UTF-8 は「」の略です。 Unicode 変換フォーマット 8 ビット 」に対応しており、使用されている言語/スクリプトに関係なく、すべてのデバイスで文字が適切に表示されることを保証する優れたエンコード形式に対応しています。また、この形式は Web ページに役立ち、インターネット上のテキスト データの保存、処理、送信にも利用されます。
このチュートリアルでは、以下のコンテンツ領域について説明します。
- UTF-8エンコーディングとは何ですか?
- UTF-8 エンコーディングはどのように機能しますか?
- コードポイント値はどのように計算されますか?
- JavaScript で UTF-8 をエンコード/デコードするにはどうすればよいですか?
- 「encodeURIComponent()」メソッドと「decodeURIComponent()」メソッドを使用して、JavaScript で UTF-8 をエンコード/デコードします。
- 「encodeURI()」メソッドと「decodeURI()」メソッドを使用して、JavaScript で UTF-8 をエンコード/デコードします。
- 正規表現を使用して JavaScript で UTF-8 をエンコード/デコードします。
- 結論
UTF-8エンコーディングとは何ですか?
「 UTF-8エンコーディング 」は、一連の Unicode 文字を 8 ビット バイトで構成されるエンコードされた文字列に変換する手順です。このエンコーディングは、他の文字エンコーディングと比較して広範囲の文字を表現できます。
UTF-8 エンコーディングはどのように機能しますか?
UTF-8 で文字を表現する場合、個々のコード ポイントは 1 つ以上のバイトで表現されます。以下は、ASCII 範囲のコード ポイントの内訳です。
- 1 バイトは ASCII 範囲 (0 ~ 127) のコード ポイントを表します。
- 2 バイトは ASCII 範囲 (128 ~ 2047) のコード ポイントを表します。
- 3 バイトは ASCII 範囲 (2048 ~ 65535) のコード ポイントを表します。
- 4 バイトは ASCII 範囲 (65536 ~ 1114111) のコード ポイントを表します。
「」の最初のバイトが UTF-8 ” シーケンスは” と呼ばれます。 リーダーバイト 」は、シーケンス内のバイト数と文字のコード ポイント値に関する情報を提供します。
1 バイト、2 バイト、3 バイト、および 4 バイトのシーケンスの「リーダー バイト」の範囲は、それぞれ (0 ~ 127)、(194 ~ 233)、(224 ~ 239)、および (240 ~ 247) です。
シーケンスの残りのバイトは「」と呼ばれます。 後続 」バイト。 2 バイト、3 バイト、および 4 バイトのシーケンスのバイトはすべて (128 ~ 191) の範囲内にあります。先頭と末尾のバイトを分析することで文字のコード ポイント値を計算できるようになります。
コードポイント値はどのように計算されますか?
さまざまなバイト シーケンスのコード ポイント値は次のように計算されます。
- 2 バイトのシーケンス: コードポイントは「((lb – 194) * 64) + (tb – 128)」と同等です。
- 3バイトシーケンス :コードポイントは「((lb – 224) * 4096) + ((tb1 – 128) * 64) + (tb2 – 128)」に相当します。
- 4バイトのシーケンス :コードポイントは「((lb – 240) * 262144) + ((tb1 – 128) * 4096) + ((tb2 – 128) * 64) + (tb3 – 128)」と同等です。
JavaScript で UTF-8 をエンコード/デコードするにはどうすればよいですか?
JavaScript での UTF-8 のエンコードとデコードは、以下の方法で実行できます。
- 「 enodeURIComponent() ' そして ' decodeURIComponent() 」メソッド。
- 「 encodeURI() ' そして ' デコードURI() 」メソッド。
- 正規表現。
アプローチ 1: 「encodeURIComponent()」メソッドと「decodeURIComponent()」メソッドを使用して JavaScript で UTF-8 をエンコード/デコードする
” encodeURIComponent() 」メソッドは URI コンポーネントをエンコードします。また、@、&、:、+、$、# などの特殊文字をエンコードできます。 decodeURIComponent() ただし、メソッドは URI コンポーネントをデコードします。これらのメソッドを利用して、渡された値をそれぞれ UTF-8 にエンコードおよびデコードできます。
構文(“encodeURIComponent()”メソッド)
encodeURIコンポーネント ( バツ )指定された構文では、「 バツ 」はエンコードする URI を示します。
戻り値
このメソッドは、エンコードされた URI を文字列として取得します。
構文(「decodeURIComponent()」メソッド)
デコードURIコンポーネント ( バツ )ここ、 ' バツ ”はデコードするURIを指します。
戻り値
このメソッドは、デコードされた URI を提供します。
例 1: JavaScript での UTF-8 エンコード
この例では、ユーザー定義関数を使用して、渡された文字列をエンコードされた UTF-8 値にエンコードします。
戻る 逃げ出す ( encodeURIコンポーネント ( バツ ) ) ;
}
ヴァルをみましょう = 'ここ' ;
コンソール。 ログ ( 「与えられた値 -> 」 + ヴァル ) ;
Val をエンコードしましょう = エンコード_utf8 ( ヴァル ) ;
コンソール。 ログ ( 「エンコードされた値 -> 」 + エンコード値 ) ;
これらのコード行で、以下の手順を実行します。
- まず関数「」を定義します。 encode_utf8() 」は、指定されたパラメータで表される渡された文字列をエンコードします。
- このエンコードは「」によって行われます。 encodeURIComponent() 」メソッドを関数定義に追加します。
- 注記: ” アンエスケープ() 」メソッドは、エスケープ シーケンスを、それによって表される文字に置き換えます。
- その後、エンコードする値を初期化して表示します。
- 次に、定義された関数を呼び出し、定義された文字の組み合わせを引数として渡し、この値を UTF-8 にエンコードします。
出力
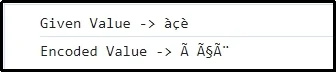
ここでは、個々の文字がそれに応じて UTF-8 で表現され、エンコードされることが暗示されています。
例 2: JavaScript での UTF-8 のデコード
以下のコードのデモでは、渡された値 (文字の形式) をエンコードされた UTF-8 表現にデコードします。
戻る デコードURIコンポーネント ( 逃げる ( バツ ) ) ;
}
ヴァルをみましょう = 「・・」 ;
コンソール。 ログ ( 「与えられた値 -> 」 + ヴァル ) ;
デコードしてみましょう = デコード_utf8 ( ヴァル ) ;
コンソール。 ログ ( 「デコードされた値 -> 」 + デコードする ) ;
このコード ブロックでは次のようになります。
- 同様に、関数「」を定義します。 デコード_utf8() ” を介して渡された文字の組み合わせをデコードします。 decodeURIComponent() ' 方法。
- 注記: ” 逃げる() 」メソッドは、さまざまな文字が 16 進数のエスケープ シーケンスで置き換えられた新しい文字列を取得します。
- その後、デコードする文字の組み合わせを指定し、定義した関数にアクセスすることで適切にUTF-8へのデコードが行われます。
出力

ここでは、前の例でエンコードされた値がデフォルト値にデコードされることを意味します。
アプローチ 2: 「encodeURI()」メソッドと「decodeURI()」メソッドを使用して JavaScript で UTF-8 をエンコード/デコードする
” encodeURI() 」メソッドは、複数の文字の各インスタンスを、文字の UTF-8 エンコーディングを表す多数のエスケープ シーケンスに置き換えることによって、URI をエンコードします。 「」に比べて、 encodeURIComponent() 」メソッドと同様に、この特定のメソッドは制限された文字をエンコードします。
” デコードURI() ただし、このメソッドは URI (エンコードされたもの) をデコードします。これらのメソッドを組み合わせて実装すると、UTF-8 でエンコードされた値内の文字の組み合わせをエンコードおよびデコードできます。
構文(encodeURI()メソッド)
エンコードURI ( バツ )上記の構文では、「 バツ ”がURIとしてエンコードされる値に相当します。
戻り値
このメソッドは、エンコードされた値を文字列の形式で取得します。
構文(decodeURI()メソッド)
デコードURI ( バツ )ここ、 ' バツ 」は、デコードするエンコードされた URI を表します。
戻り値
デコードされた URI を文字列として返します。
例 1: JavaScript での UTF-8 エンコード
このデモでは、渡された文字の組み合わせをエンコードされた UTF-8 値にエンコードします。
戻る 逃げ出す ( エンコードURI ( バツ ) ) ;
}
ヴァルをみましょう = 'ここ' ;
コンソール。 ログ ( 「与えられた値 -> 」 + ヴァル ) ;
Val をエンコードしましょう = エンコード_utf8 ( ヴァル ) ;
コンソール。 ログ ( 「エンコードされた値 -> 」 + エンコード値 ) ;
ここで、エンコード用に割り当てられた関数を定義するアプローチを思い出してください。次に、「encodeURI()」メソッドを適用して、渡された文字の組み合わせを UTF-8 でエンコードされた文字列として表します。以降、同様に評価対象の文字を定義し、定義した値を引数として関数を呼び出してエンコードを行います。
出力
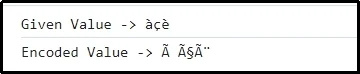
ここで、渡された文字の組み合わせが正常にエンコードされたことがわかります。
例 2: JavaScript での UTF-8 のデコード
以下のコードデモは、エンコードされた UTF-8 値 (前の例) をデコードします。
戻る デコードURI ( 逃げる ( バツ ) ) ;
}
ヴァルをみましょう = 「・・」 ;
コンソール。 ログ ( 「与えられた値 -> 」 + ヴァル ) ;
デコードしてみましょう = デコード_utf8 ( ヴァル ) ;
コンソール。 ログ ( 「デコードされた値 -> 」 + デコードする ) ;
このコードに従って、関数を宣言します。 デコード_utf8() 「」を使用してデコードされる文字の組み合わせを表す指定されたパラメータで構成されます。 デコードURI() ' 方法。ここで、デコードする値を指定し、定義された関数を呼び出してデコードを「」に適用します。 UTF-8 」の表現。
出力
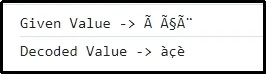
この結果は、以前にエンコードされた値がそれに応じて決定されたことを意味します。
アプローチ 3: 正規表現を使用して JavaScript で UTF-8 をエンコード/デコードする
このアプローチでは、マルチバイト Unicode 文字列が UTF-8 の複数のシングルバイト文字にエンコードされるようにエンコードが適用されます。同様に、デコードは、エンコードされた文字列がマルチバイト Unicode 文字にデコードされるように実行されます。
例 1: JavaScript での UTF-8 エンコード
以下のコードは、マルチバイト Unicode 文字列を UTF-8 シングルバイト文字にエンコードします。
もし ( の種類 ヴァル != '弦' ) 投げる 新しい タイプエラー ( 「パラメータ」 ヴァル 'は文字列ではありません' ) ;
定数 string_utf8 = 価値 交換する (
/[\u0080-\u07ff]/g 、 // U+0080 - U+07FF => 2バイト 110yyyyy, 10zzzzzz
関数 ( バツ ) {
だった 外 = バツ。 charCodeAt ( 0 ) ;
戻る 弦 。 fromCharCode ( 0xc0 | 外 >> 6 、 0x80 | 外 & 0x3f ) ; }
) 。 交換する (
/[\u0800-\uffff]/g 、 // U+0800 - U+FFFF => 3 バイト 1110xxxx、10yyyyyy、10zzzzzz
関数 ( バツ ) {
だった 外 = バツ。 charCodeAt ( 0 ) ;
戻る 弦 。 fromCharCode ( 0xe0 | 外 >> 12 、 0x80 | 外 >> 6 & 0x3F 、 0x80 | 外 & 0x3f ) ; }
) ;
コンソール。 ログ ( 「正規表現を使用してエンコードされた値 -> 」 + string_utf8 ) ;
}
エンコードUTF8 ( 'ここ' )
このコードのスニペットでは次のようになります。
- 関数を定義します。 encodeUTF8() 「」としてエンコードされる値を表すパラメータで構成されます。 UTF-8 ”。
- その定義では、「」を使用して、文字列ではない渡された値にチェックを適用します。 種類 ” 演算子を使用し、「」を介して指定されたカスタム例外を返します。 投げる 」というキーワード。
- その後、「」を適用します。 charCodeAt() ' そして ' fromCharCode() 」メソッドを使用して、文字列の最初の文字の Unicode を取得し、指定された Unicode 値を文字に変換します。
- 最後に、指定された文字シーケンスを渡して定義された関数を呼び出し、この値を「」としてエンコードします。 UTF-8 」の表現。
出力

この出力は、エンコードが適切に実行されたことを意味します。
例 2: JavaScript での UTF-8 のデコード
このデモでは、一連の文字が「」にデコードされます。 UTF-8 ” 表現:
もし ( の種類 ヴァル != '弦' ) 投げる 新しい タイプエラー ( 「パラメータ」 ヴァル 'は文字列ではありません' ) ;
定数 str = 価値 交換する (
/[\u00e0-\u00ef][\u0080-\u00bf][\u0080-\u00bf]/g 、
関数 ( バツ ) {
だった 外 = ( ( バツ。 charCodeAt ( 0 ) & 0x0f ) << 12 ) | ( ( バツ。 charCodeAt ( 1 ) & 0x3f ) << 6 ) | ( バツ。 charCodeAt ( 2 ) & 0x3f ) ;
戻る 弦 。 fromCharCode ( 外 ) ; }
) 。 交換する (
/[\u00c0-\u00df][\u0080-\u00bf]/g 、
関数 ( バツ ) {
だった 外 = ( バツ。 charCodeAt ( 0 ) & 0x1f ) < '+str);
}
decodeUTF8('ã ã§ã ')
このコードでは:
- 同様に関数「」を定義します。 デコードUTF8() 」は、デコードされる渡された値を参照するパラメータを持ちます。
- 関数定義で、「」を介して渡された値の文字列条件を確認します。 種類 」オペレーター。
- ここで、「」を適用します。 charCodeAt() 」メソッドを使用して、それぞれ 1 番目、2 番目、および 3 番目の文字列の Unicode を取得します。
- また、「」を適用します。 String.fromCharCode() 」メソッドを使用して、Unicode 値を文字に変換します。
- 同様に、この手順をもう一度繰り返して、最初と 2 番目の文字列文字の Unicode を取得し、これらの Unicode 値を文字に変換します。
- 最後に、定義された関数にアクセスして、UTF-8 デコードされた値を返します。
出力

ここで、デコードが正しく行われたことを確認できます。
結論
UTF-8表現でのエンコード/デコードは「 enodeURIComponent()” そして ' decodeURIComponent() メソッド、「 encodeURI() ' そして ' デコードURI() 」の方法、または正規表現を使用します。