パンダは非常に頻繁に使用されるため、できることよりもできないことを列挙する方が役立つ場合があります。データは実質的にこのツールに保存されます。 Pandas は、データをクリーニング、変換、分析することで、データについて学習するのに役立ちます。 「ラムダ」は、通常の言語で関数を定義する別の方法です。 「ラムダ」を利用して、関数を直接定義することができます。これは、Python コードの 1 つの文を使用して関数をデータに適用できることを意味します。式は複数のパラメーターを取ることができますが、「ラムダ」関数は 1 つに制限されています。式が評価され、結果が与えられます。 Python の Pandas は、「ラムダ」関数を利用して、さまざまなデータ研究の問題に対処します。 pandas DataFrame では、行と列の両方に「ラムダ」関数を使用できます。
「ラムダ」は、スケーラビリティの高いテクノロジー企業でお客様のプログラムを実行し、すべてのコンピューター資産管理を管理します。これには、更新プログラムの展開、容量のプロビジョニング、自動スケーリング、コードの分析と記録、およびサーバーと運用のメンテナンスが含まれます。ジョイントが1つだけの小容量はパンダの「ラムダ」機能。 「ラムダ」の能力は、名前が付けられていない状況でも同様に機能します。 「Lambda」は関数のキーワードを表します。実装する必要がある関数の本体は、2 番目の x で示されます。キーワードは「lambda」でなければならず、必須ですが、引数と本体は状況によって異なる場合があります。ラムダ関数を使用すると、関数オブジェクトを返すことができます。
ラムダ関数の構文:

例 1: DataFrame を使用して、assign() メソッドを適用することにより新しい列に対して Lambda メソッドを実行する
「ラムダ」アプローチは、さまざまな情報処理の問題に取り組むために Pandas によって使用されます。簡単な関数である「Lambda」メソッドは、匿名で使用することもできます。つまり、名前は必要ありません。 「ラムダ」メソッドは、最小限のプログラムを作成し、単純な問題を解決するために使用できます。高階関数をサポートする言語では、「ラムダ」式または「ラムダ」手法は、変数に割り当てたり、引数として渡したり、関数呼び出しから取得したりできる単なる命令のチャンクです。それらは長い間プログラミングのコンポーネントでした。この記事の最初の例から始めて、コード実行の基本的な条件は、必要なライブラリのロードです。 「パンダ」ライブラリは、私たちが必要としているものです。それをロードするには、「pandas を pd としてインポート」という行を作成する必要があります。ここで、データ フレームを作成します。
この例では、データ フレームは「学生」と呼ばれます。次に、データ フレームに 2 つの列が追加されます。最初の列の名前は「名前」、2 番目の列の名前は「マーク」です。 2 つの列のそれぞれにいくつかの値が含まれています。最初の列「Alvin」、「Watson」、「Thomas」、「Noah」には次の値があり、2 番目の列「Marks」には値があります。 「400」、「360」、「430」、「290」があります。これで、「pd.DataFrame」を使用して DataFrame が生成されます。
次に、コードの大部分に到達します。ここでは、「assign()」メソッドを「ラムダ」とともに使用して、新しい単一の列を構築します。 「Lambda」関数は、「dataframe.assign()」メソッドを通じて 1 つの列だけに適用されます。ラムダは、通常の言語で関数を記述する追加の方法です。ラムダを使用すると、関数を直接定義できます。これは、1 行の Python コードを使用して関数を特定のデータに適用できることを意味します。次に、「assign()」メソッドを使用して、データフレームに新しい列「Percentage」を割り当てます。
「マーク」列には「ラムダ」手順が使用されました。学生のパーセンテージは Lambda 関数を使用して計算され、「パーセンテージ」という新しい列に保持されます。 「ラムダ」を使用してパーセンテージを決定するために使用する式は、「500 に 100 を掛けたマークまたは合計マーク」です。これにより、学生の正確なパーセンテージが生成され、データフレームの「パーセンテージ」列に表示されます。 「print(dataframe)」は、データフレームを画面に表示します。
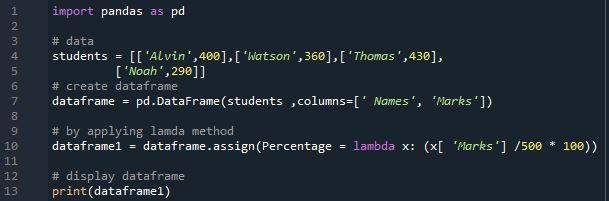
このコードの結果を表示できます。この画像には、3 つの列を持つデータフレームが表示されます。最初の列には生徒の名前が含まれ、2 番目の列には生徒の成績が含まれます。 「assign()」メソッドと「ラムダ」関数を利用して 3 番目の列の「パーセンテージ」を構築することにより、生徒のパーセンテージを決定し、それらのパーセンテージを 3 番目の列に追加できます。データ フレームでは「パーセンテージ」と名付けられています。 .数式を使用してパーセンテージ列で得られた値は、「80」、「72」、「86」、および「58」でした。このデータフレームでは、インデックスのサイズは「4」です。
例 2: 複数の列で assign() メソッドを使用する Lambda 関数を実装する
Pandas DataFrame の assign() 手法により、多くの列で Lambda 関数を使用できます。ラムダ関数やソート関数など、新しい関数が必要になるたびに、自由に追加できます。 Pandas データ フレームの列と行は、どちらもラムダ関数で処理できます。このシナリオでは、データフレームを生成することから始めます。 「学生の結果」はデータフレームの名前です。このデータフレームには 4 つの列があります。最初の列は「名前」です。 2列目は「Python」です。 3 番目の列の名前は「Data_structure」です。 4番目の名前は「Calculus」です。
これらの列には、いくつかの値がリストされています。 「名前」列には、生徒の名前「ウィロー」、「アリス」、「エドワード」、「アメリア」のリストがあります。ニシキヘビの「96」、「40」、「98」、「98」のマーキングは、2 列目に保持されている値によって表されます。 3 列目の値は「86」、「56」、「73」、「90」で、4 列目は「90」、「33」、「88」、「78」です。 「pd.DataFrame」を使用してデータフレームを生成します。
次に、「assign」メソッドを使用してデータ フレームに新しい列を追加します。新しい列のタイトルは「合計点」です。新しい列の名前は「Total_marks」です。全体的な評価を得るために、Python、データ構造、微積分など、いくつかの対象列で「Lambda」関数を使用しました。この関数は、3 つの科目すべてのスコアを合計し、「Total_marks」列に表示します。 「print(dataframe)」は、最終的にデータフレームを画面に表示します。
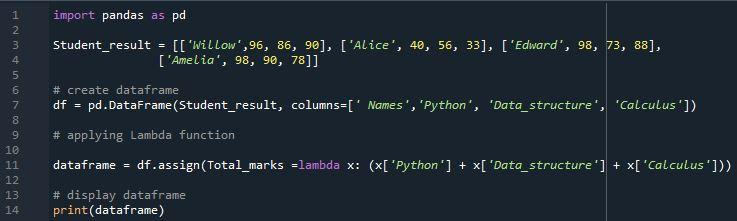
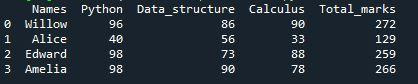
今回は、この成果を得ることができました。 「Lambda」関数は、複数の列で使用すると優れた結果をもたらします。 「assign」メソッドを使用して新しい列「Total_marks」をデータフレームに割り当て、その列に学生の合計結果を表示できるようにします。最後に、「合計点数」列に 3 つの科目すべての合計結果が表示されていることがわかります。合計点の列の数値は、ラムダ「272」、「129」、「259」、「266」を使用して 3 つの列の値を加算することによって計算されました。
結論
Python プログラミング言語では、ラムダ関数は名前のない 1 行の関数で、1 つの引数と無限の数のパラメーターを受け取ります。彼らはいくつかの議論をするかもしれませんが、そのうちの1つだけが表現されます。ラムダ作業は、任意の要素に割り当てられる可能性があり、アサーションを含めることができない容量オブジェクトを復元します。最初のケースでは、パーセンテージを決定するために「ラムダ」が使用され、2 番目の例では、学生の「合計点」が計算されました。この記事では、典型的な「ラムダ」関数の構文、使用法、および例について説明します。