例 1:
説明する図と MongoDB シェルでの「$max」演算子の仕組みから始めて、「data」という名前のコレクションを作成する必要があります。このコレクションを作成するには、「作成」命令を使用せずにいくつかのレコードを直接追加する必要があります。コレクションを作成し、そこにレコードを追加するには、insert 命令で十分です。クエリで「insertMany」関数を使用して、それぞれが異なるタイプの 4 つのフィールドを持つ 4 つのレコードを追加します。
テスト > db.data.insertMany ( [ { 「イド」 : 1 、 '名前' : 「ブラボー」 、 '給料' : 65000 、 '年' : 44 } 、... { 「イド」 : 2 、 '名前' : 「スティーブン」 、 '給料' : 77000 、 '年' : 55 } 、
... { 「イド」 : 3 、 '名前' : 「マリア」 、 '給料' : 42000 、 '年' : 27 } 、
... { 「イド」 : 4 、 '名前' : 「ホーキン」 、 '給料' : 58000 、 '年' : 33 } ] )
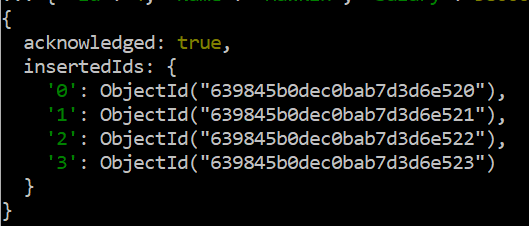
挿入コマンドが成功し、レコードが追加されたことを示す出力メッセージが表示されます。
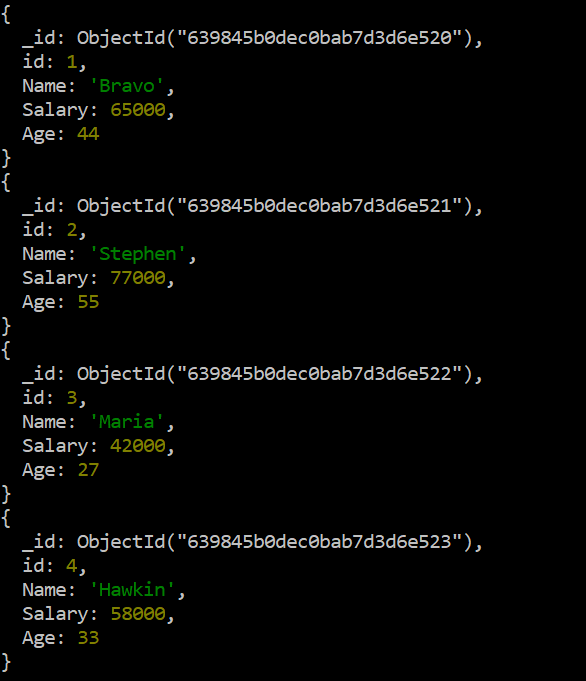
MongoDB の「データ」コレクションにレコードを挿入したら、シェルでそれらのレコードを確認します。したがって、MongoDB Cli で「find()」関数命令を実行し、続いて「forEach()」関数を実行し、printjson 引数を使用して結果を JSON 形式で表示します。シェルに表示される結果は、次の出力イメージに示されているコレクション内の合計 4 つのドキュメントを示しています。
テスト > デシベル。データ。検索 ( ) .forEach ( printjson )
MongoDB の更新コマンドで「$max」演算子を使用して、既に挿入されているレコードを変更してみましょう。したがって、ここでは updateOne() を使用して、「id」フィールドの値が「2」である特定のレコードなど、「data」コレクションの 1 つのレコードのみを変更します。 「$max」演算子が「data」コレクションの「Salary」フィールドに適用され、「Salary」フィールドの値が 55000 より大きいかどうかがチェックされます。そうでない場合は、55000 でレコードを更新します。この出力結果はレコード「2」の給与値が 55000 未満であるため、変更カウント「0」を示す updateOne() 関数クエリ。
テスト > db.data.updateOne ( { ID: 2 } 、 { 最大 $ : { 給料: 55000 } } ) 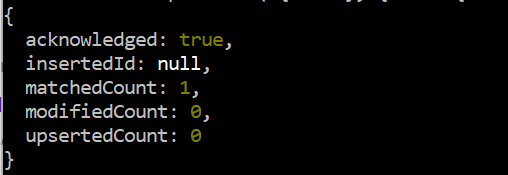
この更新の後、同じ「find()」関数クエリを試して、変更された結果を MongoDB コマンドライン シェルに表示します。しかし、「update」命令を使用する前と同じ出力が得られます。 77000 の値が 55000 より大きいため、変更はありませんでした。
テスト > デシベル。データ。検索 ( ) .forEach ( printjson ) 
少し変更して、同じ updateOne() クエリをもう一度試してみましょう。今回は、「data」コレクションの「Salary」フィールドに既に存在する「77000」の値よりも大きい値「85000」を試して、出力に違いを作ります。このクエリの「$max」演算子のためだけに比較が行われた後、「85000」の値がフィールド内の既存の「77000」の値を置き換えるため、出力は今回の変更カウント「1」を示しています。
テスト > db.data.updateOne ( { ID: 2 } 、 { 最大 $ : { 給料: 85000 } } ) 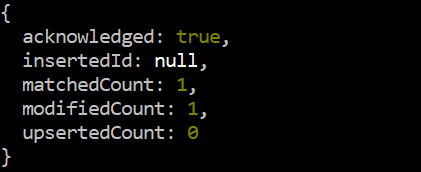
MongoDB の「$max」演算子を使用して「77000」の小さい値を「85000」の新しい値に正常に置き換えた後、最後に「db」命令で「find()」関数を使用してこの更新を確認します。正常に更新されたかどうか。出力は、このコレクションの 2 番目のレコードの「Salary」フィールドの値が完全に更新されていることを示しています。
テスト > デシベル。データ。検索 ( ) .forEach ( printjson ) 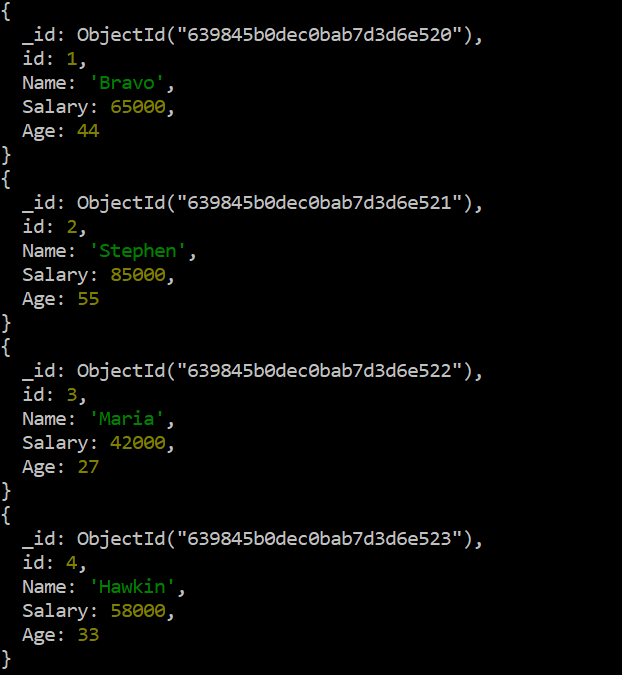
例 2:
MongoDB で「$max」演算子を使用する別の例にジャンプしましょう。今回は、同じフィールド値に重複がある場合にコレクションの一意のレコードをグループ化して表示するために、「$max」演算子を除外します。このために、「テスト」データベースの「データ」コレクションにさらに 2 つのレコードを挿入します。これらのレコードには、既に挿入されている 4 つのレコードにもある「名前」フィールドに 2 つの同じ値が含まれており、残りは異なります。レコードを挿入するには、「data」コレクションを更新するための「insertMany」関数を含む同じ「db」命令を使用します。
テスト > db.data.insertMany ( [ { 「イド」 : 5 、 '名前' : 「ブラボー」 、 '給料' : 35000 、 '年' : 4.5 } 、… { 「イド」 : 6 、 '名前' : 「ホーキン」 、 '給料' : 67000 、 '年' : 33 } ] )
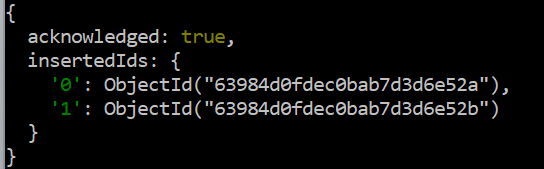
命令は正常に実行されます。
2 つの新しいレコードが追加されたので、「db」命令の同じ「find」関数とそれに続く「forEach」関数を使用してそれらを表示することもできます。次の画像の表示出力は、このコレクションの最後にある 2 つの新しいレコードを示しています。
テスト > デシベル。データ。検索 ( ) .forEach ( printjson ) 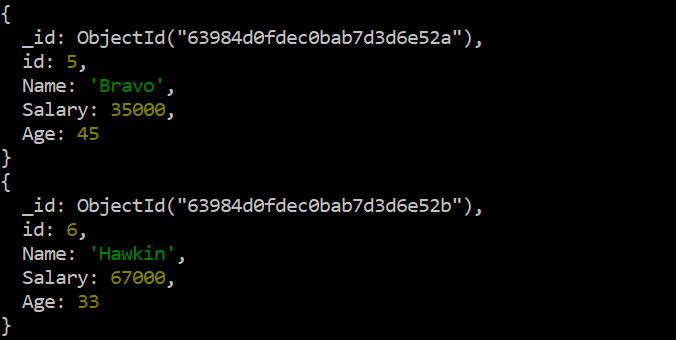
「データ」コレクションの 6 つのレコードを表示した後、集計関数を実行する準備が整いました。したがって、「集計」関数は、次の一覧にあるクエリで使用されます。この関数では、「$group」演算子を使用して、「id」フィールドと「Salary」フィールドの一意の名前に従って「data」コレクションのレコードをグループ化します。 「$max」演算子がレコードの「Salary」フィールドに適用され、表示される最大値が取得されます。このグループを表示するための「ID」として使用される「名前」フィールドの重複する名前に従って、「給与」フィールドから最大の値を取得します。合計 4 件のレコードが表示されます。最大値が表示されている間、(重複レコードからの) 最小値は無視されます。
db.data.aggregate ( [ { $グループ : { _id: ' $名前 ' 、 給料: { 最大 $ : ' $給与 ' } } } ] ) 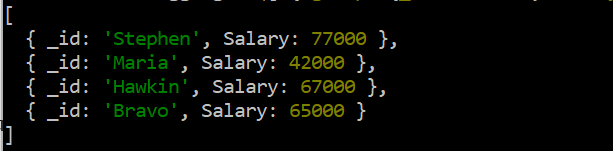
結論
このガイドの最初の段落は、MongoDB で使用される演算子、特に「$max」演算子とその MongoDB シェルでの使用の重要性を理解するのに役立ちます。このガイドには、「$max」演算子に関連する 2 つのコマンドベースの例が含まれており、その目的を示しています。 MongoDB の図を見ていくと、既存のレコードを新しい値に置き換えることや、「$max」演算子を使用してグループ化してレコードを表示することなど、データベースでいくつかの有用なトランザクションを実行できるようになります。