この記事では、Elasticsearch multi-get API を使用して、ID に基づいて複数の JSON ドキュメントをフェッチする方法について説明します。さらに、Elasticsearch では、単一の get クエリを使用して、ドキュメント ID のみを使用してインデックスからドキュメントを取得できます。
調べてみましょう。
リクエスト構文
以下は、Elasticsearch マルチ取得 API の構文です。
GET /_mget
GET /<インデックス>/_mget
マルチ取得 API は複数のインデックスをサポートしているため、ドキュメントが同じインデックスにない場合でもドキュメントを取得できます。
リクエストは、次のパス パラメータをサポートしています。
- <インデックス> – ID で指定されたドキュメントの取得元のインデックスの名前。
次のように、他のクエリ パラメータを指定することもできます。
- 好み – 優先ノードまたはシャードを定義します。
- リアルタイム – true に設定すると、操作はリアルタイムで実行されます。
- リフレッシュ – 指定されたドキュメントを取得する前に、操作でターゲット シャードを強制的に更新します。
- ルーティング – 操作を特定のシャードにルーティングするために使用される値。
- Store_fields – ドキュメントではなくインデックスに格納されているドキュメント フィールドを取得します。
- _ソース – リクエストが _source フィールドを返すかどうかを定義するブール値。
クエリには、次の値を含む本文が必要です。
- ドキュメント – 取得するドキュメントを指定します。さらに、このセクションは次の属性をサポートしています。
- _id – ターゲット ドキュメントの一意の ID。
- _索引 – 対象文書を含む索引。
- ルーティング – ドキュメントのプライマリ シャードのキー。
- _ソース – true の場合、すべてのソース フィールドが含まれます。それ以外の場合は除外されます。
- _stored_fields – 含めたい stored_fields。
- ID – 取得するドキュメントの ID。
例 1: 同じインデックスから複数のドキュメントをフェッチする
次の例は、Elasticsearch マルチ取得 API を使用して、特定の ID を持つドキュメントを Netflix インデックスから取得する方法を示しています。
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: レポート' -H 'コンテンツ タイプ: アプリケーション/json' -d'{
'ドキュメント': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
}、
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
指定されたリクエストは、指定された ID を持つドキュメントを Netflix インデックスからフェッチする必要があります。結果の出力は次のとおりです。
{'ドキュメント': [
{
'_index': 'ネットフリックス',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_バージョン': 1,
'_seq_no': 0,
'_primary_term': 1,
「見つかった」:真、
'_ソース': {
'duration': '90分',
'listed_in': 'ドキュメンタリー',
「国」:「米国」、
'date_added': '2021 年 9 月 25 日',
'show_id': 's1',
「ディレクター」:「キルスティン・ジョンソン」、
'リリース年': 2020,
'評価': 'PG-13',
'description': '彼女の父親が人生の終わりに近づく中、映画製作者のキルステン・ジョンソンは彼の死を独創的かつコミカルな方法で演出し、2 人が避けられない事態に直面するのを助けます。',
'type': '映画',
「タイトル」:「ディック・ジョンソンは死んだ」
}
}、
{
'_index': 'ネットフリックス',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_バージョン': 1,
'_seq_no': 12,
'_primary_term': 1,
「見つかった」:真、
'_ソース': {
'country': 'ドイツ、チェコ共和国',
'show_id': 's13',
'director': 'Christian Schwochow',
'リリース年': 2021,
'評価': 'TV-MA',
'description': '家族のほとんどが爆破テロで殺害された後、ある若い女性が知らず知らずのうちに自分たちを殺したグループに誘い込まれてしまいます。',
'type': '映画',
'タイトル': '私はカールです',
'duration': '127分',
'listed_in': 'ドラマ、海外映画',
'cast': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '2021 年 9 月 23 日'
}
}
]
}
以下に示すように、ドキュメント ID を単純な配列に入れることで、リクエストを簡素化することもできます。
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: レポート' -H 'コンテンツ タイプ: アプリケーション/json' -d'{
'ID': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
前のリクエストは、同様のアクションを実行する必要があります。
例 2: 複数のインデックスからドキュメントを取得する
次の例では、リクエストは、示されているように異なるインデックスから複数のドキュメントをフェッチします。
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: レポート' -H 'コンテンツ タイプ: アプリケーション/json' -d'{
'ドキュメント': [
{
'_index': 'ネットフリックス',
'_id': 'T3wnVoMBck2AEzXPytlJ'
}、
{
'_index': 'ディズニー',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
結果の出力は次のとおりです。

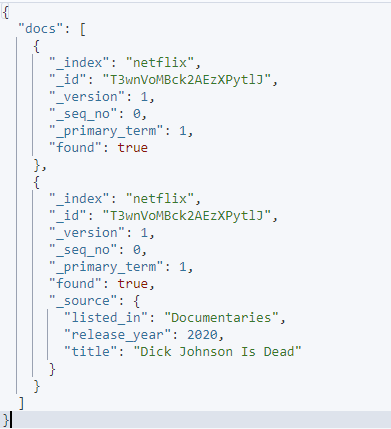
例 3: 特定のフィールドを除外する
source_include および source_exclude パラメータを使用して、特定のフィールドを特定のリクエストから除外できます。
例を次に示します。
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: レポート' -H 'コンテンツ タイプ: アプリケーション/json' -d'{
'ドキュメント': [
{
'_index': 'ネットフリックス',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': false
}、
{
'_index': 'ネットフリックス',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_ソース': {
'include': [ 'listed_in', 'release_year', 'title' ],
「除外」: [「説明」、「タイプ」、「追加日」]
}
}
]
}'
特定のリクエストでは、ソースの include および exclude を使用して、特定のドキュメントで取得するフィールドを指定します。
結果の出力は次のとおりです。
結論
この投稿では、ID に基づいてさまざまなソースから複数のドキュメントをフェッチできる Elasticsearch マルチ取得 API の操作の基本について説明しました。詳細については、他のドキュメントを自由に調べてください。
ハッピーコーディング!