データベース管理者として、私たちはデータベースのパフォーマンスを向上させるツールと方法に夢中になる必要があります。
PostgreSQL では、EXPLAIN ANALYZE コマンドにアクセスして、特定のデータベース クエリの実行計画とパフォーマンスを分析できます。このコマンドは、データベース エンジンがクエリを処理する方法に関する詳細情報を返します。これには、実行された操作のシーケンス、推定クエリ コスト、実行タイミングなどが含まれます。
次に、この情報を使用してデータベース クエリを特定し、潜在的なパフォーマンスのボトルネックを特定して修正できます。
このチュートリアルでは、PostgreSQL で EXPLAIN ANALYZE コマンドを使用してクエリのパフォーマンスを表示および最適化する方法について説明します。
PostgreSQL の説明分析
コマンドは非常に簡単です。まず、分析するクエリの先頭に EXPLAIN ANALYZE コマンドを追加する必要があります。
コマンドの構文は次のとおりです。
EXPLAIN ANALYZE <ターゲットクエリ>コマンドを実行すると、PostgreSQL は指定されたクエリに関する詳細な出力を返します。
EXPLAIN ANALYZE クエリ出力の理解
前述したように、EXPLAIN ANALYZE コマンドを実行すると、PostgreSQL はクエリ プランと実行統計の詳細なレポートを生成します。
出力は、有用な情報を含む一連の列で構成されます。結果として得られる列は、それぞれの意味とともに示されています。
クエリプラン – この列には、指定されたクエリの実行計画が表示されます。実行プランとは、クエリを正常に完了するためにデータベース エンジンが実行する一連の操作を指します。
プラン – 2 番目の列は PLAN 列です。これには、実行計画の各操作またはステップのテキスト表現が含まれます。ここでも、各操作は操作の階層を示すためにインデントされています。
総費用 – 合計コスト列は、クエリの推定合計コストを表します。コストは、データベース クエリ プランナーが最適な実行計画を決定するために使用する相対的な尺度を指します。
実際の行 – この列には、クエリ実行の各ステップで処理される正確な行数が表示されます。
実際の時間 – この列には、各操作にかかった実際の時間が表示されます。これには、操作の実行時間とリソースに費やされた時間の両方が含まれます。
計画時間 – この列は、クエリ プランナーが実行プランを生成するのにかかる時間を示します。これには、クエリの最適化とプランの生成にかかる合計時間が含まれます。
実行時間 – この列には、クエリの実行にかかった合計時間が表示されます。これには、計画に費やした時間やクエリの実行時間も含まれます。
PostgreSQL EXPLAIN ANALYZE の例
EXPLAIN ANALYZE ステートメントの基本的な使用例をいくつか見てみましょう。
例 1: Select ステートメント
EXPLAIN ANALYZE ステートメントを使用して、PostgreSQL での単純な選択ステートメントの実行を示してみましょう。
前のステートメントを実行すると、次のような出力が得られるはずです。
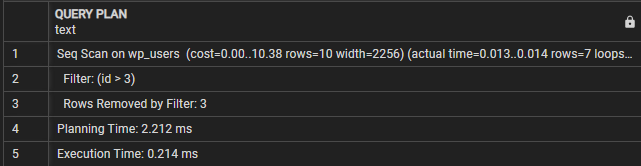
クエリプラン-------------------------------------------------- -----------------
wp_users での Seq Scan (コスト = 0.00..10.38 行 = 10 幅 = 2256) (実際の時間 = 0.009..0.010 行 = 7 ループ = 1)
フィルター: (id > 3)
フィルタによって削除された行: 3
計画時間: 0.995 ミリ秒
実行時間: 0.021 ミリ秒
(5行)
この場合、クエリ プラン セクションに、クエリが wp_users テーブルに対して順次スキャンを実行することが示されていることがわかります。フィルター行は、結果の行をフィルターするために使用される条件を示します。
次に、「フィルターによって削除された行」が表示され、フィルター条件によって削除された行の数が表示されます。
最後に、実行時間はクエリの合計実行時間を示します。この場合、クエリには 0.021 ミリ秒かかります。
例 2: 結合の分析
SQL 結合を含む、より複雑なクエリを考えてみましょう。このために、Pagila サンプル データベースを使用します。デモンストレーションの目的で、サンプル データベースをダウンロードしてマシンにインストールできます。
次のように単純な結合を実行できます。
Explain 分析 SELECT f.title、c.nameフィルムfから
JOIN film_category fc ON f.film_id = fc.film_id
JOIN カテゴリ c ON fc.category_id = c.category_id;
指定されたクエリを実行すると、次のような出力が表示されるはずです。
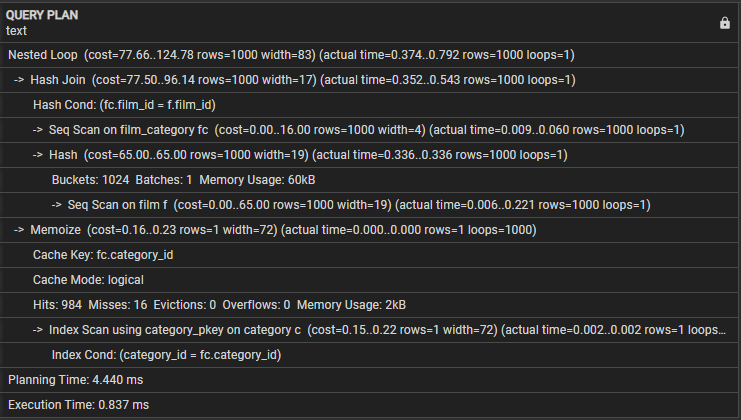
次のクエリ プランを検討してみましょう。
- ネストされたループ – これは、結合がネストされたループ結合戦略を使用することを示します。
- ハッシュ結合 – この操作は、ハッシュ結合アルゴリズムを使用して、film_category テーブルと film テーブルを結合します。この操作のコストは 77.50、推定行数は 1000 行です。ただし、この操作に実際にかかる時間は 0.254 ~ 0.439 ミリ秒で、1000 行が取得されます。
- Hash Cond – これは、結合条件がハッシュ結合を使用して、film テーブルの film_id 列と film_category 列を照合することを示します。
- film_category のシーケンシャル スキャン – この操作は、film_category テーブルに対して、コスト 16.00、推定 1000 行のシーケンシャル スキャンを実行します。この操作に実際にかかる時間は 0.008 ~ 0.056 ミリ秒で、1000 行が取得されます。
- フィルムのシーケンシャル スキャン – クエリは、この操作で結果として得られる推定コストと実際のコストと行を使用して、フィルム テーブルに対してシーケンシャル スキャンを実行します。
- Memoize – この操作は、後で使用できるように、film_category テーブルと film テーブルの間の結合の結果をキャッシュします。
- キャッシュ キー – これは、メモ化に使用されるキャッシュ キーが film_category の category_id 列に基づいていることを示します。
- キャッシュ モード – これは、クエリが論理キャッシュ モードを使用することを示します。
- ヒット、ミス、エビクション、オーバーフロー – 3 行は、実行中のキャッシュ、ヒット、ミス、エビクション、オーバーフローの数に関する統計を示します。このブロックには、クエリ実行中のメモリ使用量も含まれます。
- category_pkey を使用したインデックス スキャン – これは、主キー インデックスを使用してカテゴリ テーブルに対してインデックス スキャンを実行する操作を示します。
- インデックス条件 – これは、インデックス スキャンがカテゴリ テーブルの category_id 列と一致する条件に基づいていることを示します。
- 計画時間 – この行はクエリ計画に要した時間を示しています (3.005 ミリ秒)。
- 実行時間 – 最後に、この行はクエリの合計実行時間を示しており、0.745 ミリ秒です。
ほら、ありますよ! PostgreSQL での単純な結合の実行に関する詳細情報。
結論
PostgreSQL の EXPLAIN ANALYZE ステートメントの能力と使用法を発見しました。 EXPLAIN ANALYZE ステートメントは、クエリの分析と最適化のための強力なツールです。このツールを使用して、効率的でリソース消費量の少ないクエリを構築します。