コレクションの作成
インデックスを使用する前に、MongoDB に新しいコレクションを作成する必要があります。すでに 1 つのドキュメントを作成し、「ダミー」という名前の 10 個のドキュメントを挿入しました。 find() MongoDB 関数は、以下の MongoDB シェル画面に「ダミー」コレクションのすべてのレコードを表示します。
テスト> db.Dummy.find() 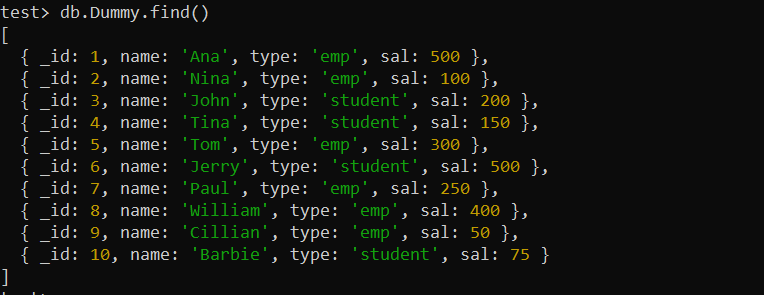
インデックス作成タイプの選択
インデックスを確立する前に、まずクエリ条件で一般的に使用される列を決定する必要があります。インデックスは、フィルタリング、並べ替え、または検索が頻繁に行われる列では適切に機能します。大きなカーディナリティ (多くの異なる値) を持つフィールドは、多くの場合、優れたインデックス作成オプションです。さまざまなインデックス タイプのコード例をいくつか示します。
例 01: 単一フィールドのインデックス
これはおそらく最も基本的な種類のインデックスであり、単一の列にインデックスを付けて、その列に対するクエリ速度を向上させます。このタイプのインデックスは、単一のキー フィールドを使用してコレクション レコードをクエリするクエリに使用されます。以下のように、検索関数内で「type」フィールドを使用してコレクション「Dummy」のレコードをクエリするとします。このコマンドはコレクション全体を調べますが、巨大なコレクションの処理には長い時間がかかる可能性があります。したがって、このクエリのパフォーマンスを最適化する必要があります。
テスト> db.Dummy.find({タイプ: 「エンプ」 })
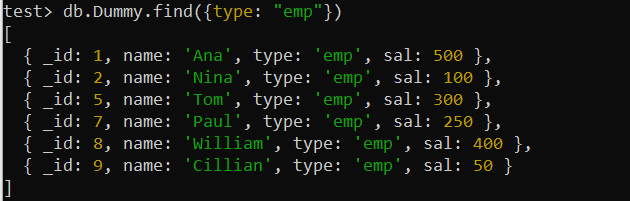
上記のダミー コレクションのレコードは、「タイプ」フィールド、つまり条件を含むフィールドを使用して検出されました。したがって、ここでは単一キー インデックスを利用して検索クエリを最適化できます。したがって、MongoDB の createIndex() 関数を使用して、「Dummy」コレクションの「type」フィールドにインデックスを作成します。このクエリを使用した図は、シェル上に「type_1」という名前の単一キー インデックスが正常に作成されたことを示しています。
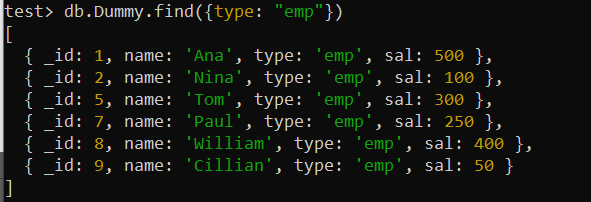
テスト> db.Dummy.createIndex({ タイプ: 1 })「type」フィールドを利用できるようになったら、find() クエリを使用してみましょう。 MongoDB はインデックスを利用して、要求された役職を持つレコードを迅速に取得できるため、インデックスが設定されているため、以前に使用されていた find() 関数よりも操作が大幅に高速になります。
テスト> db.Dummy.find({タイプ: 「エンプ」 })
例 02: 複合インデックス
特定の状況では、さまざまな基準に基づいてアイテムを探したい場合があります。これらのフィールドに複合インデックスを実装すると、クエリのパフォーマンスを向上させることができます。今回は、クエリが表示されるように、異なる検索条件を含む複数のフィールドを使用して、コレクション「Dummy」から検索するとします。このクエリは、「type」フィールドが「emp」に設定され、「sal」フィールドが 350 より大きいレコードをコレクションから検索しています。
$gte 論理演算子は、条件を「sal」フィールドに適用するために使用されています。 10 レコードで構成されるコレクション全体を検索すると、合計 2 つのレコードが返されました。
テスト> db.Dummy.find({タイプ: 「エンプ」 、サル: {$gte: 350 } }) 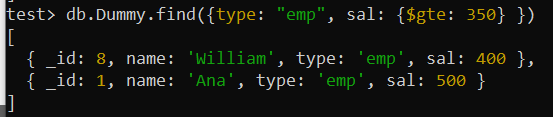
前述のクエリの複合インデックスを作成しましょう。この複合インデックスには「type」フィールドと「sal」フィールドがあります。数字「1」と「-1」は、それぞれ「type」フィールドと「sal」フィールドの昇順と降順を表します。複合インデックスの列の順序は重要であり、クエリ パターンに対応している必要があります。 MongoDB は、表示されているように、この複合インデックスに「type_1_sal_-1」という名前を付けています。
テスト> db.Dummy.createIndex({ タイプ: 1 、 意思:- 1 }) 
同じ find() クエリを使用して、「type」フィールドの値が「emp」で、「sal」フィールドの値が 350 以上であるレコードを検索すると、順序がわずかに変更されて同じ出力が得られました。前のクエリ結果と比較します。 「sal」フィールドのより大きな値のレコードが 1 位になり、上記の複合インデックスの「sal」フィールドに設定された「-1」に従って最小値のレコードが最下位になります。
テスト> db.Dummy.find({タイプ: 「エンプ」 、サル: {$gte: 350 } }) 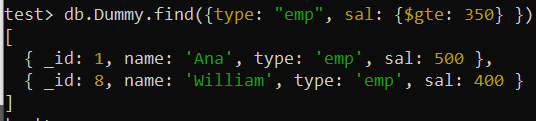
例 03: テキスト索引
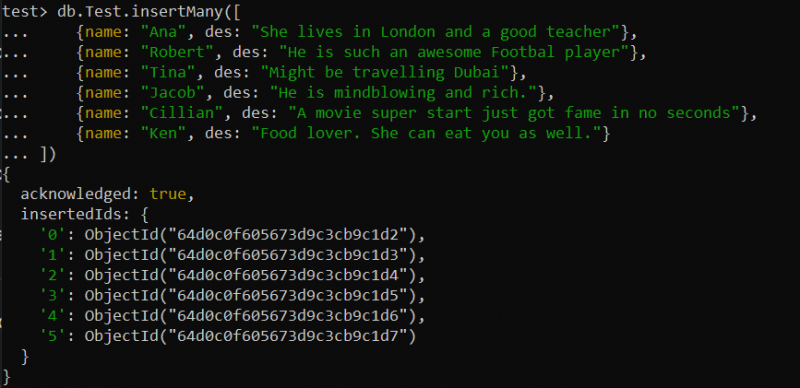
場合によっては、製品や成分などの詳細な説明など、大規模なデータ セットを処理する必要がある状況に遭遇することがあります。テキスト インデックスは、大きなテキスト フィールドで全文検索を行う場合に便利です。たとえば、テスト データベース内に「Test」という名前の新しいコレクションを作成しました。以下の find() クエリに従って、insertMany() 関数を使用して、このコレクションに合計 6 つのレコードを挿入しました。
テスト> db.Test.insertMany([{名前: 「アナ」 、そのうち: 「彼女はロンドンに住んでいて、良い先生です。」 }、
{名前: 「ロバート」 、そのうち: 「彼はとても素晴らしいフットボール選手だ」 }、
{名前: 'から' 、そのうち: 「ドバイを旅行しているかもしれない」 }、
{名前: 「ジェイコブ」 、そのうち: 「彼は驚くべき人で、お金持ちです。」 }、
{名前: 「キリアン」 、そのうち: 「映画のスーパースタートは瞬く間に名声を博しました」 }、
{名前: 「ケン」 、そのうち: 「食べ物が大好き。彼女はあなたも食べることができます。」 }
])
ここで、MongoDB の createIndex() 関数を使用して、このコレクションの「Des」フィールドにテキスト インデックスを作成します。フィールド値のキーワード「text」は、インデックスの種類、つまり「テキスト」インデックスを表示します。インデックス名 des_text は自動生成されています。
テスト> db.Test.createIndex({ デス: '文章' })これで、find() 関数を使用して、「des_text」インデックスを介してコレクションの「テキスト検索」が実行されました。 $search 演算子は、コレクション レコード内で「food」という単語を検索し、その特定のレコードを表示するために利用されました。
テスト> db.Test.find({ $text: { $search: '食べ物' }}); 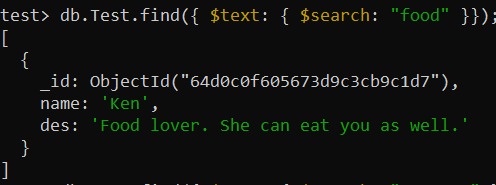
インデックスを検証します。
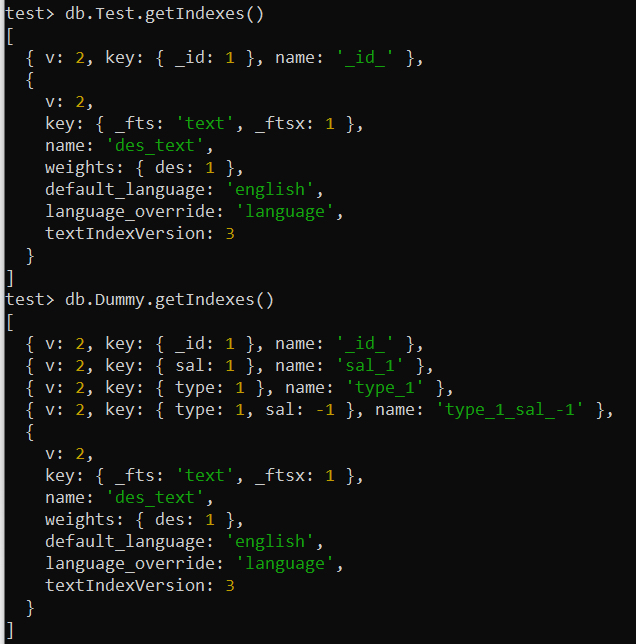
MongoDB 内のさまざまなコレクションに適用されているすべてのインデックスを確認して一覧表示できます。このためには、MongoDB シェル画面でコレクションの名前とともに getIndexes() メソッドを使用します。このコマンドは、「テスト」コレクションと「ダミー」コレクションに個別に使用しました。これにより、組み込みインデックスとユーザー定義インデックスに関する必要な情報がすべて画面に表示されます。
テスト> db.Test.getIndexes()テスト> db.Dummy.getIndexes()
インデックスの削除:
ここで、dropIndex() 関数を使用して、コレクションに対して以前に作成されたインデックスを、インデックスが適用されていたのと同じフィールド名とともに削除します。以下のクエリは、単一のインデックスが削除されたことを示しています。
テスト> db.Dummy.dropIndex({タイプ: 1 }) 
同様に、複合インデックスも削除できます。
テスト> db.Dummy.drop インデックス({タイプ: 1 、 意思: 1 }) 
結論
MongoDB からのデータの取得を高速化することで、クエリの効率を高めるにはインデックス作成が不可欠です。インデックスが不足しているため、MongoDB は一致するレコードをコレクション全体で検索する必要がありますが、セットのサイズが大きくなるにつれて効率が低下します。インデックス データベース構造を利用して適切なレコードを迅速に検出する MongoDB の機能により、適切なインデックス付けが使用されている場合、クエリの処理が高速化されます。