例 1: R の Grep() 関数を使用して文字列からパターンの位置を取得する
文字列から指定されたパターンの位置を抽出するには、R の grep() 関数を使用します。
grep('i+', c('fix', 'split', 'corn n', 'paint'), perl=TRUE, value=FALSE)ここでは、文字列のベクトル内で照合する引数として「+i」パターンを指定する grep() 関数を使用します。 4 つの文字列を含む文字ベクトルを設定します。その後、「perl」引数に R が Perl 互換の正規表現ライブラリを使用することを示す TRUE 値を設定し、「value」パラメータには要素のインデックスを取得するために使用される「FALSE」値を指定します。パターンに一致するベクトル内。
ベクトル文字の各文字列の「+i」パターンの位置が、次の出力に表示されます。

例 2: R の Gregexpr() 関数を使用したパターンの一致
次に、gregexpr() 関数を使用して、R 内の特定の文字列の長さとともにインデックス位置を取得します。
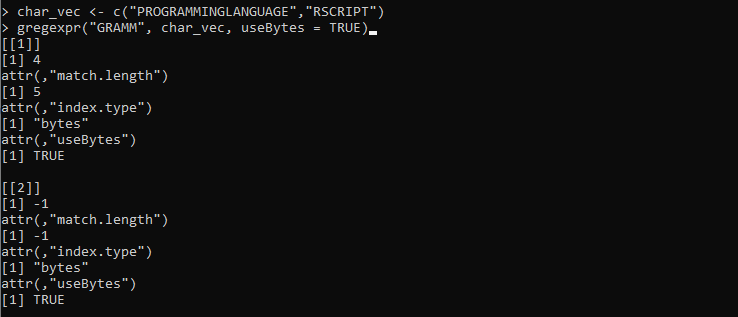
char_vec <- c('プログラミング言語','RSCRIPT')
gregexpr('GRAMM', char_vec, useBytes = TRUE)
ここでは、文字列にさまざまな文字が提供される「char_vect」変数を設定します。その後、「GRAMM」文字列パターンを受け取り、「char_vec」に格納されている文字列と照合する gregexpr() 関数を定義します。次に、useBytes パラメータに「TRUE」値を設定します。このパラメータは、文字ごとではなくバイトごとに一致を達成する必要があることを示します。
gregexpr() 関数から取得された次の出力は、両方のベクトル文字列のインデックスと長さを表します。
例 3: R の Nchar() 関数を使用して文字列の合計文字数をカウントする
以下で実装する nchar() メソッドを使用すると、文字列内の文字数を判断することもできます。
Res <- nchar('各文字を数える')印刷(解像度)
ここでは、「Res」変数内に設定されている nchar() メソッドを呼び出します。 nchar() メソッドには、nchar() メソッドによってカウントされる長い文字列が提供され、指定された文字列内のカウンター文字の数が提供されます。次に、「Res」変数を print() メソッドに渡して、nchar() メソッドの結果を確認します。
結果は次の出力で受け取られ、指定された文字列に 20 文字が含まれていることを示します。

例 4: R の Substring() 関数を使用して文字列から部分文字列を抽出する
substring() メソッドを「start」および「stop」引数とともに使用して、文字列から特定の部分文字列を抽出します。
str <- 部分文字列('朝', 2, 4)印刷(文字列)
ここでは、substring() メソッドが呼び出される「str」変数があります。 substring() メソッドは、最初の引数として「MORNING」という文字列を取り、2 番目の引数として値「2」を受け取ります。これは、文字列から 2 番目の文字が抽出されることを示し、引数「4」の値は次のことを示します。 4 番目の文字が抽出されます。 substring() メソッドは、指定された位置間の文字列から文字を抽出します。
次の出力は、文字列の 2 番目と 4 番目の位置の間にある抽出された部分文字列を表示します。

例 5: R の Paste() 関数を使用して文字列を連結する
R の past() 関数は、区切り文字を区切って指定された文字列を連結する文字列操作にも使用されます。
msg1 <- 'コンテンツ'msg2 <- '書き込み中'
ペースト(msg1, msg2)
ここでは、「msg1」変数と「msg2」変数にそれぞれ文字列を指定します。次に、R の past() メソッドを使用して、指定された文字列を 1 つの文字列に連結します。 past() メソッドは、strings 変数を引数として受け取り、文字列間にデフォルトのスペースが入った単一の文字列を返します。
past() メソッドを実行すると、出力はスペースを含む単一の文字列を表します。

例 6: R の Substring() 関数を使用して文字列を変更する
さらに、次のスクリプトを使用して substring() 関数を使用して部分文字列または任意の文字を文字列に追加することによって、文字列を更新することもできます。
str1 <- 'ヒーロー'部分文字列(str1, 5, 6) <- 'ic'
cat(' 変更された文字列:', str1)
「str1」変数内に「Heroes」文字列を設定します。次に、サブストリングの「開始」インデックス値と「停止」インデックス値とともに「str1」が指定された substring() メソッドをデプロイします。 substring() メソッドには、指定された文字列の関数内で指定された位置に配置される「iz」サブ文字列が割り当てられます。その後、更新された文字列値を表す R の cat() 関数を使用します。
文字列を表示する出力は、substring () メソッドを使用して新しいもので更新されます。

例 7: R の Format() 関数を使用して文字列をフォーマットする
ただし、R での文字列操作操作には、それに応じた文字列のフォーマット設定も含まれます。このために、文字列を整列させて特定の文字列の幅を設定できる format() 関数を使用します。
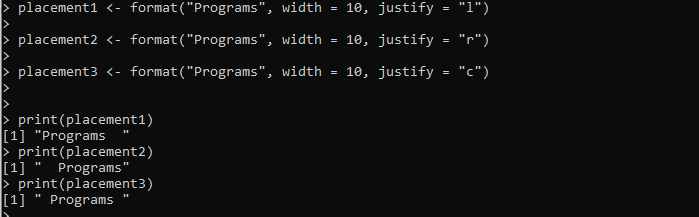
Placement1 <- format('プログラム', width = 10, justify = 'l')place2 <- format('プログラム', width = 10, justify = 'r')
placement3 <- format('プログラム', width = 10, justify = 'c')
印刷(配置1)
印刷(配置2)
印刷(配置3)
ここでは、format() メソッドで提供される「placement1」変数を設定します。フォーマットする「プログラム」文字列を format() メソッドに渡します。幅が設定され、「justify」引数を使用して文字列の配置が左に設定されます。同様に、さらに 2 つの変数「placement2」と「placement2」を作成し、format() メソッドを適用して、指定された文字列をそれに応じてフォーマットします。
出力には、次の図の同じ文字列に対して、左揃え、右揃え、中央揃えを含む 3 つの書式設定スタイルが表示されます。
例 8: R で文字列を小文字と大文字に変換する
さらに、次のように to lower() 関数と toupper() 関数を使用して、文字列を小文字と大文字に変換することもできます。
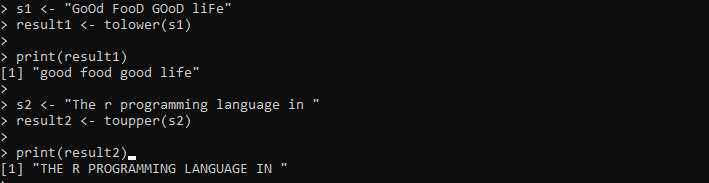
s1 ←「グッドフードグッドライフ」result1 <- to lower(s1)
印刷(結果1)
s2 <- 'r プログラミング言語'
result2 <- toupper(s2)
印刷(結果2)
ここでは、大文字と小文字を含む文字列を指定します。その後、文字列は「s1」変数に保持されます。次に、to lower() メソッドを呼び出し、その中に「s1」文字列を渡し、文字列内のすべての文字を小文字に変換します。次に、「result1」変数に保存されている to lower() メソッドの結果を出力します。次に、すべての小文字を含む別の文字列を「s2」変数に設定します。 toupper() メソッドをこの「s2」文字列に適用して、既存の文字列を大文字に変換します。
出力には、次の図のように、指定された大文字と小文字の両方の文字列が表示されます。
結論
私たちは文字列操作と呼ばれる文字列を管理および分析するさまざまな方法を学びました。文字列から文字の位置を抽出し、異なる文字列を連結して、文字列を指定された大文字と小文字に変換しました。また、文字列を操作するために、文字列の書式設定、文字列の変更、その他のさまざまな操作がここで実行されます。