Pandas は、データを迅速に評価することを目的とした幅広い重要な側面と指示へのアクセスを許可します。 Pandas DataFrame を HTML テーブルに変換するプロセスを利用します。開発者とユーザーは、Python DataFrame を HTML ソース コードに統合する必要があります。彼らは、この Pandas 拡張機能を使用して、Pandas to HTML テクニックを使用して、この目的のためにデータを HTML ファイルに簡単に変換します。方法論を説明するために、実装に「Spyder」ツールを使用して、各実装とともに段階的に理解しやすくします。
Pandas でローカル HTML ファイルを解析する場合は、タグの名前とテキスト ファセットを使用します。ファイルのタグ ul のコードと組み合わせて、タグのタイトルとコンテンツをカスタマイズする場合があります。 Pandas の URL から HTML ファイルを取得する場合は、スキャン機能を呼び出すためのウェブ URL パラメータを含むいくつかの手順を実行する必要があります。次に、データベース オブジェクトからの閲覧を可能にする変数を参照し、URL の内部全体を data 変数に読み込んでコードを実行し、データを HTML 形式で出力します。
Pandas から HTML への構文:

例: Pandas DataFrame のレンダリングを HTML コードとテーブルに表示する
HTML Web ページでは、Pandas in Python は Pandas DataFrame を HTML テーブルに変更できます。 Pandas DataFrame は、「pandas.DataFrame.to html()」メソッドを使用して実行されます。例を見て、Python DataFrame を HTML ソース コードに変換する手順について説明しましょう。これを実現するには、最終的に HTML にレンダリングされる DataFrame を最初に設計する必要があります。 Pandas の哲学を Python コードに適用するために、Pandas ライブラリを「pd」としてインポートします。
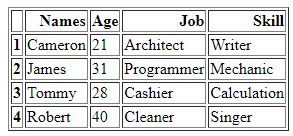
DataFrame の「Members」には、メンバーの情報に関連する辞書と、「Names」、「Age」、「Job」、「Skill」の 4 つの変数が宣言されています。最初の行には、「名前」が「キャメロン」、「年齢」が「21」、「仕事」が「建築家」、「スキル」が「作家」というデータが格納されています。このようにして、割り当てる DataFrame 初期化値の 2 行目は、それぞれの列の「James」、「31」、「Programmer」、「Mechanic」です。このように、もう一方の辞書には、「Tommy」、「28」、「Cashier」、および「Calculation」がデータとして含まれています。そして、DataFrame に割り当てる最後の行には、「Robert」というデータが「Names」の値として、「40」が「Age」の割り当て値として、「Cleaner」が「Job」として、「Singer」が'スキル'。
これ以降、DataFrame にデータを割り当てると、DataFrame が 4 つの行を持つ可能性があるため、「1」から「4」までの「インデックス」範囲も提供します。その後、「pd.dataframe()」関数を使用して、データとインデックス番号をマージします。最後に、「print()」関数を使用して DataFrame を表示します。
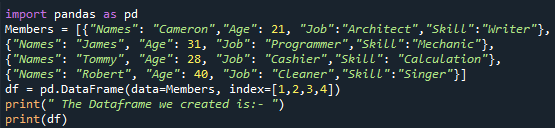
これで、作成した DataFrame の「メンバー」が表示されます。ここでは、HTML ソースに変換した DataFrame の単純な表示であることがわかります。 「Names」、「Age」、「Job」、「Skill」の 4 つの列だけがあり、コードで DataFrame に割り当てた同様のデータがすべて含まれています。その行には、「1」、「2」、「3」、および「4」のインデックス番号があります。このステップでは、DataFrame の「メンバー」を作成していることがわかります。 DataFrame を作成したら、さらに実装を進めます。
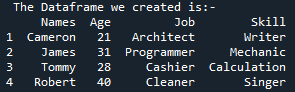
これは、DataFrame の「メンバー」を HTML コードに変換する方法を確認するステップです。 DataFrame を HTML に進化させる Python の DataFrame to html() メソッドの巧妙さを理解する時が来ました。 html() 関数は DataFrame 全体を変更し、DataFrame の各行が HTML テーブル内の個別のシーケンスになるようにします。この目的のために、変数「html」を宣言し、「df.to_html()」関数を使用して格納し、DataFrame 全体を Html コードに変換します。 「df.to_html()」関数の実装後、「html」ディレクトリに「print()」関数を適用します。

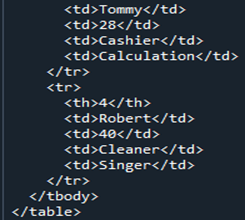
次に、Pandas DataFrame の「Members」から変換された HTML コードを見てみましょう。これは、任意の DataFrame を HTML ソース コードに変換する方法であり、表の境界線が「1」であるすべてのタグを含む HTML コードで DataFrame 全体を記述します。列名は HTML 要素のテーブル ヘッドとして「」の下にカプセル化され、DataFrame 全体が「 DataFrame には 4 つの行があったため、「 ここで、HTML コードを現在実行中のディレクトリに「.html」拡張子とともに「signal」として保存します。 「open()」関数を使用して、ファイルの場所の名前を「file=open(“signal.html”, “w”)」として決定します。場所のキーワード「w」は、ファイルを表示して HTML 形式で開示するために保存するため、「.write()」関数を使用し、ファイルの「close()」関数とともに Pandas コードを終了します。 HTML に変換し、同じディレクトリにブラウザーのインターフェイスを提供する「.html」ファイル拡張子と共に保存するために使用する、より単純なケースの大部分について説明します。 DataFrame の「メンバー」を HTML に変換した後、最初に同じディレクトリの場所に保存する HTML コードを取得します。 HTML ソース コードを取得したら、ブラウザーで HTML ソース ファイルを開くことにより、Web 拡張機能と共にそれを開くことができます。ブラウザー ページに出力が HTML テーブルとして表示されていることがわかります。 表の出力からわかるように、境界線のサイズは「1」で、境界線に沿ったセルの間隔はありません。表には 5 つの列が表示されます。このうち、列名は「名前」「年齢」「職業」「スキル」の4つです。 「1」のインデックス番号について言えば、列「名前」に「キャメロン」、「年齢」に「21」、「仕事」に「建築家」、「スキル」に「作家」が含まれています。表中の「2」のインデックス番号は、「名前」の「ジェームス」、「年齢」の「31」、「仕事」の「プログラマー」、「スキル」の「メカニック」を示しています。 「名前」列の「3」インデックスは、「トミー」、「年齢」に「28」、「仕事」に「キャッシャー」、ブラウザページの「スキル」列に「計算」を示しています。表の最後の行のインデックス「4」は、「名前」の「ロバート」、「年齢」の「40」、「仕事」の「掃除人」、「スキル」の「歌手」を示しています。 DataFrame をこの記事の HTML ソース コードに変更するために、最初に「Members」という名前でアセンブルしました。 DataFrame を HTML コードにレンダリングするときは、「html = df.to html()」関数を使用します。 HTML テーブルを表示する場合、同じディレクトリに保存されている「file = open(“signal.html”, “w”)」ディレクトリとファイルの場所「signal.html」を使用します。これにより、Pandas DataFrame を HTML ソース コード ファイルに変換し、テーブルで表示することができました。」HTML 要素に変更されます。さらに、DataFrame の各行は、HTML テーブルのタグ「
」とともに行に変換されます。 「」は、表の行を説明するタグ「 」とともに「CSS」の一部を使用します。
」は終了タグと共に 4 回使用されます。 HTML でわかるように、それぞれの HTML コードに開始タグと終了タグの両方が必要です。すべてのデータまたは DataFrame は、開始タグ「 」と「
」と終了タグで囲まれています。 HTML コード全体の残りの部分には、DataFrame と同じデータが含まれており、テーブルを形成するために必要なタグとともに単純な HTML ソース コードに変換されているだけです。
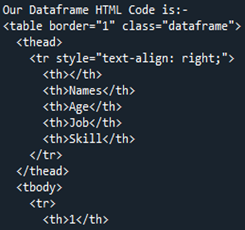
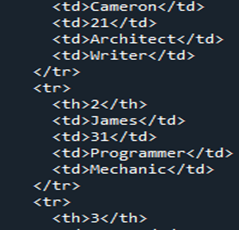

結論