageMaker とは何ですか?
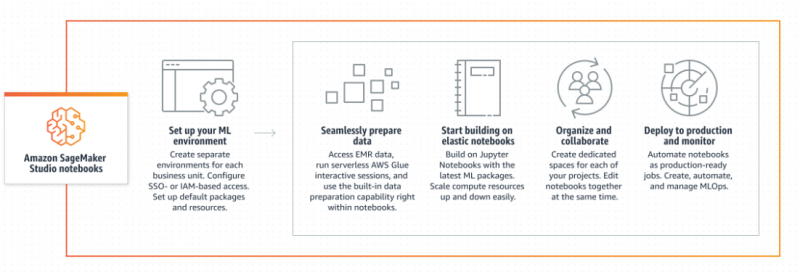
AWS での相互検証は、機械学習モデルを構築、トレーニング、デプロイするように設計されている Amazon SageMaker サービスを使用して実行できます。データ サイエンティストや開発者が、専用の機能を統合することで、効率的な ML または DL モデルを構築するためのデータを準備するのに役立ちます。これらの機能は、時間の経過とともに改善できる、最適化された正確なモデルを構築するのに役立ちます。

Amazon SageMaker の機能
Amazon SageMaker はマネージドサービスであり、ML 環境の管理は必要ありません。 ML モデルのトレーニングと構築には大量のデータが必要なので、Amazon S3 サービスまたは Amazon Redshift サービスとうまく接続してデータを収集します。生データから情報を取得するのは難しいため、モデルを構築するための機能も必要です。次に、データを使用してモデルをトレーニングし、データの 25% ごとにテストを実行して、より良い結果/予測を取得します。
AWS での相互検証については以上です。
結論
相互検証は、より良い結果を得るためにデータに最適な機械学習または深層学習モデルを取得するプロセスです。データの 25% セクションごとにテストを実行して、どのブロックが最大出力を提供し、適切な適合モデルとなるかを理解します。 AWS は、クラウド上で相互検証を実行し、機械学習モデルを構築するための SageMaker サービスを提供します。このガイドでは、相互検証プロセスと AWS でのその動作について説明しました。