「「パンダ」は、データ中心の Python パッケージの優れたエコシステムにより、データの分析を実行するための優れた言語です。これにより、両方の要因の分析とインポートが容易になります。標準偏差は、平均から導き出された「典型的な」偏差です。データフレームの元の測定単位を返すため、よく使用されます。パンダは、標準偏差の計算に std() を使用しました。標準偏差は、行または列の形式でデータフレームにある特定の値から計算できます。パンダの標準偏差が使用されるすべての可能な方法を実装します。コードの実装には、python に適した環境で記述されているツール「spyder」を使用します。」
構文
「df.std ( ) 」
次の構文は、データフレームの標準偏差を計算するために使用されます。データフレームの「df」は「データフレーム」の略です。標準偏差は何をしますか?必要なデータがどの程度拡張されているかを測定します。高い値が拡張されるほど、標準偏差が高くなります。
戻る
要件に基づいてレベルが指定されている場合、パンダの標準偏差はデータフレームを返します。
関数「std()」は、パンダの標準偏差を計算する際に「df」の「NaN」値を自動的に無視することに注意してください。 「NaN」は「数値ではない」と説明できます。これは、特定のものに値が割り当てられていないことを意味します。
以下は、パンダの標準偏差の例で実行されるメソッドです。
-
- 単一の列でのパンダの標準偏差計算。
- 複数の列でのパンダの標準偏差計算。
- すべての数値列のパンダ標準偏差計算。
- 軸を使用したパンダの標準偏差 = 1。
- 軸 = 0 を使用したパンダの標準偏差。
Pandas で標準偏差を計算するためのデータフレームを作成する
まず、「スパイダー」ソフトウェアを開きます。 pandas ライブラリを pd としてインポートします。 「22」、「10」、「11」、「16」、「12」、「45」のポイントを持つ「x」、「y」、「z」の用語を持つスコアボードで構成されるデータフレームを作成します。 」、「36」、「40」。アシスト値は「8」、「9」、「13」、「7」、「22」、「24」、「4」、「6」で、リバウンドの値は「17」、「 14」、「3」、「5」、「9」、「8」、「7」、「4」。
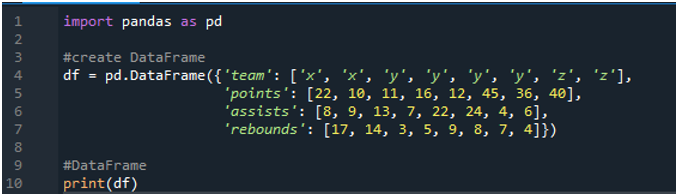
コードで割り当てられた値に従って、作成されたデータフレームが表示されます。

例 # 01: 1 つの列での Pandas 標準偏差の計算
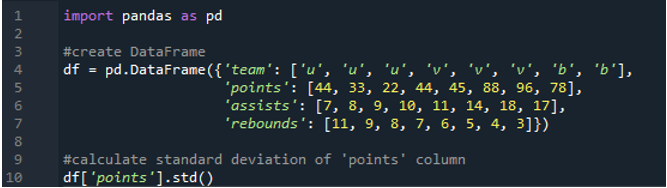
この例では、pandas データフレームの 1 つの列の標準偏差を計算します。データフレームには、チームの値が「u」、「v」、および「b」であり、ポイントは「44」、「33」、「22」、「44」、「45」、「88」、「96」です。 」と「78」。アシストの値は「7」、「8」、「9」、「10」、「11」、「14」、「18」、「17」で、リバウンドの値は「11」、「 9」、「8」、「7」、「6」、「5」、「4」、「3」。列「ポイント」がデータフレームから選択され、単一列の標準偏差が計算されます。
出力は、列「ポイント」について計算された標準偏差を示しています。

例 # 02: 複数の列での Pandas 標準偏差の計算
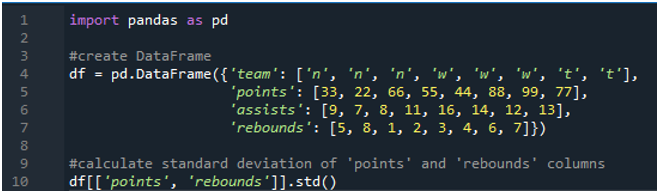
この例では、パンダの標準偏差計算を複数の列で実行します。このデータフレームでは、データはスポーツ スコアボードのデータであり、チームの値は「n」、「w」、「t」で、スコアは「33」、「22」、「66」、「55」です。 「44」、「88」、「99」、「77」。アシストは「9」、「7」、「8」、「11」、「16」、「14」、「12」、「13」、リバウンドは「5」、「8」、「1」、「 2」、「3」、「4」、「6」、「7」。ここでは、データフレームに適用された関数 std() を使用して、2 つの列「ポイント」と「リバウンド」の標準偏差を計算します。
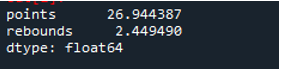
ご覧のとおり、出力は、標準偏差がポイント列で 26.944387、リバウンド列でそれぞれ 2.449490 になったことを示しています。
例 # 03: すべての数値列の Pandas 標準偏差の計算
これで、単一行と複数行の標準偏差を計算する方法を学びました。データフレーム内のすべての列名を指定してデータフレーム全体を計算したくない場合はどうすればよいでしょうか?これは、パンダの標準偏差の単純な関数を実装して、結果に含まれる完全なデータフレーム全体を計算するだけで可能です。ここでのデータフレームは、スコア値が「33」、「36」、「79」、「78」、「58」、「55」の「l」、「m」、「o」で構成され、2 つのチームが同じスコアを付けています。それが「25」です。アシストは「1」「2」「3」「4」「6」「9」「5」「7」、リバウンドは「14」「10」「2」 、「5」、「8」、「3」、「6」、「9」。パンダの「std()」関数を使用して、データフレーム内のパンダによるすべての標準列偏差を計算できます。
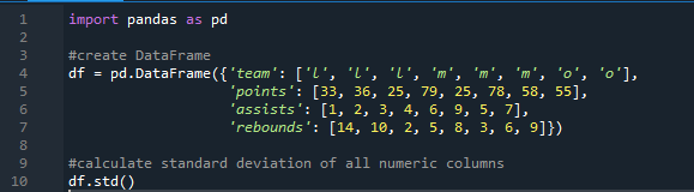
ディスプレイには、以下に示す「df」全体の計算された標準偏差が表示されます。また、パンダは最初の列である「チーム」の標準偏差を計算していないこともわかります。これは数値列ではないためです。
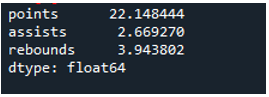
例 # 04: 軸 = 0 を使用したパンダの標準偏差
この例では、データフレームにはスポーツのチームが「g」、「h」、および「k」として追加のデータが含まれています。ここでは、軸を「0」として標準偏差を計算します。これは、パンダの標準偏差で使用されるパラメーターです。この引数は、データフレームの列単位の標準偏差を計算します。
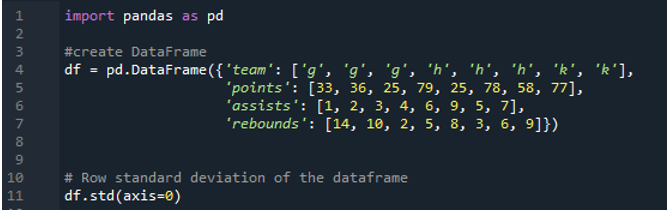
次の出力は、計算された標準偏差の列に結果を表示します。ポイント列の計算標準偏差は「24.0313062」、アシスト列の計算標準偏差は「2.669270」、リバウンド列の計算標準偏差は「3.943802」です。
例 # 05: 軸 = 1 を使用したパンダの標準偏差
ここでは、「1」として割り当てられた軸パラメーターを使用して、パンダの標準偏差を計算します。軸「1」はどのような違いをもたらすことができますか? 「1」軸引数は、データフレーム内の数値の行単位の標準偏差を計算します。データフレームには、「s」、「d」、「e」の 3 つのチームがあり、チームのポイント、チームのアシスト、チームのリバウンドとして作成されたデータ列が追加されています。方向はすべて、データフレームで異なる値に割り当てられます。この軸パラメーターはゲーム チェンジャーのようなものです。時間までに、データを列に配置したい場所に加えて、実行された標準偏差の計算ポイントに取り組む必要があります。
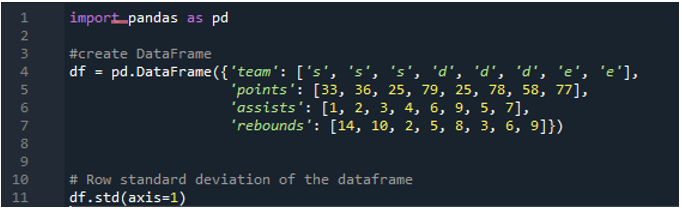
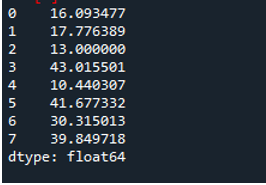
次の出力は、データフレームの行で計算された標準偏差を示しています。
結論
パンダの標準偏差は非常に技術的な関数であり、パンダのデータフレームの熱意協定の標準偏差を見つけるため、非常に有益な関数です。この社説では、パンダの標準偏差を計算する方法を検討しました。標準偏差と複数の列の単一列の計算を行い、データフレーム全体の標準偏差も一緒に計算しました。すべての戦略は、一貫して使用され、望ましい結果が得られる限り、うまく機能します。