ここで、上記のすべての画像処理トピックについて詳しく説明します。
1. 画像翻訳
画像変換は、x 軸と y 軸に沿って画像を移動するのに役立つ画像処理方法です。画像を上下左右、または任意の組み合わせで移動できます。
変換行列は記号 M で定義でき、以下に示すように数学的な形式で表すことができます。
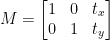
このプログラムを通して、翻訳画像の概念を理解することができます。
Python コード: 次のプログラムの名前はそのままにします 翻訳.py .
# 必要なパッケージをインポート輸入 でこぼこ なので 例えば
輸入 argparse
輸入 imutil
輸入 cv2
# 引数パーサーを実装します
ap_obj = argparse. 引数パーサー ( )
ap_obj. add_argument ( 「-k」 、 ' - 画像' 、 必要 = 真実 、
ヘルプ = 「画像ファイルの場所」 )
引数 = だれの ( ap_obj. parse_args ( ) )
# 画像を読み込んで画面に表示
画像 = cv2. 読んだ ( 引数 [ '画像' ] )
cv2. imshow ( 「オリジナル_イメージ」 、 画像 )
# 画像の翻訳は、以下に示す NumPy 行列です。
# [[1, 0, シフトX], [0, 1, シフトY]]
# 上記の NumPy 行列を使用して、画像を
# x 軸と y 軸の方向。このためには、単純にピクセル値を渡す必要があります。
# このプログラムでは、画像を 30 ピクセル右に移動します
# 下に向かって 70 ピクセル。
翻訳マット = 例えば float32 ( [ [ 1 、 0 、 30 ] 、 [ 0 、 1 、 70 ] ] )
画像翻訳 = cv2. warpAffine ( 画像 、 翻訳マット 、
( 画像。 形 [ 1 ] 、 画像。 形 [ 0 ] ) )
cv2. imshow ( 「画像の上下左右移動」 、 画像翻訳 )
# ここで、上記の NumPy 行列を使用して、画像を
# x 軸 (左) と y 軸 (上) の方向。
# ここでは、画像を 50 ピクセル左に移動します
# 上方向に 90 ピクセル。
翻訳マット = 例えば float32 ( [ [ 1 、 0 、 - 50 ] 、 [ 0 、 1 、 - 90 ] ] )
画像翻訳 = cv2. warpAffine ( 画像 、 翻訳マット 、
( 画像。 形 [ 1 ] 、 画像。 形 [ 0 ] ) )
cv2. imshow ( 「画像の上下左右移動」 、 画像翻訳 )
cv2. 待機キー ( 0 )
1行目から5行目: OpenCV、argparser、NumPy など、このプログラムに必要なすべてのパッケージをインポートしています。 imutils という別のライブラリがあることに注意してください。これは OpenCV のパッケージではありません。これは、同じ画像処理を簡単に表示する単なるライブラリです。
OpenCV をインストールしても、ライブラリ imutils は自動的に含まれません。したがって、imutils をインストールするには、次の方法を使用する必要があります。
pip インストール imutils
8 行目から 15 行目: agrparser を作成し、イメージをロードしました。
24 ~ 25 行目: このプログラム セクションで翻訳が行われます。平行移動行列は、画像が上下左右に移動するピクセル数を示します。 OpenCV では行列値が浮動小数点配列にある必要があるため、変換行列は浮動小数点配列の値を取ります。
翻訳行列の最初の行は次のようになります。
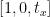
行列のこの行は x 軸用です。 t の値 バツ 画像を左右どちらにシフトするかを決定します。負の値を渡すと画像が左側に移動することを意味し、正の値を渡すと画像が右側に移動することを意味します。
行列の 2 行目を次のように定義します。
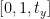
行列のこの行は y 軸用です。 t の値 よ 画像を上下どちらにシフトするかを決定します。負の値を渡すと画像が上に移動することを意味し、正の値を渡すと画像が下に移動することを意味します。
前のプログラムの 24 行目で、t を定義します。 バツ = 30 と t よ = 70. したがって、画像を右側に 30 ピクセル、下に 70 ピクセル移動します。
しかし、メインの画像変換プロセスは 25 行目で行われ、ここで変換行列を定義します。 cv2.warpAffine .この関数では、3 つのパラメーターを渡します。最初のパラメーターは画像、2 番目のパラメーターは変換行列、3 番目のパラメーターは画像の次元です。
27 行目: 行 27 は結果を出力に表示します。
ここで、左と上に別の変換行列を実装します。このために、負の値を定義する必要があります。
33 ~ 34 行目: 前のプログラムの 33 行目で、t を定義します。 バツ = -50 と t よ = -90。したがって、画像を左側に 50 ピクセル、上に 90 ピクセル移動します。しかし、メインの画像変換プロセスは 34 行目で行われ、ここで変換行列を定義します。 cv2.warpAffine .
36行目 : 行 36 は、出力に示されているように結果を表示します。
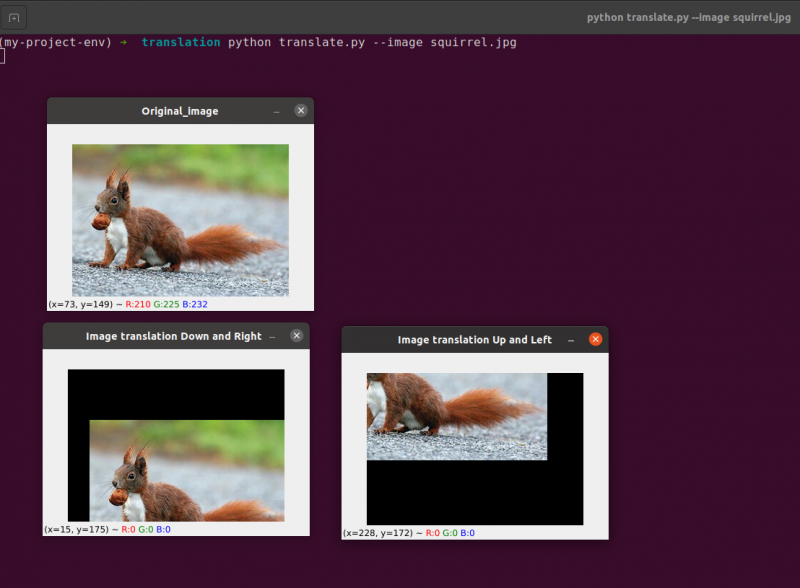
前のコードを実行するには、以下に示すように画像のパスを指定する必要があります。
出力: python translate.py –image squirrel.jpg
次に、を使用して同じ画像翻訳プログラムを実装します。 imutil 図書館。このライブラリは、画像処理に非常に使いやすいです。このライブラリでは、 cv2.warpAffine このライブラリがこれを処理するためです。 imutils ライブラリを使用して、この画像変換プログラムを実装しましょう。
Python コード: 次のプログラムの名前はそのままにします translate_imutils.py .
# 必要なパッケージをインポート輸入 でこぼこ なので 例えば
輸入 argparse
輸入 imutil
輸入 cv2
# この関数は画像の翻訳を実装し、
# 翻訳された画像を呼び出し元の関数に返します。
デフォルト 翻訳 ( 画像 、 バツ 、 よ ) :
翻訳行列 = 例えば float32 ( [ [ 1 、 0 、 バツ ] 、 [ 0 、 1 、 よ ] ] )
画像翻訳 = cv2. warpAffine ( 画像 、 翻訳行列 、
( 画像。 形 [ 1 ] 、 画像。 形 [ 0 ] ) )
戻る 画像翻訳
# 引数パーサーを構築し、引数を解析します
ap = argparse. 引数パーサー ( )
ap。 add_argument ( '-私' 、 ' - 画像' 、 必要 = 真実 、 ヘルプ = 「画像への道」 )
引数 = だれの ( ap。 parse_args ( ) )
# 画像を読み込んで画面に表示
画像 = cv2. 読んだ ( 引数 [ '画像' ] )
cv2. imshow ( 「オリジナル_イメージ」 、 画像 )
画像翻訳 = imutil。 翻訳 ( 画像 、 10 、 70 )
cv2. imshow ( 「右と下への画像翻訳」 、
画像翻訳 )
cv2. 待機キー ( 0 )
9 行目から 13 行目: プログラムのこのセクションで、翻訳が行われます。平行移動行列は、画像が上下左右に移動するピクセル数を示します。
これらの行についてはすでに説明しましたが、今度は translate() という関数を作成し、それに 3 つの異なるパラメーターを送信します。画像自体が最初のパラメーターとして機能します。平行移動行列の x 値と y 値は、2 番目と 3 番目のパラメーターに対応します。
ノート 注: この変換関数は imutils ライブラリ パッケージに既に含まれているため、プログラム内で定義する必要はありません。簡単な説明のために、プログラム内で使用しました。 24 行目に示すように、この関数は imutils で直接呼び出すことができます。
24 行目: 前のプログラムでは、24 行目で tx = 10 と ty = 70 を定義していることがわかります。したがって、画像を右側に 10 ピクセル、下に 70 ピクセル移動します。
このプログラムでは、cv2.warpAffine 関数は既に imutils ライブラリ パッケージ内にあるため、気にしません。
前のコードを実行するには、以下に示すように、画像のパスを指定する必要があります。
出力:
python imutils. パイ --imageリス。 jpg 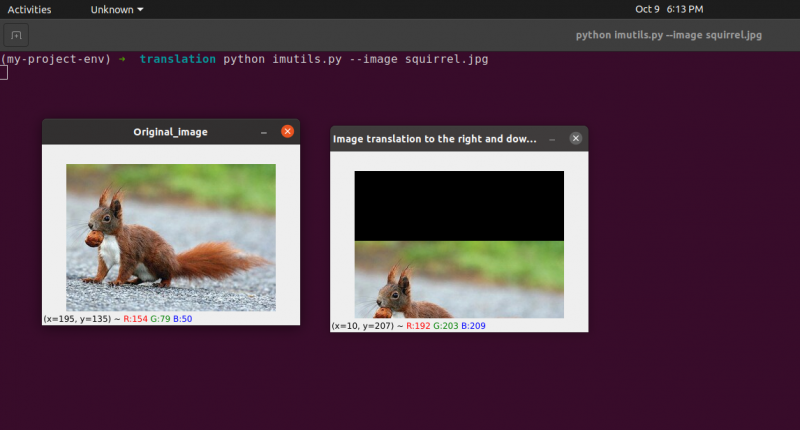
2.画像の回転
前のレッスン (または任意の組み合わせ) で、画像を上下左右に移動 (シフト) する方法について説明しました。次に、画像処理に関連する回転について説明します。
画像は、回転と呼ばれるプロセスで角度シータだけ回転します。画像を回転させる角度はシータで表されます。さらに、後で画像の回転を簡単にする回転便利な関数を提供します。
平行移動と同様に、おそらく驚くことではありませんが、角度による回転であるシータは、次の形式で行列 M を作成することによって決定されます。
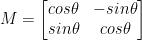
この行列は、指定された (x, y) デカルト平面の原点を中心にベクトル シータ度 (反時計回り) を回転させることができます。通常、このシナリオでは、原点は画像の中心になりますが、実際には、ランダムな (x, y) ポイントを回転の中心として指定する場合があります。
次に、単純な行列乗算を使用して、元の画像 I から回転した画像 R を作成します。 R = IM
一方、OpenCV はさらに、(1) 画像をスケーリング (つまり、サイズ変更) する機能と、(2) 回転を実行するための任意の回転中心を提供する機能を提供します。
修正した回転行列 M を以下に示します。
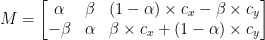
という名前の新しいファイルを開いて生成することから始めましょう 回転.py :
# 必要なパッケージのインポート輸入 でこぼこ なので 例えば
輸入 argparse
輸入 imutil
輸入 cv2
# argumentparser オブジェクトの作成と引数の解析
apobj = argparse. 引数パーサー ( )
apobj。 add_argument ( 「-k」 、 ' - 画像' 、 必要 = 真実 、 ヘルプ = 「画像パス」 )
引数 = だれの ( apobj。 parse_args ( ) )
画像 = cv2. 読んだ ( 引数 [ '画像' ] )
cv2. imshow ( 「オリジナル_イメージ」 、 画像 )
# 画像の寸法を使用して画像の中心を計算します。
( 身長 、 幅 ) = 画像。 形 [ : 2 ]
( センターX 、 センターY ) = ( 幅 / 2 、 身長 / 2 )
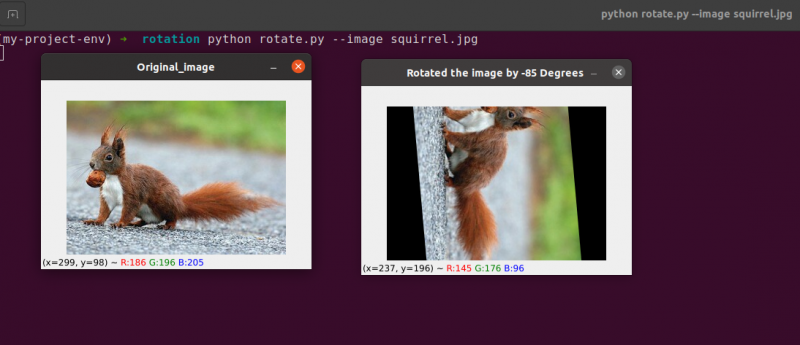
# ここで、cv2 を使用して、画像を 55 度回転させて
# getRotationMatrix2D() を使用して回転行列を決定する
回転行列 = cv2. getRotationMatrix2D ( ( センターX 、 センターY ) 、 55 、 1.0 )
回転した画像 = cv2. warpAffine ( 画像 、 回転行列 、 ( 幅 、 身長 ) )
cv2. imshow ( 「画像を 55 度回転させました」 、 回転した画像 )
cv2. 待機キー ( 0 )
# 画像が -85 度回転します。
回転行列 = cv2. getRotationMatrix2D ( ( センターX 、 センターY ) 、 - 85 、 1.0 )
回転した画像 = cv2. warpAffine ( 画像 、 回転行列 、 ( 幅 、 身長 ) )
cv2. imshow ( 「画像を-85度回転させました」 、 回転した画像 )
cv2. 待機キー ( 0 )
1行目から5行目: OpenCV、argparser、NumPy など、このプログラムに必要なすべてのパッケージをインポートしています。 imutils という別のライブラリがあることに注意してください。これは OpenCV のパッケージではありません。これは、同じ画像処理を簡単に示すために使用される単なるライブラリです。
OpenCV をインストールしても、ライブラリ imutils は自動的に含まれません。 OpenCV は imutils をインストールします。次の方法を使用する必要があります。
pip インストール imutils
8 行目から 14 行目: agrparser を作成し、イメージをロードしました。この argparser では、回転を示すためにこのプログラムで使用する画像のパスを示す画像引数を 1 つだけ使用します。
画像を回転するときは、回転のピボット ポイントを定義する必要があります。ほとんどの場合、画像をその中心を中心に回転させたいと思うでしょうが、OpenCV では代わりに任意の点をランダムに選択できます。画像を中心に回転させてみましょう。
17~18行目 画像の幅と高さをそれぞれ取り、各寸法を 2 で割り、画像の中心を確立します。
画像を平行移動する行列を定義したのと同じ方法で、画像を回転する行列を作成します。を呼び出すだけです cv2.getRotationMatrix2D NumPy を使用してマトリックスを手動で作成するのではなく (少し面倒かもしれません)、22 行目の関数を使用します。
の cv2.getRotationMatrix2D 関数には 3 つのパラメーターが必要です。最初の入力は目的の回転角度 (この場合は画像の中心) です。 Theta を使用して、画像を (反時計回りに) 回転する度数を指定します。ここでは、画像を 45 度回転させます。最後のオプションは、画像のサイズに関連しています。
画像のスケーリングについてはまだ説明していませんが、ここで浮動小数点数を 1.0 に指定して、画像を元の比率で使用する必要があることを示すことができます。ただし、値 2.0 を入力すると、イメージのサイズが 2 倍になります。 0.5 という数値は、画像のサイズをそのように縮小します。
22 ~ 23 行目: から回転行列 M を受け取った後、 cv2.getRotationMatrix2D 関数を使用して画像を回転させます cv2.warpAffine 関数の最初の入力は、回転させたい画像です。次に、出力画像の幅と高さを回転行列 M と共に定義します。23 行目で、画像を 55 度回転させます。
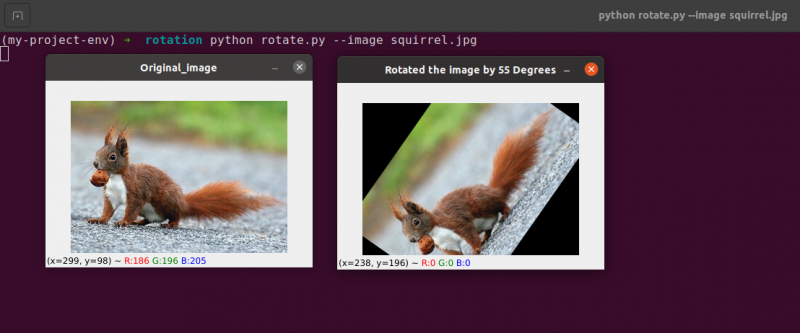
画像が回転していることがわかります。
28行目から30行目 2回転目を構成します。コードの 22 ~ 23 行目は同じですが、今回は 55 度ではなく -85 度回転しています。
ここまでは画像を中心に回転させただけです。 ランダムな点を中心に画像を回転させたい場合はどうすればよいでしょうか?
という名前の新しいファイルを開いて生成することから始めましょう 回転.py:
# 必要なパッケージのインポート輸入 でこぼこ なので 例えば
輸入 argparse
輸入 imutil
輸入 cv2
# argumentparser オブジェクトの作成と引数の解析
ap_obj = argparse. 引数パーサー ( )
ap_obj. add_argument ( 「-k」 、 ' - 画像' 、 必要 = 真実 、 ヘルプ = 「画像パス」 )
口論 = だれの ( ap_obj. parse_args ( ) )
# 画像を読み込んで画面に表示
画像 = cv2. 読んだ ( 口論 [ '画像' ] )
cv2. imshow ( 「オリジナル_イメージ」 、 画像 )
# 画像の寸法を使用して画像の中心を計算します。
( 身長 、 幅 ) = 画像。 形 [ : 2 ]
( センターX 、 センターY ) = ( 幅 / 2 、 身長 / 2 )
# ここで、cv2 を使用して、画像を 55 度回転させて
# getRotationMatrix2D() を使用して回転行列を決定する
回転行列 = cv2. getRotationMatrix2D ( ( センターX 、 センターY ) 、 55 、 1.0 )
回転した画像 = cv2. warpAffine ( 画像 、 回転行列 、 ( 幅 、 身長 ) )
cv2. imshow ( 「画像を 55 度回転させました」 、 回転した画像 )
cv2. 待機キー ( 0 )
# 画像が -85 度回転します。
回転行列 = cv2. getRotationMatrix2D ( ( センターX 、 センターY ) 、 - 85 、 1.0 )
回転した画像 = cv2. warpAffine ( 画像 、 回転行列 、 ( 幅 、 身長 ) )
cv2. imshow ( 「画像を-85度回転させました」 、 回転した画像 )
cv2. 待機キー ( 0 )
# 中心からではなく、任意の点からの画像の回転
回転行列 = cv2. getRotationMatrix2D ( ( センターX - 40 、 センターY - 40 ) 、 55 、 1.0 )
回転した画像 = cv2. warpAffine ( 画像 、 回転行列 、 ( 幅 、 身長 ) )
cv2. imshow ( 「任意点からの画像回転」 、 回転した画像 )
cv2. 待機キー ( 0 )
34 ~ 35 行目: さて、このコードは、オブジェクトを回転させるためにかなり一般的に見えるはずです。左に 40 ピクセル、中心から上に 40 ピクセルの点を中心に画像を回転するには、 cv2.getRotationMatrix2D 最初のパラメーターに注意を払う関数。
この回転を適用したときに生成される画像を以下に示します。
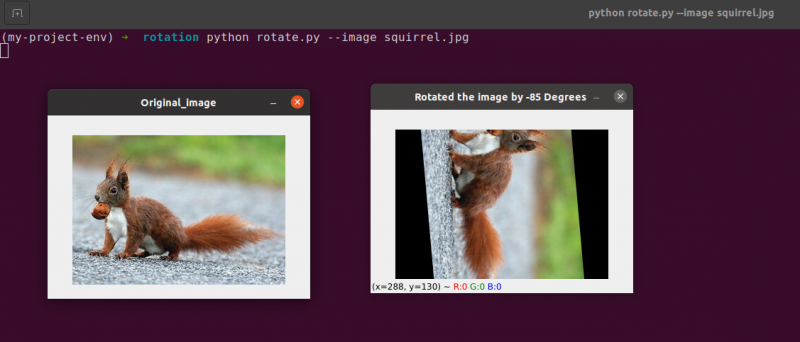
回転の中心が (x, y) 座標であることがはっきりとわかります。これは、画像の計算された中心から左に 40 ピクセル、上に 40 ピクセルです。
3. 画像演算
実際、画像演算は単なる行列の加算であり、後で説明するデータ型にいくつかの追加の制限があります。
少し時間を取って、線形代数のかなりの基礎を見ていきましょう。
次の 2 つの行列を組み合わせることを検討してください。
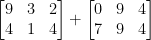
行列を追加すると、どのような結果が得られますか?簡単な答えは、要素ごとの行列エントリの合計です。
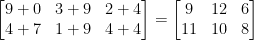
簡単ですよね?
この時点で、足し算と引き算の基本的な操作はすべて理解できます。ただし、画像を操作する際には、色空間とデータ型によって課せられる制限に注意する必要があります。
たとえば、RGB イメージのピクセルは [0, 255] の間に収まります。輝度 250 のピクセルを見ながら 10 を加えようとするとどうなるでしょうか?
標準的な算術原理を適用すると、値は 260 になります。 RGB イメージは 8 ビットの符号なし整数として表されるため、260 は有効な値ではありません。
では、何が起こるべきでしょうか? [0, 255] の範囲を超えるピクセルがないことを確認するチェックを実行し、すべてのピクセルを 0 から 255 の間の値になるようにクリッピングする必要がありますか?
それとも「ラップアラウンド」してモジュラス演算を実行しますか?モジュラス規則に従って、255 に 10 を加算すると、値は 9 になります。
[0, 255] の範囲を超える画像への加算と減算はどのように処理する必要がありますか?
真実は、正しいテクニックも間違ったテクニックもありません。それはすべて、ピクセルをどのように扱っているか、何を達成したいかによって異なります。
ただし、OpenCV での加算と NumPy での加算には違いがあることに注意してください。モジュラス演算と「ラップアラウンド」は NumPy によって行われます。対照的に、OpenCV はクリッピングを実行し、ピクセル値が [0, 255] の範囲を決して離れないようにします。
という名前の新しいファイルを作成することから始めましょう 算術.py そしてそれを開く:
# python 算術.py --image squirrel.jpg# 必要なパッケージのインポート
輸入 でこぼこ なので 例えば
輸入 argparse
輸入 imutil
輸入 cv2
# argumentparser オブジェクトの作成と引数の解析
apObj = argparse. 引数パーサー ( )
apObj。 add_argument ( 「-k」 、 ' - 画像' 、 必要 = 真実 、 ヘルプ = 「画像パス」 )
引数 = だれの ( apObj。 parse_args ( ) )
画像 = cv2. 読んだ ( 引数 [ '画像' ] )
cv2. imshow ( 「オリジナル_イメージ」 、 画像 )
'''
ピクセルの値は [0, 255] の範囲になります。
画像は NumPy 配列であり、符号なし 8 ビット整数として格納されるためです。
cv2.add や cv2.subtract などの関数を使用すると、値が切り取られます
の範囲外で加算または減算された場合でも、この範囲に
[0, 255] の範囲。以下に図を示します。
'''
印刷する ( '最大 255: {}' . フォーマット ( 力 ( cv2. 追加 ( 例えば uint8 ( [ 201 ] ) 、
例えば uint8 ( [ 100 ] ) ) ) ) )
印刷する ( 「最小 0: {}」 . フォーマット ( 力 ( cv2. 減算 ( 例えば uint8 ( [ 60 ] ) 、
例えば uint8 ( [ 100 ] ) ) ) ) )
'''
NumPy を使用してこれらの配列で算術演算を行う場合、
値は、クリップされるのではなくラップアラウンドします。
[0, 255]範囲。画像を使用するときは、これを維持することが不可欠です
念頭に置いて。
'''
印刷する ( '包み込む: {}' . フォーマット ( 力 ( 例えば uint8 ( [ 201 ] ) + 例えば uint8 ( [ 100 ] ) ) ) )
印刷する ( '包み込む: {}' . フォーマット ( 力 ( 例えば uint8 ( [ 60 ] ) - 例えば uint8 ( [ 100 ] ) ) ) )
'''
画像のすべてのピクセルの明るさを 101 倍してみましょう。
これを行うには、行列と同じサイズの NumPy 配列を生成します。
1 で埋められ、それを 101 倍して、埋められた配列を生成します。
101で。最後に、2 つの画像をマージします。
画像が「明るく」なっていることがわかります。
'''
マトリックス = 例えば もの ( 画像。 形 、 dtype = 'uint8' ) * 101
画像が追加されました = cv2. 追加 ( 画像 、 マトリックス )
cv2. imshow ( 「画像追加結果」 、 画像が追加されました )
#同様に、
# すべてのピクセルから 60 離れています。
マトリックス = 例えば もの ( 画像。 形 、 dtype = 'uint8' ) * 60
image_subtracted = cv2. 減算 ( 画像 、 マトリックス )
cv2. imshow ( 「差し引いた画像の結果」 、 image_subtracted )
cv2. 待機キー ( 0 )
1行目から16行目 通常のプロセスを実行するために使用されます。これには、パッケージのインポート、引数パーサーの構成、およびイメージのロードが含まれます。
以前、OpenCV と NumPy の追加の違いについて説明したことを思い出してください。徹底的にカバーしたので、具体的なケースを見て、それを確実に把握しましょう。
2 つの 8 ビット符号なし整数 NumPy 配列が定義されています 26行目 . 201 の値は、最初の配列の唯一の要素です。 2 番目の配列にはメンバーが 1 つしかありませんが、値は 100 です。その後、OpenCV の cv2.add 関数を使用して値が追加されます。
結果はどうなると思いますか?
従来の算術原則に従って、答えは 301 になるはずです。ただし、8 ビットの符号なし整数を扱っていることを思い出してください。これは [0, 255] の範囲にしかありません。 cv2.add メソッドを使用しているため、OpenCV はクリッピングを処理し、加算が最大 255 の結果のみを返すようにします。
以下のリストの最初の行は、このコードを実行した結果を示しています。
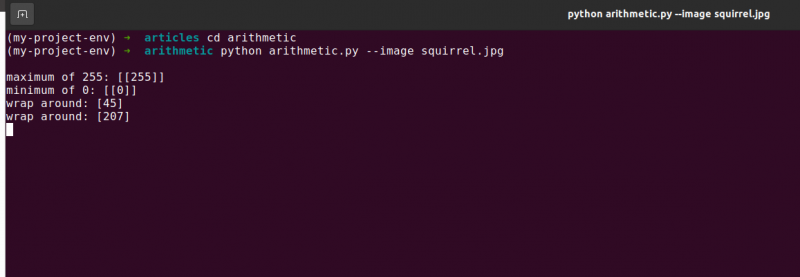
算術。 パイ最大 255 : [ [ 255 ] ]
合計は実際に 255 の数を生成しました。
以下のこと、 26行目 cv2.subtract を使用して減算を実行します。もう一度、それぞれに 1 つの要素を持つ 2 つの 8 ビット符号なし整数 NumPy 配列を定義します。最初の配列の値は 60 ですが、2 番目の配列の値は 100 です。
算術演算では、減算の結果が -40 になるはずですが、OpenCV がクリッピングをもう一度処理します。値が 0 にトリミングされていることがわかります。以下の結果はこれを示しています。
算術。 パイ最小 0 : [ [ 0 ] ]
cv2 を使用して、60 減算から 100 を減算し、値 0 を生成します。
しかし、OpenCV の代わりに NumPy を使用して計算を実行するとどうなるでしょうか?
38 行目と 39 行目 この問題に対処します。
最初に、それぞれ 1 つの要素を持つ 2 つの 8 ビット符号なし整数 NumPy 配列が定義されます。最初の配列の値は 201 ですが、2 番目の配列の値は 100 です。 cv2.add 関数を使用すると、加算が削除され、値 255 が返されます。
一方、NumPy は「ラップ アラウンド」し、クリッピングではなくモジュロ演算を行います。 NumPy は、値が 255 に達するとゼロに戻り、100 ステップに達するまでカウントアップを再開します。これは、以下に示す出力の最初の行によって確認されます。
算術。 パイ包み込む: [ 4.5 ]
次に、さらに 2 つの NumPy 配列が定義され、1 つは値が 50 で、もう 1 つは 100 です。この減算は cv2.subtract メソッドによってトリミングされ、0 の結果が返されます。ただし、クリッピングの代わりに NumPy が実行されることに注意してください。モジュロ演算。代わりに、減算中に 0 に達すると、モジュロ プロシージャがラップアラウンドし、255 から逆方向にカウントを開始します。これは、次の出力から確認できます。
算術。 パイ包み込む: [ 207 ]
繰り返しになりますが、ターミナル出力は、クリッピングとラップアラウンドの違いを示しています。
整数演算を実行するときは、目的の結果を念頭に置くことが重要です。 [0, 255] の範囲外の値を切り取りますか?その後、OpenCV の組み込みの画像演算手法を使用します。
値が [0, 255] およびモジュラス算術演算の範囲外にある場合、値をラップアラウンドしますか? NumPy 配列は、通常どおり単純に加算および減算されます。
48号線 画像と同じ次元の 1 次元 NumPy 配列を定義します。もう一度、データ型が 8 ビットの符号なし整数であることを確認します。 1 桁の値の行列に 101 を掛けて、1 ではなく 101 の値で埋めます。最後に、cv2.add 関数を使用して、100 の行列を元の画像に追加します。これにより、各ピクセルの強度が 101 ずつ増加し、255 を超えようとする値が [0, 255] の範囲にクリップされます。
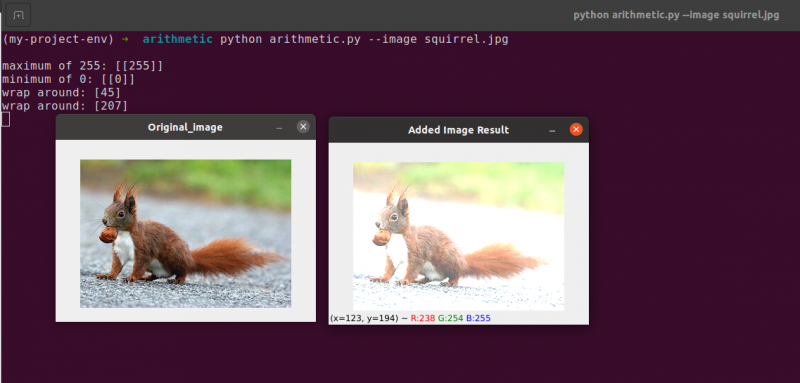
画像が元の画像よりも著しく明るくなり、「色あせた」ように見えることに注目してください。これは、ピクセルの強度を 101 倍にすることで、ピクセルをより明るい色に近づけるためです。
画像の各ピクセル強度から 60 を差し引くために、最初にライン 54 に 60 で埋められた 2 番目の NumPy 配列を確立します。
この減算の結果を次の図に示します。
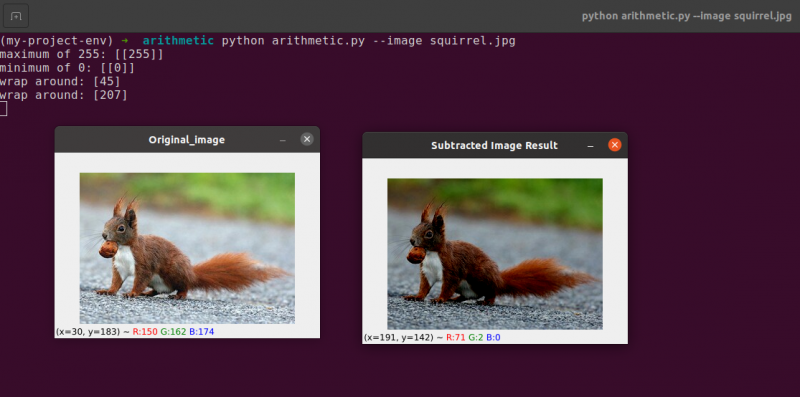
私たちの周りのアイテムは、以前よりもかなり暗く見えます。これは、各ピクセルから 60 を引くことで、RGB 色空間のピクセルをより暗い領域に移動しているためです。
4. 画像反転
回転と同様に、x 軸または y 軸で画像を反転することは、OpenCV が提供する別のオプションです。反転操作がそれほど頻繁に使用されていなくても、それらを知ることは、すぐにはわからないさまざまな理由で非常に有益です。
私たちは、画像内の顔を識別しようとする小さな新興企業向けの機械学習分類器を開発しています。私たちのシステムが顔とは何かを「学習」するには、サンプルの顔を含むある種のデータセットが必要です。残念ながら、会社から提供されたのは 40 人の顔の小さなデータセットのみであり、それ以上の情報を収集することはできません.
では、私たちは何をしますか?
ミラーリングされているかどうかに関係なく、顔は顔のままであるため、顔の各画像を水平方向に反転し、ミラーリングされたバージョンを追加のトレーニング データとして使用できます。
この例はばかげて人工的に見えるかもしれませんが、そうではありません。反転は、トレーニング フェーズでより多くのデータを生成するために、強力なディープ ラーニング アルゴリズムによって使用される意図的な戦略です。
このモジュールで学習する画像処理方法が、より大きなコンピューター ビジョン システムの基盤として機能することは、前の例から明らかです。
目的:
を使用して cv2.flip このセッションでは、画像を水平方向と垂直方向の両方で反転する方法を学習します。
反転は、次に学習する画像操作です。画像の x 軸と y 軸を反転させることも、両方を反転させることもできます。コーディングに入る前に、まず画像反転の結果を確認することをお勧めします。次の画像で水平方向に反転された画像を参照してください。
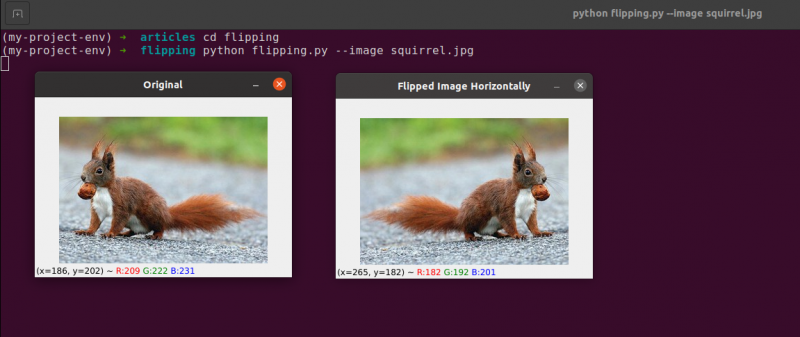
左側が元の画像で、右側が水平方向に鏡像化されていることに注意してください。
という名前の新しいファイルを作成することから始めましょう フリッピング.py .
画像反転の例を見たので、コードを調べてみましょう。
# python flipping.py --image quirrel.jpg# 必要なパッケージのインポート
輸入 argparse
輸入 cv2
# 引数パーサーのオブジェクトを作成し、引数を解析
apObj = argparse. 引数パーサー ( )
apObj。 add_argument ( '-私' 、 ' - 画像' 、 必要 = 真実 、 ヘルプ = 「画像パス」 )
口論 = だれの ( apObj。 parse_args ( ) )
画像 = cv2. 読んだ ( 口論 [ '画像' ] )
cv2. imshow ( 'オリジナル' 、 画像 )
# 画像を左右反転
画像反転 = cv2. フリップ ( 画像 、 1 )
cv2. imshow ( 「画像を左右反転」 、 画像反転 )
# 画像を上下反転
画像反転 = cv2. フリップ ( 画像 、 0 )
cv2. imshow ( 「画像を縦に反転」 、 画像反転 )
# 両方の軸に沿って画像を反転
画像反転 = cv2. フリップ ( 画像 、 - 1 )
cv2. imshow ( 「左右反転&上下反転」 、 画像反転 )
cv2. 待機キー ( 0 )
パッケージをインポートし、入力を解析し、ディスクからイメージをロードする手順は、l で処理されます。 ines 1 から 12 .
cv2.flip 関数を呼び出して 15行目 、画像を水平方向に反転するのは簡単です。反転しようとする画像と、画像を反転する方法を指定する特定のコードまたはフラグは、cv2.flip メソッドに必要な 2 つの引数です。
反転コード値 1 は、画像を y 軸を中心に回転させて水平方向に反転することを意味します ( 15行目 )。反転コード 0 を指定すると、画像を x 軸を中心に回転させます ( 19行目 )。負の反転コード ( 23行目 ) 両方の軸でイメージを回転します。
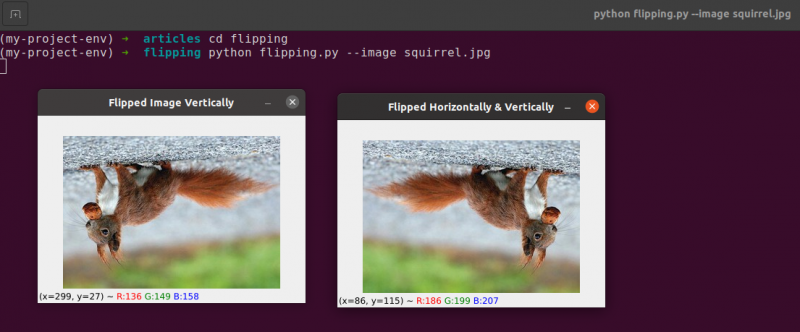
この主題の最も簡単な例の 1 つは、基本的な画像の反転です。
次に、画像のトリミングについて説明し、NumPy 配列スライスを使用して特定の画像部分を抽出します。
5. 画像のトリミング
クロッピングは、名前が示すように、対象領域 (または単に ROI) を選択して削除するプロセスです。これは、関心のある画像の領域です。
顔検出アプリケーションでは、画像から顔をトリミングする必要があります。さらに、画像内の犬を見つけるための Python スクリプトを作成している場合、犬を見つけたときに画像から犬をトリミングしたい場合があります。
目標: 私たちの主な目標は、NumPy 配列スライスを使用して画像から領域をトリミングすることに慣れ、簡単に使用できるようになることです。
クロッピング : 画像をトリミングするときの目標は、興味のない外部要素を排除することです。 ROI を選択するプロセスは、関心領域の選択と呼ばれることがよくあります。
という名前の新しいファイルを作成します。 作物.py を開いて、次のコードを追加します。
# パイソンクロップ.py# 必要なパッケージのインポート
輸入 cv2
# 画像読み込みと画面表示
画像 = cv2. 読んだ ( 「リス.jpg」 )
印刷する ( 画像。 形 )
cv2. imshow ( 'オリジナル' 、 画像 )
# NumPy 配列スライスを使用して、画像をすばやくトリミングします
# 画像からリスの顔をトリミングします
リスの顔 = 画像 [ 35 : 90 、 35 : 100 ]
cv2. imshow ( 「リスの顔」 、 リスの顔 )
cv2. 待機キー ( 0 )
# そして今、ここで全身をトリミングします
リスの数
リスの体 = 画像 [ 35 : 148 、 23 : 143 ]
cv2. imshow ( 「リスの体」 、 リスの体 )
cv2. 待機キー ( 0 )
ディスクからロードした画像を使用して、Python と OpenCV でのトリミングを示します。 5行目と6行目 .

トリミングする元の画像
基本的なトリミング技術のみを使用して、リスの顔とリスの体を周囲から分離することを目指しています。
画像に関する以前の知識を使用して、体と顔が存在する場所の NumPy 配列スライスを手動で提供します。通常の状況では、機械学習とコンピューター ビジョン アルゴリズムを使用して、画像内の顔と体を認識します。ただし、当分の間は単純にして、検出モデルの採用は避けましょう。
わずか 1 行のコードで、画像内の顔を識別できます。 13行目 , (35, 35) から始まる画像の長方形部分を抽出するために、NumPy 配列スライス (90, 100) を提供します。高さ優先、幅優先のインデックスをクロップに与えると混乱するかもしれませんが、OpenCV は画像を NumPy 配列として保存することに注意してください。その結果、x 軸の前に y 軸の値を指定する必要があります。
NumPy では、クロッピングを実行するために次の 4 つのインデックスが必要です。
開始: 先頭の y 座標。この例では、y=35 から開始します。
終わり: 末尾の y 座標。 y = 90 になるとトリミングが停止します。
開始 x: スライスの開始 x 座標。トリミングは x=35 で開始されます。
終了 x: スライスの最後の x 軸座標。 x=100 でスライスが完成します。
同様に、元の画像から領域 (23, 35) と (143, 148) をトリミングして、画像から全身を抽出します。 19行目 .
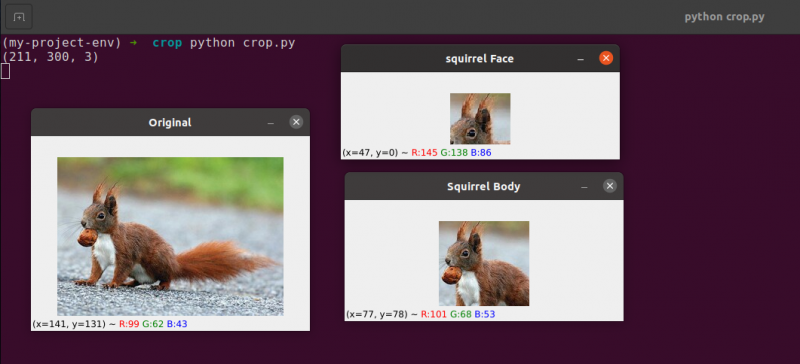
体と顔だけを表示するために画像がトリミングされていることがわかります。
6. 画像のサイズ変更
画像の幅と高さを増減するプロセスは、スケーリングまたは単にサイズ変更と呼ばれます。画像のサイズを変更するときは、画像の幅と高さの比率であるアスペクト比を考慮する必要があります。縦横比を無視すると、拡大縮小された画像が圧縮されて歪んで表示される可能性があります。
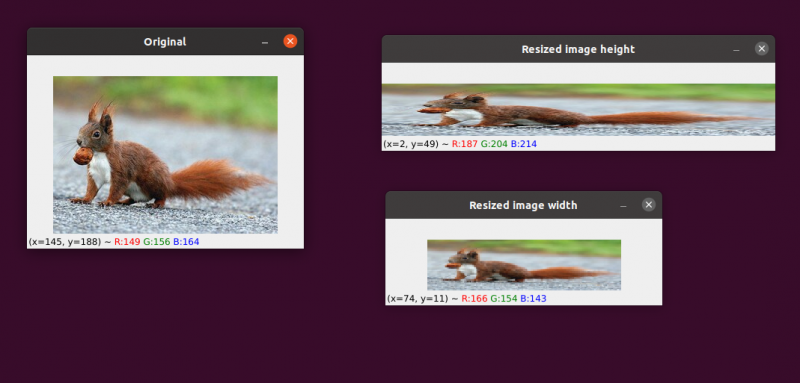
最初の画像は左側にあります。右側には、アスペクト比を維持せずにスケーリングされた 2 つの画像が表示され、画像の幅と高さの比率が歪んでいます。画像のサイズを変更するときは、通常、縦横比を考慮する必要があります。
サイズ変更アルゴリズムで使用される補間手法では、これらのピクセルの近傍を使用して画像のサイズを拡大または縮小するという補間関数の目的も考慮する必要があります。
一般に、画像のサイズを縮小する方がはるかに効果的です。これは、補間関数が行う必要があるのは、画像からピクセルを削除することだけだからです。一方、補間法では、画像サイズを大きくする場合、以前は存在しなかったピクセル間の「ギャップを埋める」必要があります。
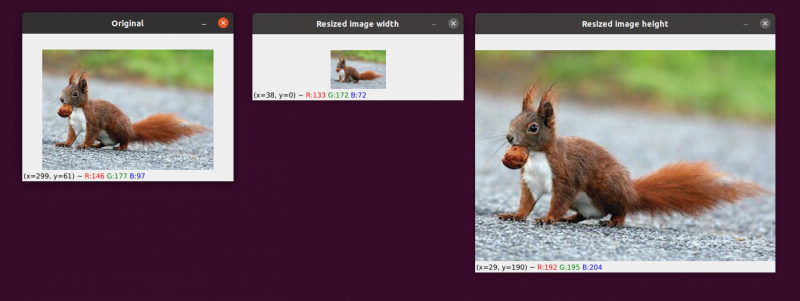
左側に元の画像があります。画像は中央が元のサイズの半分に縮小されていますが、それ以外の画像の「品質」は失われていません。それにもかかわらず、画像のサイズは右側で大幅に拡大されています。 「爆破」および「ピクセル化」されたように見えるようになりました。
前に述べたように、通常、画像のサイズを大きくするのではなく、縮小する必要があります。画像サイズを縮小することで、分析するピクセル数が減り、処理する「ノイズ」が少なくなり、画像処理アルゴリズムがより高速かつ正確になります。
これまでに取り上げた 2 つの画像変換は、平行移動と回転です。次に、画像のサイズを変更する方法を調べます。
当然のことながら、cv2.resize メソッドを使用して画像のサイズを変更します。前述したように、この方法を使用する場合は、画像の縦横比を考慮する必要があります。しかし、詳細に入る前に、例を示しましょう。
# python resize.py --image squirrel.jpg# 必要なパッケージのインポート
輸入 argparse
輸入 cv2
# 引数パーサーのオブジェクトを作成し、引数を解析
apObj = argparse. 引数パーサー ( )
apObj。 add_argument ( 「-k」 、 ' - 画像' 、 必要 = 真実 、 ヘルプ = 「画像パス」 )
引数 = だれの ( apObj。 parse_args ( ) )
# 画像を読み込んで画面に表示
画像 = cv2. 読んだ ( 引数 [ '画像' ] )
cv2. imshow ( 'オリジナル' 、 画像 )
# 画像がゆがんで見えるのを防ぐため、縦横比を
# 考慮または変形する必要があります。したがって、私たちは何を理解します
# 現在の画像に対する新しい画像の比率。
# 新しい画像の幅を 160 ピクセルにしましょう。
側面 = 160.0 / 画像。 形 [ 1 ]
寸法 = ( 160 、 整数 ( 画像。 形 [ 0 ] * 側面 ) )
# この行は実際のサイズ変更操作を示します
サイズ変更された画像 = cv2. サイズ変更 ( 画像 、 寸法 、 補間 = cv2. INTER_AREA )
cv2. imshow ( 「リサイズ画像幅」 、 サイズ変更された画像 )
# 画像の高さを変更したい場合は? — を使用して
# 同じ原理で、アスペクト比に基づいて計算できます
# 幅ではなく高さ。縮尺を作ろう
# 画像の高さ 70 ピクセル。
側面 = 70.0 / 画像。 形 [ 0 ]
寸法 = ( 整数 ( 画像。 形 [ 1 ] * 側面 ) 、 70 )
# リサイズを実行
サイズ変更された画像 = cv2. サイズ変更 ( 画像 、 寸法 、 補間 = cv2. INTER_AREA )
cv2. imshow ( 「リサイズ画像の高さ」 、 サイズ変更された画像 )
cv2. 待機キー ( 0 )
1~14行目 、パッケージをインポートして引数パーサーを構成した後、イメージをロードして表示します。
行 20 および 21: 関連するコーディングはこれらの行から始まります .サイズを変更するときは、画像の縦横比を考慮する必要があります。画像の幅と高さの比率は、アスペクト比として知られています。
高さ/幅 アスペクト比です。
縦横比を考慮しないと、サイズ変更の結果が歪んでしまいます。
の上 20行目 、リサイズ率の計算が行われます。このコード行では、新しい画像の幅を 160 ピクセルとして指定します。新しい幅 (160 ピクセル) をイメージを使用してアクセスする古い幅で割った比率 (アスペクト比) を単純に定義し、新しい高さと古い高さの比率を計算します。形状[1]。
上の画像の新しい寸法 21行目 比率がわかったので計算できます。ここでも、新しい画像の幅は 160 ピクセルになります。古い高さに比率を掛けて、結果を整数に変換した後、高さが計算されます。この操作を実行することで、画像の元の縦横比を維持できます。
24行目 画像が実際にサイズ変更される場所です。サイズを変更したい画像は最初の引数で、2 番目は新しい画像のために計算した寸法です。実際の画像のサイズを変更するためのアルゴリズムである補間方法は、最後のパラメーターです。
最後に、 25行目 、スケーリングされた画像を表示します。
比率(アスペクト比)を再定義します 31行目 .新しい画像の高さは 70 ピクセルになります。 70 を元の高さで割り、新しい高さと元の高さの比率を取得します。
次に、新しい画像の寸法を確立します。新しい画像の高さは既知の 70 ピクセルになります。古い幅に比率を掛けて新しい幅を生成することで、画像の元の縦横比をもう一度維持できます。
画像は実際にサイズ変更されます 35行目 に表示されます。 36行目。
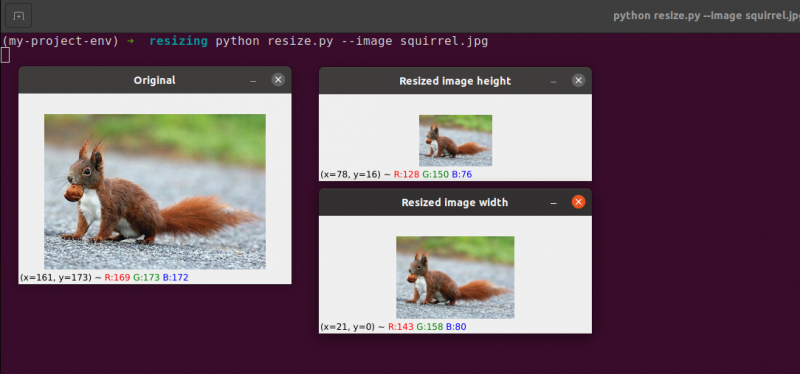
ここでは、縦横比を維持しながら、元の画像の幅と高さを縮小したことがわかります。縦横比が維持されていないと、画像が歪んで表示されます。
結論
このブログでは、基本的なさまざまな画像処理の概念について学習しました。 OpenCV パッケージの助けを借りて画像変換を見てきました。画像を上下左右に移動する方法を見てきました。これらの方法は、類似した画像のデータセットを作成してトレーニング データセットとして提供する場合に非常に役立ちます。そのため、マシンは同じ画像であっても異なる画像を表示します。この記事では、回転行列を使用してデカルト空間の任意の点を中心に画像を回転させる方法についても説明しました。次に、OpenCV がこの行列を使用して画像を回転させる方法を発見し、回転する画像のいくつかの図を見ました。
このセクションでは、足し算と引き算の 2 つの基本的な (しかし重要な) 画像算術演算について調べました。ご覧のとおり、基本行列の加算と減算はすべて、画像の算術演算に必要です。
さらに、OpenCV と NumPy を使用して、画像演算の特性を調査しました。これらの制限を念頭に置いておく必要があります。そうしないと、画像に対して算術演算を実行するときに予期しない結果が生じるリスクがあります。
NumPy はモジュラス演算を実行して「ラップ アラウンド」しますが、OpenCV の加算と減算は範囲 [0, 255] を超える値をカットして範囲内に収めることを覚えておくことが重要です。独自のコンピューター ビジョン アプリケーションを開発する場合、これを覚えておくと、厄介なバグを見つけ出すのを避けることができます。
画像の反転は、間違いなく、このコースで探求するより単純なアイデアの 1 つです。機械学習では、より多くのトレーニング データ サンプルを生成するためにフリッピングが頻繁に使用され、より強力で信頼性の高い画像分類器が得られます。
また、OpenCV を使用して画像のサイズを変更する方法も学びました。結果が歪んで見えないように、サイズを変更するときは、採用している補間方法と元の画像の縦横比の両方を考慮することが重要です。
最後に、画質が問題になる場合は、大きい画像から小さい画像に切り替えることが常に最善であることを覚えておくことが重要です。ほとんどの場合、画像を拡大するとアーティファクトが発生し、品質が低下します。