C++ では、Vector は要件に基づいて動的に増加する 1 次元のデータ構造です。このデータ構造では、データの整理(挿入・変更・削除)を効率的に行うことができます。その用途には以下が含まれます。
- 科学および工学アプリケーションにおける数学的ベクトルの表現
- このデータ構造を使用してキュー、スタックなどを実装できます。
このデータ構造に関連する一般的な CRUD 操作と関数のほとんどについて、構文とコード スニペットを使用してシナリオ別に詳しく説明します。
内容のトピック:
- 要素をベクターに挿入する
- 複数の要素をベクターに挿入
- ベクターから要素にアクセスする
- ベクター内の要素を更新する
- ベクトルから特定の要素を削除する
- ベクターからすべての要素を削除する
- ベクトルの結合
- ベクトルの交差
- ベクトルが空かどうかを確認する
- Const_Iterator を使用してベクトルを走査する
- Reverse_Iterator を使用してベクトルを走査する
- 要素をベクターにプッシュします
- ベクトルから要素をポップする
- ベクトルを交換する
- ベクターから最初の要素をフェッチする
- ベクターから最後の要素を取得する
- 新しい値をベクトルに代入する
- Emplace() を使用してベクトルを拡張する
- Emplace_Back() を使用してベクトルを拡張する
- ベクトルの最大要素
- ベクトルの最小要素
- ベクトル内の要素の合計
- 2 つのベクトルの要素ごとの乗算
- 2 つのベクトルの内積
- セットをベクトルに変換する
- 重複した要素を削除する
- ベクトルをセットに変換する
- 空の文字列を削除する
- ベクトルをテキスト ファイルに書き込む
- テキスト ファイルからベクトルを作成する
要素をベクターに挿入する
の std::vector::insert() C++ STL の関数は、指定された位置に要素を挿入するために使用されます。
構文:
ベクター。 入れる ( 位置、要素 ) ;この関数を利用して、要素を挿入する必要がある位置を指定するパラメータとして最初の位置を渡し、その要素を 2 番目のパラメータとして指定しましょう。
ここで begin() 関数を使用して、入力ベクトルの最初の要素を指す反復子を返すことができます。この関数に位置を追加すると、その位置に要素が挿入されます。
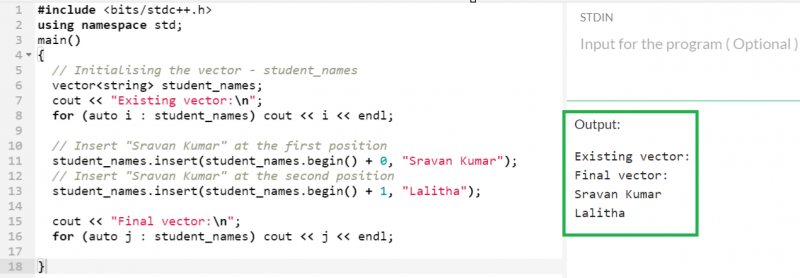
文字列型の「student_names」ベクトルを作成し、insert() 関数を使用して 2 つの文字列を最初と 2 番目の位置に順番に挿入しましょう。
#includeを使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルの初期化 -student_names
ベクター < 弦 > 学生名 ;
コート << 「既存のベクトル: \n 」 ;
のために ( 自動 私 : 学生名 ) コート << 私 << 終わり ;
// 最初の位置に「Sravan Kumar」を挿入します
学生名。 入れる ( 学生名。 始める ( ) + 0 、 「シュラヴァン・クマール」 ) ;
// 2 番目の位置に「Sravan Kumar」を挿入します
学生名。 入れる ( 学生名。 始める ( ) + 1 、 「ラリサ」 ) ;
コート << 「最終ベクトル: \n 」 ;
のために ( 自動 j : 学生名 ) コート << j << 終わり ;
}
出力:
以前は、「student_names」ベクトルは空でした。挿入後、ベクトルには 2 つの要素が保持されます。
複数の要素をベクターに挿入
このシナリオでは、同じ関数 std::vector::insert() を使用します。ただし、複数の要素をベクトルに挿入するには、追加の/異なるパラメーターを同じ関数に渡す必要があります。
シナリオ 1: 単一要素を複数回挿入する
このシナリオでは、同じ要素を複数回追加します。
構文:
ベクター。 入れる ( 位置、サイズ、要素 ) ;これを行うには、insert() 関数の 2 番目のパラメーターとしてサイズを渡す必要があります。この関数に渡されるパラメータは合計 3 つです。
ここ:
- 位置パラメータは、挿入される要素の位置を指定します。サイズが 1 より大きい場合、開始位置インデックスが位置になります。
- size パラメーターは、要素を挿入する回数を指定します。
- element パラメーターは、ベクトルに挿入される要素を受け取ります。
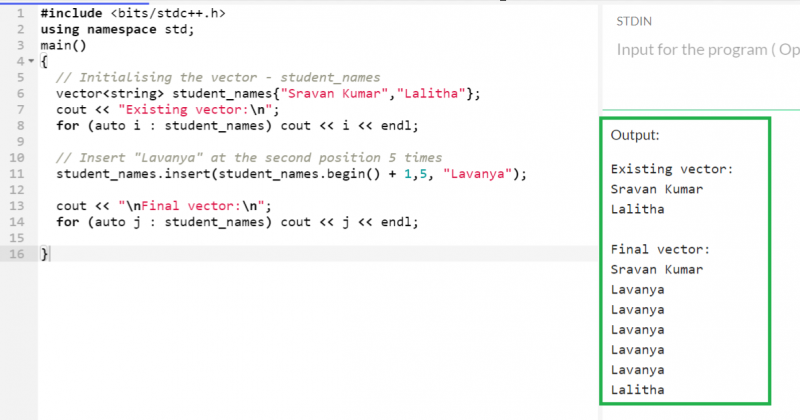
2 つの文字列を持つ「student_names」ベクトルを考えてみましょう。 「Lavanya」の文字列を 2 番目の位置に 5 回挿入します。
#includeを使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルの初期化 -student_names
ベクター < 弦 > 学生名 { 「シュラヴァン・クマール」 、 「ラリサ」 } ;
コート << 「既存のベクトル: \n 」 ;
のために ( 自動 私 : 学生名 ) コート << 私 << 終わり ;
// 2 番目の位置に「Lavanya」を 5 回挿入します
学生名。 入れる ( 学生名。 始める ( ) + 1 、 5 、 「ラヴァーニャ」 ) ;
コート << 」 \n 最終的なベクトル: \n 」 ;
のために ( 自動 j : 学生名 ) コート << j << 終わり ;
}
出力:
既存のベクトルでは、「Sravan Kumar」が 1 番目の位置にあり、「Lalitha」が 2 番目の位置にあります。 「Lavanya」を 5 回(2 位から 6 位まで)挿入した後、「Lalitha」は 7 位(最後)に移動しました。
シナリオ 2: 複数の要素の挿入
このシナリオでは、別のベクトルからさまざまな要素を一度に追加します。ここでも同じ関数を使用しますが、構文とパラメーターが変わります。
構文:
ベクター。 入れる ( 位置、first_iterator、second_iterator ) ;これを行うには、insert() 関数の 2 番目のパラメーターとしてサイズを渡す必要があります。この関数に渡されるパラメータは合計 3 つです。
ここ:
- 位置パラメータは、挿入される要素の位置を指定します。
- 「first_iterator」は、要素が挿入される開始位置を指定します (基本的に、begin() 関数を使用すると、コンテナ内に存在する最初の要素を指すイテレータが返されます)。
- 「second_iterator」は、要素が挿入される終了位置を指定します (基本的に、end() 関数を使用すると、コンテナー内に存在する最後の点の次を指す反復子が返されます)。
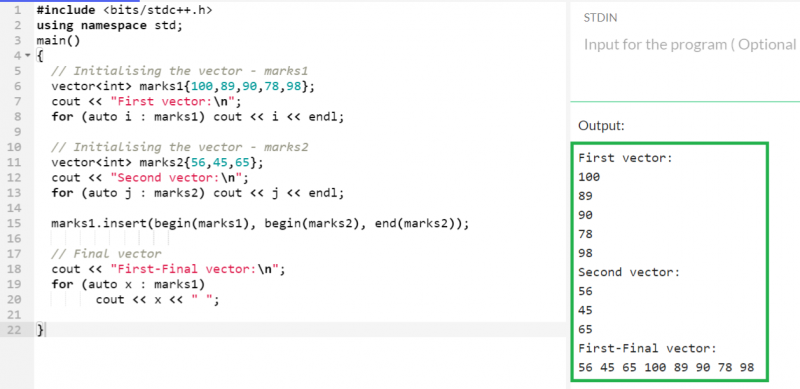
整数型の 2 つのベクトル「marks1」と「marks2」を作成します。 「marks2」ベクトルに存在するすべての要素を「marks1」ベクトルの最初の位置に挿入します。
#include使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルの初期化 - マーク1
ベクター < 整数 > マーク1 { 100 、 89 、 90 、 78 、 98 } ;
コート << 「最初のベクトル: \n 」 ;
のために ( 自動 私 : マーク1 ) コート << 私 << 終わり ;
// ベクトルの初期化 -marks2
ベクター < 整数 > マーク2 { 56 、 4.5 、 65 } ;
コート << 「2番目のベクトル: \n 」 ;
のために ( 自動 j : マーク2 ) コート << j << 終わり ;
マーク1. 入れる ( 始める ( マーク1 ) 、 始める ( マーク2 ) 、 終わり ( マーク2 ) ) ;
// 最終ベクトル
コート << '最初から最後のベクトル: \n 」 ;
のために ( 自動 バツ : マーク1 )
コート << バツ << 「」 ;
}
出力:
最初のベクトル (marks1) は 5 つの要素を保持し、2 番目のベクトル (marks2) は 3 つの要素を保持します。 begin (marks1)、begin(marks2)、end(marks2) パラメータを「insert」関数に渡し、2 番目のベクトルに存在するすべての要素が反復されて最初の最初のベクトルに挿入されるようにしました。したがって、最初のベクトルには 8 つの要素が含まれます。
ベクターから要素にアクセスする
1. [] 演算子の使用
シナリオによっては、ベクトルから特定の要素のみを返す必要がある場合があります。すべての要素を返す必要はありません。したがって、インデックスに基づいて特定の要素のみを返すには、インデックス演算子と at() 関数が利用されます。
構文:
ベクター [ インデックス位置 】C++ では、どのデータ構造でもインデックス付けは 0 から始まります。要素が存在しない場合は、空を返します (エラーや警告は発生しません)。
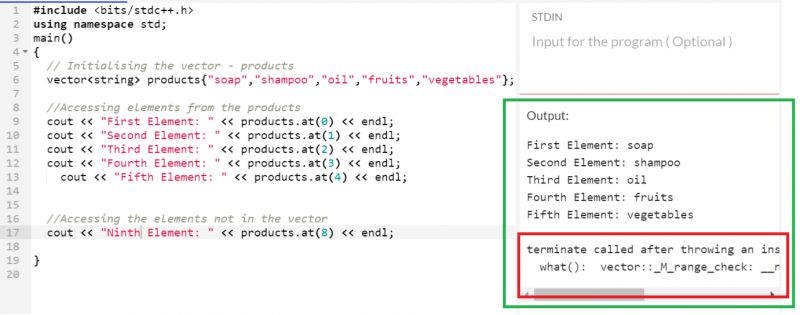
5 つのアイテムを含む「製品」ベクトルを考えてみましょう。インデックス位置を使用して、すべての要素に 1 つずつアクセスします。
#include使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 5 つの文字列の積
ベクター < 弦 > 製品 { '石鹸' 、 'シャンプー' 、 '油' 、 「果物」 、 '野菜' } ;
//プロダクトから要素にアクセスする
コート << 「最初の要素:」 << 製品 [ 0 】 << 終わり ;
コート << 「2番目の要素:」 << 製品 [ 1 】 << 終わり ;
コート << 「第三要素:」 << 製品 [ 2 】 << 終わり ;
コート << 「第四の要素」 << 製品 [ 3 】 << 終わり ;
コート << 「第五の要素」 << 製品 [ 4 】 << 終わり ;
// 9番目の要素にアクセスしてみます
コート << 「第九の要素」 << 製品 [ 8 】 << 終わり ;
}
出力:
インデックス 8 には要素が存在しないため、空が返されます。

2. At() 関数の使用
At() は、前の使用例と似たメンバー関数ですが、範囲外のインデックスが指定された場合に「std::out_of_range」例外を返します。
構文:
ベクター。 で ( インデックス位置 )この関数にインデックス位置を渡す必要があります。
5 つのアイテムを含む「製品」ベクトルを考えてみましょう。インデックス位置を使用してすべての要素に 1 つずつアクセスし、9 番目の位置にある要素にアクセスしてみます。
#include使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 5 つの文字列の積
ベクター < 弦 > 製品 { '石鹸' 、 'シャンプー' 、 '油' 、 「果物」 、 '野菜' } ;
//プロダクトから要素にアクセスする
コート << 「最初の要素:」 << 製品。 で ( 0 ) << 終わり ;
コート << 「2番目の要素:」 << 製品。 で ( 1 ) << 終わり ;
コート << 「第三要素:」 << 製品。 で ( 2 ) << 終わり ;
コート << 「第四の要素」 << 製品。 で ( 3 ) << 終わり ;
コート << 「第五の要素」 << 製品。 で ( 4 ) << 終わり ;
// ベクターにない要素にアクセスする
コート << 「第九の要素」 << 製品。 で ( 8 ) << 終わり ;
}
出力:
9 番目の要素にアクセスするとエラーが発生します。
のインスタンスをスローした後に呼び出される終了 'std::範囲外'何 ( ) : ベクター :: _M_range_check : __n ( それは 8 ) >= これ - > サイズ ( ) ( それは 5 )
ベクター内の要素を更新する
1. [] 演算子の使用
インデックス位置を使用して、ベクトル内の要素を更新できます。 [] 演算子は、更新する必要がある要素のインデックス位置を取得します。新しい要素はこの演算子に割り当てられます。
構文:
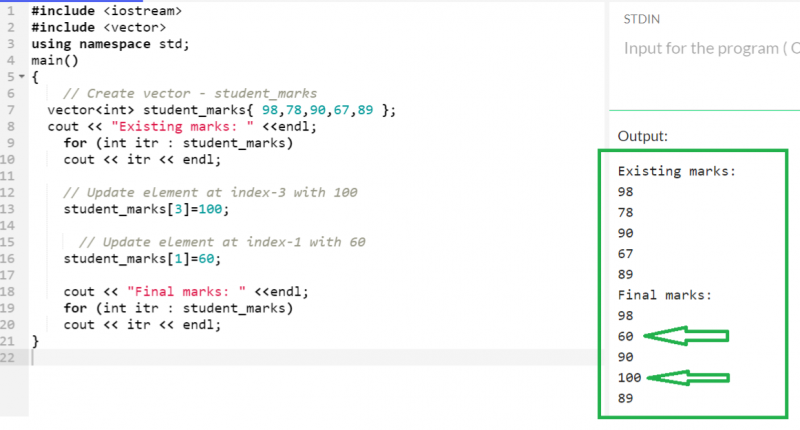
ベクター [ インデックス位置 】 = 要素5 つの値を持つ「student_marks」ベクトルを考えてみましょう。インデックス 1 と 3 に存在する要素を更新します。
#include#include <ベクター>
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - Student_marks
ベクター < 整数 > 学生マーク { 98 、 78 、 90 、 67 、 89 } ;
コート << 「既存のマーク:」 << 終わり ;
のために ( 整数 ITR : 学生マーク )
コート << ITR << 終わり ;
// インデックス 3 の要素を 100 で更新します
学生マーク [ 3 】 = 100 ;
// インデックス 1 の要素を 60 で更新します
学生マーク [ 1 】 = 60 ;
コート << 「最終マーク:」 << 終わり ;
のために ( 整数 ITR : 学生マーク )
コート << ITR << 終わり ;
}
出力:
最終的なベクトルのインデックス 1 と 3 に更新要素が保持されていることがわかります。
2. At() 関数の使用
インデックス演算子と同様に、at() は基本的に、反復子のインデックスに基づいて値を更新するメンバー関数です。この関数内で指定されたインデックスが存在しない場合、「std::out_of_range」例外がスローされます。
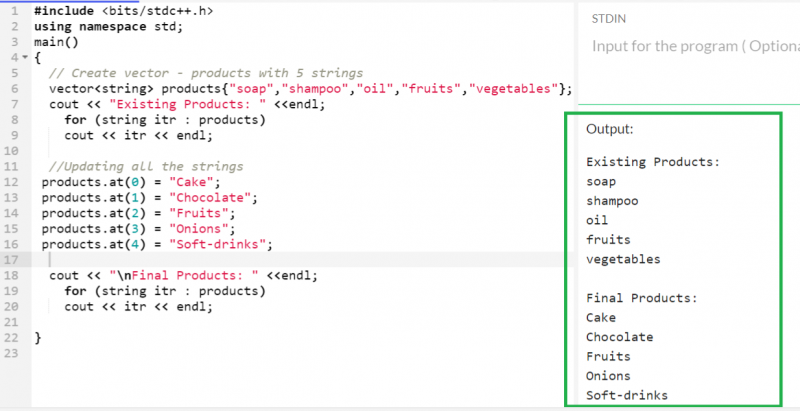
ベクター。 で ( インデックス位置 ) = 要素5 つのアイテムを含む「製品」ベクトルを考えてみましょう。ベクトル内に存在するすべての要素を他の要素で更新します。
#includeを使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 5 つの文字列の積
ベクター < 弦 > 製品 { '石鹸' 、 'シャンプー' 、 '油' 、 「果物」 、 '野菜' } ;
コート << 「既存製品:」 << 終わり ;
のために ( 文字列itr : 製品 )
コート << ITR << 終わり ;
//すべての文字列を更新します
製品。 で ( 0 ) = 'ケーキ' ;
製品。 で ( 1 ) = 'チョコレート' ;
製品。 で ( 2 ) = 「フルーツ」 ;
製品。 で ( 3 ) = '玉ねぎ' ;
製品。 で ( 4 ) = 'ソフトドリンク' ;
コート << 」 \n 最終製品: ' << 終わり ;
のために ( 文字列itr : 製品 )
コート << ITR << 終わり ;
}
出力:
ベクトルから特定の要素を削除する
C++ では、 std::vector::erase() 関数は、ベクトルから特定の要素/要素の範囲を削除するために使用されます。要素はイテレータの位置に基づいて削除されます。
構文:
ベクター。 消す ( イテレータの位置 )ベクトルから特定の要素を削除するための構文を見てみましょう。 begin() 関数または end() 関数を利用して、削除するベクトル内に存在する要素の位置を取得できます。
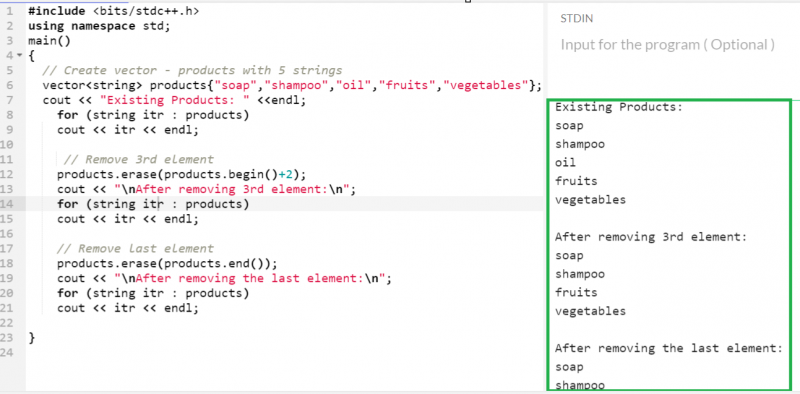
5 つのアイテムを含む「製品」ベクトルを考えてみましょう。
- begin() イテレータを指定して 3 番目の要素を削除します。 Begin() は、ベクトルの最初の要素を指します。この関数に 2 を追加すると、3 番目の要素を指します。
- end() イテレータを指定して最後の要素を削除します。 End() は、ベクトル内の最後の要素を指します。
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 5 つの文字列の積
ベクター < 弦 > 製品 { '石鹸' 、 'シャンプー' 、 '油' 、 「果物」 、 '野菜' } ;
コート << 「既存製品:」 << 終わり ;
のために ( 文字列itr : 製品 )
コート << ITR << 終わり ;
// 3番目の要素を削除
製品。 消す ( 製品。 始める ( ) + 2 ) ;
コート << 」 \n 3 番目の要素を削除した後: \n 」 ;
のために ( 文字列itr : 製品 )
コート << ITR << 終わり ;
// 最後の要素を削除します
製品。 消す ( 製品。 終わり ( ) ) ;
コート << 」 \n 最後の要素を削除した後: \n 」 ;
のために ( 文字列itr : 製品 )
コート << ITR << 終わり ;
}
出力:
さて、「製品」ベクトル内に存在する要素は 3 つ (「石鹸」、「シャンプー」、「果物」) だけです。
ベクターからすべての要素を削除する
シナリオ 1: ベクトルから要素の範囲を削除する
std::vector::erase() 関数を使用して、範囲内の複数の要素を削除してみましょう。
構文:
ベクター。 消す ( 最初のイテレータ、最後のイテレータ )2 つの反復子 (begin() は最初の要素を指し、end() は最後の要素の関数を指します) は、範囲を指定するために使用されます。
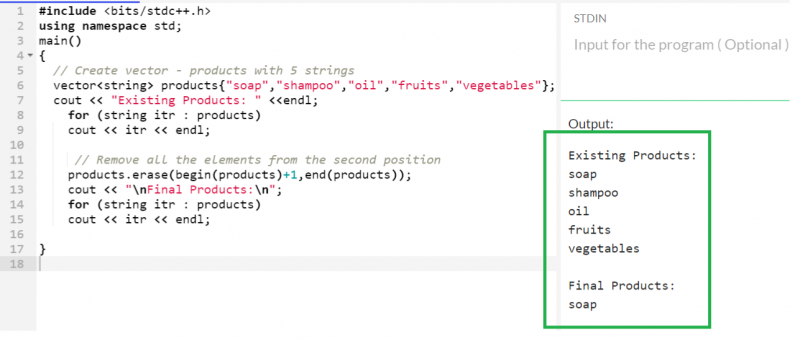
5 つの項目を含む「product」ベクトルを考え、2 番目の位置からすべての要素を削除します。これを実現するには、最初の反復子は 2 番目の要素を指す begin (products)+1 で、2 番目の反復子は end (products) です。
#include使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 5 つの文字列の積
ベクター < 弦 > 製品 { '石鹸' 、 'シャンプー' 、 '油' 、 「果物」 、 '野菜' } ;
コート << 「既存製品:」 << 終わり ;
のために ( 文字列itr : 製品 )
コート << ITR << 終わり ;
// 2 番目の位置からすべての要素を削除します
製品。 消す ( 始める ( 製品 ) + 1 、終わり ( 製品 ) ) ;
コート << 」 \n 最終製品: \n 」 ;
のために ( 文字列itr : 製品 )
コート << ITR << 終わり ;
}
出力:
ここで、「製品」ベクトル内に存在する要素は 1 つ (「石鹸」) だけです。
シナリオ 2: ベクターからすべての要素を削除する
を使ってみましょう std::vector::clear() ベクトルからすべての要素を削除する関数。
構文:
ベクター。 クリア ( )この関数にはパラメータは渡されません。
最初のシナリオで使用されたのと同じベクトルを考慮し、clear() 関数を使用してすべての要素を削除します。
#include使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 5 つの文字列の積
ベクター < 弦 > 製品 { '石鹸' 、 'シャンプー' 、 '油' 、 「果物」 、 '野菜' } ;
コート << 「既存製品:」 << 終わり ;
のために ( 文字列itr : 製品 )
コート << ITR << 終わり ;
// 製品からすべての要素を削除します
製品。 クリア ( ) ;
コート << 」 \n 最終製品: \n 」 ;
のために ( 文字列itr : 製品 )
コート << ITR << 終わり ;
}
出力:
「product」ベクトルには要素がないことがわかります。
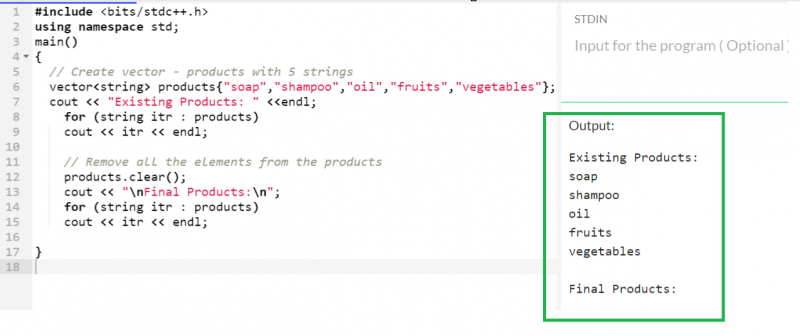
ベクトルの結合
std::set_union() 関数を使用して、ベクトルに対して UNION 演算を実行できます。 Union は、重複要素を無視して、ベクトルから一意の要素を返します。両方のイテレータをこの関数に渡す必要があります。これに加えて、両方の反復子によって返された結果を格納する出力反復子を渡す必要があります。
構文:
セットユニオン ( InputIterator1 first1、InputIterator1 last1、InputIterator2 first2、InputIterator2 last2、OutputIterator res ) ;ここ:
- 「first1」は、最初の反復子 (ベクトル) の最初の要素を指します。
- 「last1」は、最初の反復子 (ベクトル) の最後の要素を指します。
- 「first2」は、2 番目の反復子 (ベクトル) の最初の要素を指します。
- 「last2」は、2 番目のイテレータ (ベクトル) の最後の要素を指します。
整数型の 2 つのベクトル「subjects1」と「subjects2」を作成します。
- sort() 関数を使用して反復子を渡して 2 つのベクトルを並べ替えます。
- 出力ベクトル (反復子) を作成します。
- std::set_union() 関数を使用して、これら 2 つのベクトルの和集合を見つけます。最初のイテレータとして begin() を使用し、最後のイテレータとして end() を使用します。
- 出力ベクトルを反復して、関数によって返された要素を表示します。
#include
#include <ベクター>
使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - マーク1
ベクター < 整数 > マーク1 = { 100 、 90 、 80 、 70 、 60 } ;
// ベクトルを作成 - マーク2
ベクター < 整数 > マーク2 = { 80 、 90 、 60 、 70 、 100 } ;
// 両方のベクトルをソートします
選別 ( マーク1. 始める ( ) 、マーク1。 終わり ( ) ) ;
選別 ( マーク2. 始める ( ) 、マーク2。 終わり ( ) ) ;
ベクター < 整数 > 出力ベクトル ( マーク1. サイズ ( ) + マーク2. サイズ ( ) ) ;
ベクター < 整数 > :: イテレータ は ;
私 = セットユニオン ( マーク1. 始める ( ) 、マーク1。 終わり ( ) 、
マーク2. 始める ( ) 、マーク2。 終わり ( ) 、
出力ベクトル。 始める ( ) ) ;
コート << 」 \n マーク1 U マーク2: \n 」 ;
のために ( s = 出力ベクトル。 始める ( ) ; s ! = 私 ; ++ s )
コート << * s << 「」 << ' \n ' ;
}
出力:
両方のベクトル (subject1 と subject2) には、固有の要素が 5 つだけあります。
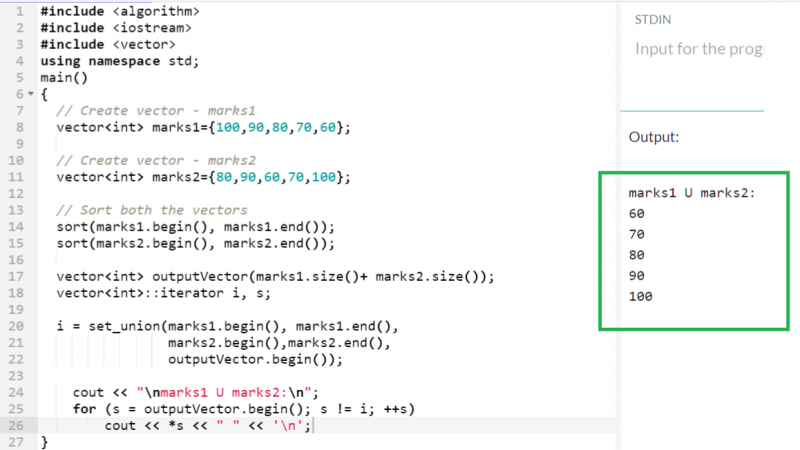
ベクトルの交差
std::set_intersection() 関数を使用すると、2 つのベクトルの交差部分を見つけることができます。 Intersection は、両方のベクトルに存在する要素を返します。
構文:
set_intersection ( InputIterator1 first1、InputIterator1 last1、InputIterator2 first2、InputIterator2 last2、OutputIterator res ) ;set_union() 関数に渡されるパラメータは、この set_intersection() 関数にも渡すことができます。
整数型の 2 つのベクトル「subjects1」と「subjects2」を作成します。
- sort() 関数を使用して反復子を渡して 2 つのベクトルを並べ替えます。
- 出力ベクトル (反復子) を作成します。
- std::set_intersection() 関数を使用して、これら 2 つのベクトルの交差部分を見つけます。最初のイテレータとして begin() を使用し、最後のイテレータとして end() を使用します。
- 出力ベクトルを反復して、関数によって返される要素を表示します。
#include
#include <ベクター>
使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - マーク1
ベクター < 整数 > マーク1 = { 100 、 10 、 80 、 40 、 60 } ;
// ベクトルを作成 - マーク2
ベクター < 整数 > マーク2 = { 50 、 90 、 60 、 10 、 100 } ;
// 両方のベクトルをソートします
選別 ( マーク1. 始める ( ) 、マーク1。 終わり ( ) ) ;
選別 ( マーク2. 始める ( ) 、マーク2。 終わり ( ) ) ;
ベクター < 整数 > 出力ベクトル ( マーク1. サイズ ( ) + マーク2. サイズ ( ) ) ;
ベクター < 整数 > :: イテレータ は ;
私 = set_intersection ( マーク1. 始める ( ) 、マーク1。 終わり ( ) 、
マーク2. 始める ( ) 、マーク2。 終わり ( ) 、
出力ベクトル。 始める ( ) ) ;
コート << 」 \n マーク1 ∩ マーク2: \n 」 ;
のために ( s = 出力ベクトル。 始める ( ) ; s ! = 私 ; ++ s )
コート << * s << 「」 << ' \n ' ;
}
出力:
両方のベクトル (subjects1 と subject2) に存在する要素は 3 つだけです。
ベクトルが空かどうかを確認する
ベクトルを操作する前に、ベクトルが空かどうかを確認することが重要です。ソフトウェア プロジェクトでは、CRUD 操作などの操作を実行する前にベクターが空かどうかを確認することも推奨されます。
1. Std::vector::empty() の使用
この関数は、ベクトルが空の場合 (要素が含まれていない場合) 1 を返します。それ以外の場合は 0 が返されます。この関数にはパラメータは渡されません。
2. Std::vector::size()
std::vector::size() 関数は、ベクトル内に存在する要素の合計数を表す整数を返します。
2 つのベクトル「college1」と「college2」を作成します。 「College1」には 5 つの要素が含まれており、「college2」は空です。両方の関数を両方のベクトルに適用し、出力を確認します。
#include <アルゴリズム>#include
#include <ベクター>
使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - college1
ベクター < 弦 > 大学1 = { 「カレッジA」 、 「カレッジB」 、 「カレッジC」 、 「カレッジD」 、 「カレッジE」 } ;
// ベクトルを作成 - college2
ベクター < 弦 > 大学2 ;
// 空の()
コート << 大学1. 空の ( ) << 終わり ;
コート << 大学2. 空の ( ) << 終わり ;
// サイズ()
コート << 大学1. サイズ ( ) << 終わり ;
コート << 大学2. サイズ ( ) << 終わり ;
}
出力:
empty() 関数は、「college1」の場合は 0 を返し、「college2」の場合は 1 を返します。 size() 関数は、「college1」の場合は 5 を返し、「college2」の場合は 0 を返します。

Const_Iterator を使用してベクトルを走査する
セットやベクターなどの C++ コンテナーを操作する場合、コンテナー内に存在するすべての要素を変更せずに反復処理することができます。の const_iterator は、このシナリオを実現するイテレータの 1 つです。 cbegin() (ベクトルの最初の要素を指す) と cend() (ベクトルの最後の要素を指す) は、各コンテナによって提供される 2 つの関数で、定数反復子をコンテナの先頭と末尾に返すために使用されます。コンテナ。ベクトルを反復するときに、これら 2 つの関数を利用できます。
- 5 つの文字列を含む「Departments」という名前のベクトルを作成しましょう。
-
型の const_iterator – ctr を宣言します。 - 「for」ループを使用して前のイテレータを使用して部門を反復処理し、それを表示します。
#include <ベクター>
使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 部門
ベクター < 弦 > 部門 = { 「販売」 、 'サービス' 、
「人事」 、 'それ' 、 「その他」 } ;
ベクター < 弦 > :: const_iterator 中央 ;
// const_iterator - ctr を使用して部門を反復処理します。
のために ( 中央 = 部門。 始める ( ) ; 中央 ! = 部門。 いくつかの ( ) ; 中央 ++ ) {
コート << * 中央 << 終わり ;
}
}
出力:

Reverse_Iterator を使用してベクトルを走査する
の reverse_iterator これも const_iterator に似たイテレータですが、要素を逆に返します。 rbegin() (ベクトルの最後の要素を指す) と rend() (ベクトルの最初の要素を指す) は、各コンテナによって提供される 2 つの関数で、定数反復子をコンテナの終わりと始まりに返すために使用されます。コンテナ。
- 5 つの文字列を含む「Departments」という名前のベクトルを作成しましょう。
-
型の reverse_iterator – rtr を宣言します。 - 「for」ループを使用して前のイテレータを使用して部門を反復処理し、それを表示します。
#include <ベクター>
使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 部門
ベクター < 弦 > 部門 = { 「販売」 、 'サービス' 、
「人事」 、 'それ' 、 「その他」 } ;
ベクター < 弦 > :: reverse_iterator RTR ;
// reverse_iterator - rtr を使用して部門を反復処理します。
のために ( RTR = 部門。 始める ( ) ; RTR ! = 部門。 作る ( ) ; RTR ++ ) {
コート << * RTR << 終わり ;
}
}
出力:

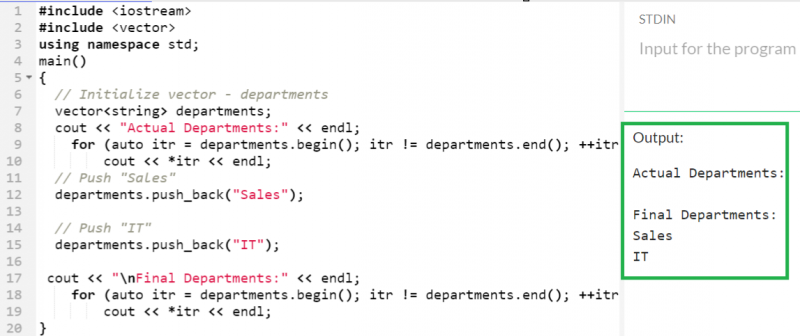
要素をベクターにプッシュします
要素をベクターにプッシュまたは追加することは、一方向の挿入であり、 ベクトル::push_back() 関数。
構文:
ベクター。 プッシュバック ( 要素 )ベクトルにプッシュされる要素をパラメータとして受け取ります。
5 つの文字列を含む「Departments」という名前の空のベクトルを作成し、push_back() 関数を使用して 2 つの文字列を順番にプッシュしてみましょう。
#include#include <ベクター>
使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルの初期化 - 部門
ベクター < 弦 > 部門 ;
コート << 「実際の部門:」 << 終わり ;
のために ( 自動 ITR = 部門。 始める ( ) ; ITR ! = 部門。 終わり ( ) ; ++ ITR )
コート << * ITR << 終わり ;
// 「売上」を押します
部門。 プッシュバック ( 「販売」 ) ;
// 押して'
部門。 プッシュバック ( 'それ' ) ;
コート << 」 \n 最終部門:' << 終わり ;
のために ( 自動 ITR = 部門。 始める ( ) ; ITR ! = 部門。 終わり ( ) ; ++ ITR )
コート << * ITR << 終わり ;
}
出力:
まずは「Sales」を押します。その後、「IT」をベクトルに押し込みます。ここで、「部門」ベクトルには 2 つの要素が含まれています。
ベクトルから要素をポップする
ベクター内に存在する最後の項目を削除したい場合は、 ベクトル::ポップバック() 関数が最良のアプローチです。ベクター内に存在する最後の要素を削除します。
構文:
ベクター。 ポップバック ( )この関数にはパラメータは必要ありません。空のベクトルから最後の要素を削除しようとすると、未定義の動作が表示されます。
5 つの文字列を含む「Departments」という名前の空のベクトルを作成し、前の関数を使用して最後の要素を削除しましょう。どちらの場合もベクトルを表示します。
#include#include <ベクター>
使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルの初期化 - 部門
ベクター < 弦 > 部門 = { 「販売」 、 'それ' 、 'サービス' 、 'マーケティング' 、 「人事」 } ;
コート << 「実際の部門:」 << 終わり ;
のために ( 自動 ITR = 部門。 始める ( ) ; ITR ! = 部門。 終わり ( ) ; ++ ITR )
コート << * ITR << 終わり ;
// 最後の要素を削除
部門。 ポップバック ( ) ;
コート << 」 \n 最終部門:' << 終わり ;
のために ( 自動 ITR = 部門。 始める ( ) ; ITR ! = 部門。 終わり ( ) ; ++ ITR )
コート << * ITR << 終わり ;
}
出力:
「HR」は「部門」ベクトルに存在する最後の要素です。したがって、これがベクトルから削除され、最終的なベクトルには「Sales」、「IT」、「Service」、「Marketing」が含まれます。
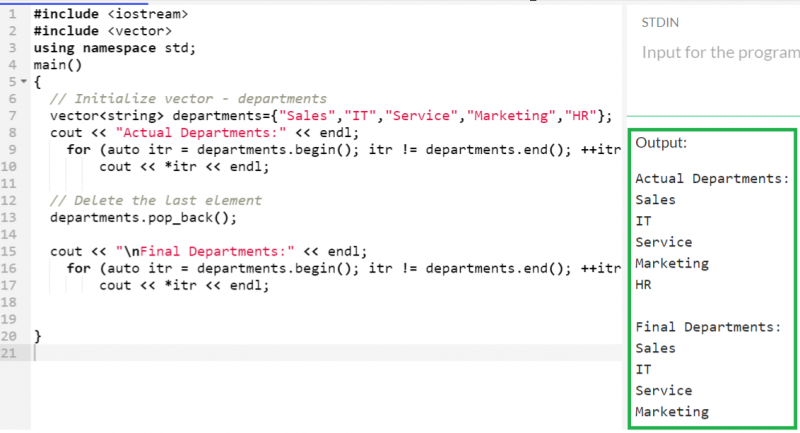
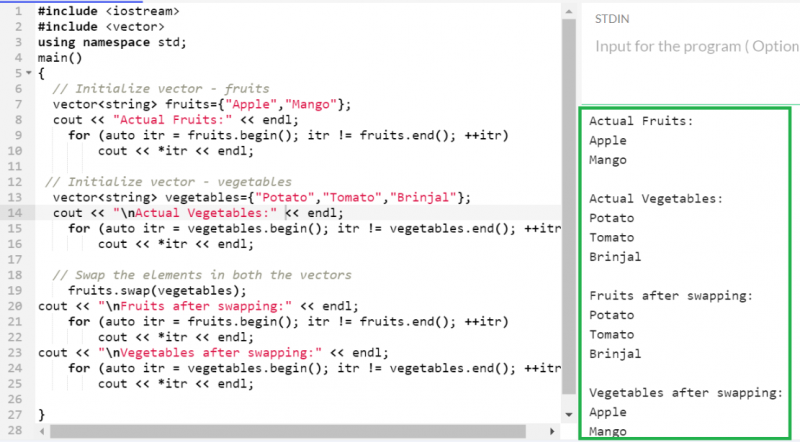
ベクトルを交換する
の ベクトル::スワップ() C++ STL の関数は、2 つのベクトルに存在するすべての要素を交換するために使用されます。
構文:
最初のベクトル。 スワップ ( セカンドベクトル )ベクトルのサイズは考慮されませんが、ベクトルは同じ型である必要があります (ベクトルの型が異なる場合はエラーがスローされます)。
サイズの異なる文字列型の 2 つのベクトル「果物」と「野菜」を作成してみましょう。それぞれを入れ替えて、両方の場合のベクトルを表示します。
#include#include <ベクター>
使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルの初期化 - 果物
ベクター < 弦 > 果物 = { 'りんご' 、 'マンゴー' } ;
コート << 「実際の果物」 << 終わり ;
のために ( 自動 ITR = 果物。 始める ( ) ; ITR ! = 果物。 終わり ( ) ; ++ ITR )
コート << * ITR << 終わり ;
// ベクターの初期化 - 野菜
ベクター < 弦 > 野菜 = { 'じゃがいも' 、 'トマト' 、 「ナス」 } ;
コート << 」 \n 実際の野菜:」 << 終わり ;
のために ( 自動 ITR = 野菜。 始める ( ) ; ITR ! = 野菜。 終わり ( ) ; ++ ITR )
コート << * ITR << 終わり ;
// 両方のベクトルの要素を交換します
果物。 スワップ ( 野菜 ) ;
コート << 」 \n 交換後の果物:」 << 終わり ;
のために ( 自動 ITR = 果物。 始める ( ) ; ITR ! = 果物。 終わり ( ) ; ++ ITR )
コート << * ITR << 終わり ;
コート << 」 \n 交換後の野菜:」 << 終わり ;
のために ( 自動 ITR = 野菜。 始める ( ) ; ITR ! = 野菜。 終わり ( ) ; ++ ITR )
コート << * ITR << 終わり ;
}
出力:
以前は、「果物」ベクトルは 2 つの要素を保持し、「野菜」ベクトルは 3 つの要素を保持していました。交換後、「果物」ベクトルは 3 つの要素を保持し、「野菜」ベクトルは 2 つの要素を保持します。
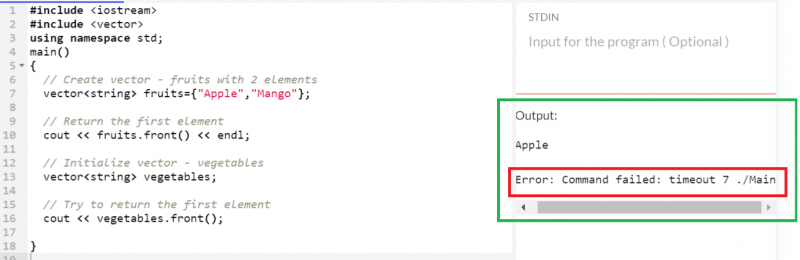
ベクターから最初の要素をフェッチする
場合によっては、ベクトルから最初の要素のみを返すことが要件となることがあります。 C++ STL の Vector::front() 関数は、ベクターから最初の要素のみをフェッチします。
構文:
ベクター。 フロント ( )この関数はパラメータを取りません。ベクトルが空の場合、エラーがスローされます。
文字列型の 2 つのベクトル「果物」と「野菜」を作成し、2 つのベクトルから別々に最初の要素を取得してみます。
#include#include <ベクター>
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 2 つの要素を持つ果物
ベクター < 弦 > 果物 = { 'りんご' 、 'マンゴー' } ;
// 最初の要素を返します
コート << 果物。 フロント ( ) << 終わり ;
// ベクターの初期化 - 野菜
ベクター < 弦 > 野菜 ;
// 最初の要素を返してみます
コート << 野菜。 フロント ( ) ;
}
出力:
「リンゴ」は「果物」ベクトルに存在する最初の要素です。ということで、返品です。しかし、「vegetables」ベクトルから最初の要素を取得しようとすると、それが空であるため、エラーがスローされます。
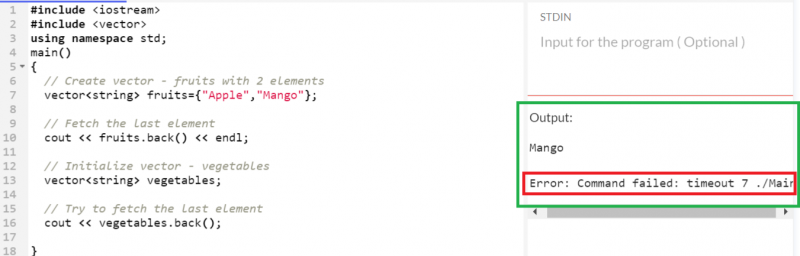
ベクターから最後の要素を取得する
C++ STL の Vector::end() 関数は、ベクターから最後の要素のみをフェッチします。
構文:
ベクター。 戻る ( )この関数はパラメータを取りません。ベクトルが空の場合、エラーがスローされます。
文字列型の 2 つのベクトル「果物」と「野菜」を作成し、2 つのベクトルから別々に最後の要素を取得してみます。
#include#include <ベクター>
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - 2 つの要素を持つ果物
ベクター < 弦 > 果物 = { 'りんご' 、 'マンゴー' } ;
// 最後の要素を取得します
コート << 果物。 戻る ( ) << 終わり ;
// ベクターの初期化 - 野菜
ベクター < 弦 > 野菜 ;
// 最後の要素を取得してみます
コート << 野菜。 戻る ( ) ;
}
出力:
「マンゴー」は、「フルーツ」ベクターに存在する最後の要素です。ということで、返品です。しかし、「vegetables」ベクトルから最後の要素を取得しようとすると、それが空であるため、エラーがスローされます。
新しい値をベクトルに代入する
一部のシナリオでは、すべての値を新しい値で更新する場合、または同じ値でベクトルを作成する場合、vector::assign() 関数を使用することが最善の方法です。この関数を使用すると、次のことが可能になります。
- 同様の要素をすべて含むベクトルを作成する
- 同じ要素を使用して既存のベクトルを変更します
構文:
ベクター。 割当 ( サイズ、値 )この関数には 2 つのパラメータが必要です。
ここ:
- サイズは、割り当てる要素の数を指定します。
- 値は割り当てる要素を指定します。
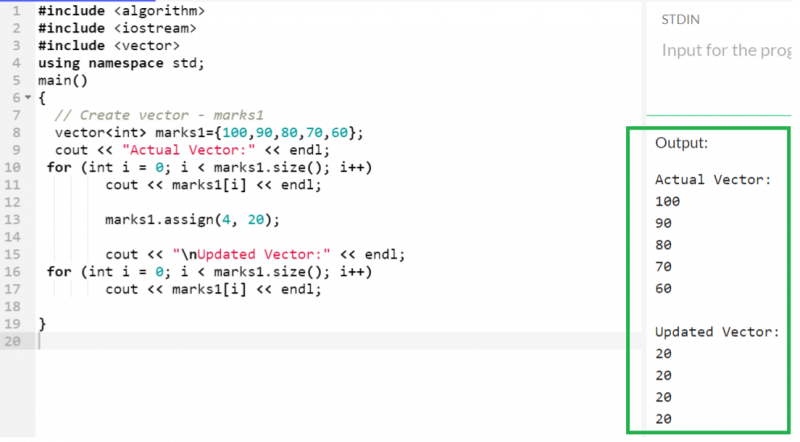
5 つの値を持つ「marks1」という名前のベクトルを作成し、更新されたベクトル内のすべての要素が 20 になるように、このベクトルを 4 つの要素で更新してみましょう。
#include <アルゴリズム>#include
#include <ベクター>
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - マーク1
ベクター < 整数 > マーク1 = { 100 、 90 、 80 、 70 、 60 } ;
コート << 「実際のベクトル:」 << 終わり ;
のために ( 整数 私 = 0 ; 私 < マーク1. サイズ ( ) ; 私 ++ )
コート << マーク1 [ 私 】 << 終わり ;
マーク1. 割当 ( 4 、 二十 ) ;
コート << 」 \n 更新されたベクター:' << 終わり ;
のために ( 整数 私 = 0 ; 私 < マーク1. サイズ ( ) ; 私 ++ )
コート << マーク1 [ 私 】 << 終わり ;
}
出力:
以前は、ベクトルには 5 つの異なる要素が含まれていました。現在、保持している要素は 4 つだけで、すべてが 20 に等しくなります。
Emplace() を使用してベクトルを拡張する
新しい要素がベクトル内の任意の位置に動的に挿入されることはすでにわかっています。 Vector::emplace() 関数を使用すると可能です。この関数で受け入れられる構文とパラメーターを簡単に見てみましょう。
構文:
ベクター。 位置 ( const_iterator 位置、要素 )2 つの必須パラメータがこの関数に渡されます。
ここ:
- 最初のパラメータは位置を取得するため、任意の位置に要素を挿入できます。 begin() または end() イテレータ関数を使用して位置を取得できます。
- 2 番目のパラメーターは、ベクトルに挿入される要素です。
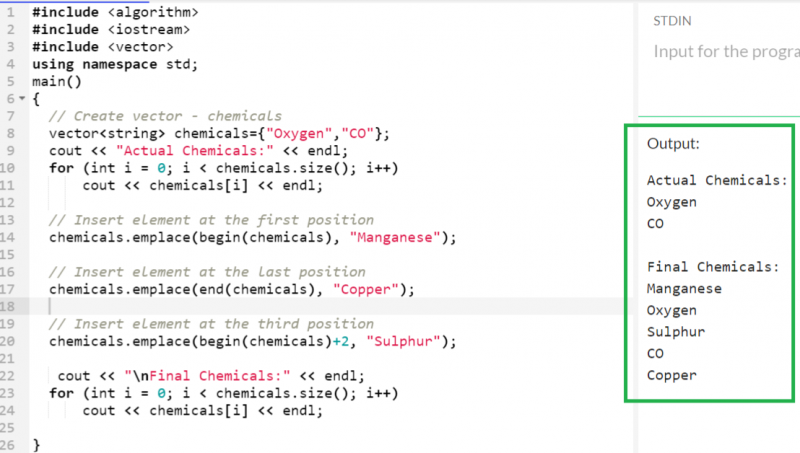
2 つの要素を持つ「化学物質」ベクトルを考えてみましょう。
- 最初の位置に「マンガン」を挿入します – begin(chemicals)
- 最後の位置に「銅」を挿入 – 終了(化学薬品)
- 3 番目の位置に「硫黄」を挿入します – begin(chemicals)+2
#include
#include <ベクター>
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクターを作成 - 化学物質
ベクター < 弦 > 化学薬品 = { '酸素' 、 「コ」 } ;
コート << 「実際の化学物質」 << 終わり ;
のために ( 整数 私 = 0 ; 私 < 化学物質。 サイズ ( ) ; 私 ++ )
コート << 化学薬品 [ 私 】 << 終わり ;
// 最初の位置に要素を挿入
化学物質。 位置 ( 始める ( 化学薬品 ) 、 'マンガン' ) ;
// 要素を最後の位置に挿入
化学物質。 位置 ( 終わり ( 化学薬品 ) 、 '銅' ) ;
// 要素を 3 番目の位置に挿入します
化学物質。 位置 ( 始める ( 化学薬品 ) + 2 、 '硫黄' ) ;
コート << 」 \n 最終化学物質:' << 終わり ;
のために ( 整数 私 = 0 ; 私 < 化学物質。 サイズ ( ) ; 私 ++ )
コート << 化学薬品 [ 私 】 << 終わり ;
}
出力:
現在、最終的なベクトルには 5 つの要素が含まれています (次のスクリーンショットを参照)。
Emplace_Back() を使用してベクトルを拡張する
要素を追加 (ベクトルの最後に追加) することができます。これは、 ベクトル::emplace_back() 関数。
構文:
ベクター。 emplace_back ( 要素 )ベクトルに追加する要素をパラメータとして渡すことが必須です。
emplace_back() 関数を使用して 2 つの要素を順番に追加してみましょう。
#include <アルゴリズム>#include
#include <ベクター>
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクターを作成 - 化学物質
ベクター < 弦 > 化学薬品 = { '酸素' 、 「コ」 } ;
コート << 「実際の化学物質」 << 終わり ;
のために ( 整数 私 = 0 ; 私 < 化学物質。 サイズ ( ) ; 私 ++ )
コート << 化学薬品 [ 私 】 << 終わり ;
// ベクターの最後にマンガンを挿入します
化学物質。 emplace_back ( 'マンガン' ) ;
// ベクターの最後にマンガンを挿入します
化学物質。 emplace_back ( '銅' ) ;
コート << 」 \n 最終化学物質:' << 終わり ;
のために ( 整数 私 = 0 ; 私 < 化学物質。 サイズ ( ) ; 私 ++ )
コート << 化学薬品 [ 私 】 << 終わり ;
}
出力:
これで、「マンガン」と「銅」を追加した後の最終的なベクトルには 4 つの要素が保持されます。

ベクトルの最大要素
- いくつかの要素を含むベクトルを作成します。
- ベクトル内に存在する最大の要素を見つけるには、引数として 2 つの反復子を受け入れる *max_element() 関数を使用します。これら 2 つのパラメータは範囲として機能し、指定された範囲内で最大の要素が返されます。開始位置は begin() で、最後の位置は end() です。
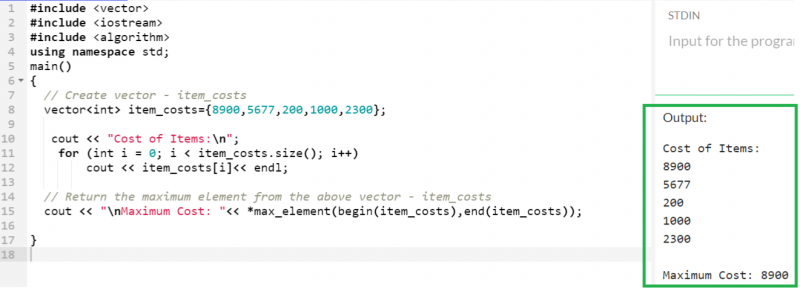
5 つの整数型の値を保持し、最大の要素を返す「item_costs」という名前のベクトルを考えてみましょう。
#include <ベクター>#include
#include <アルゴリズム>
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - item_costs
ベクター < 整数 > アイテムコスト = { 8900 、 5677 、 200 、 1000 、 2300 } ;
コート << 「アイテムのコスト: \n 」 ;
のために ( 整数 私 = 0 ; 私 < item_costs。 サイズ ( ) ; 私 ++ )
コート << アイテムコスト [ 私 】 << 終わり ;
// 上記のベクトルから最大の要素を返します - item_costs
コート << 」 \n 最大コスト: ' << * 最大要素 ( 始める ( アイテムコスト ) 、終わり ( アイテムコスト ) ) ;
}
出力:
ここで、8900 は、「item_costs」ベクトルに存在するすべての要素の中で最大の要素です。
ベクトルの最小要素
- いくつかの要素を含むベクトルを作成します。
- ベクトル内に存在する最小要素を見つけるには、2 つの反復子を引数として受け入れる *min_element() 関数を使用します。これら 2 つのパラメーターは範囲として機能し、指定された範囲内で最小要素 (他のすべての要素より小さい) が返されます。開始位置は begin() で、最後の位置は end() です。
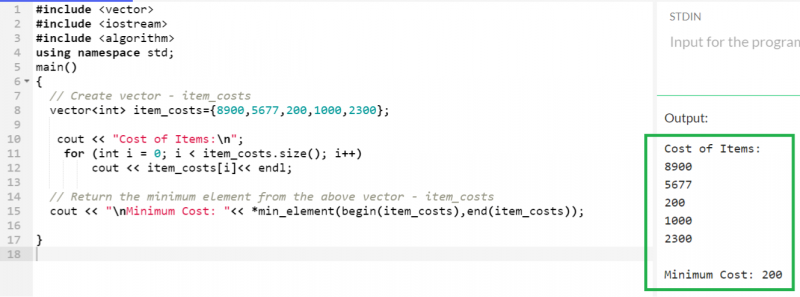
*min_element() 関数を使用して、最大要素を見つけるために作成されたものと同じベクトルを使用し、最小要素を見つけます。
#include <ベクター>#include
#include <アルゴリズム>
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - item_costs
ベクター < 整数 > アイテムコスト = { 8900 、 5677 、 200 、 1000 、 2300 } ;
コート << 「アイテムのコスト: \n 」 ;
のために ( 整数 私 = 0 ; 私 < item_costs。 サイズ ( ) ; 私 ++ )
コート << アイテムコスト [ 私 】 << 終わり ;
// 上記のベクトルから最小要素を返します - item_costs
コート << 」 \n 最小コスト: ' << * min_element ( 始める ( アイテムコスト ) 、終わり ( アイテムコスト ) ) ;
}
出力:
ここで、200 は、「item_costs」ベクトルに存在するすべての要素の中で最小の要素です。
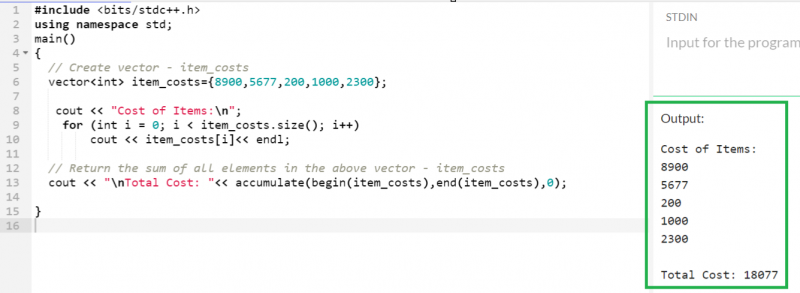
ベクトル内の要素の合計
ベクトル内に存在するすべての要素の合計を返すには、 蓄積() C++ STL の関数が使用されます。 3 つのパラメータを受け入れます。最初のパラメーターは範囲内の開始要素を表す最初のインデックスを受け取り (begin() イテレーターを指定)、2 番目のパラメーターは範囲内の終了要素を表す最後のインデックスを受け取ります (end() イテレーターを指定)。最後に、合計の初期値 (この場合は 0) を渡す必要があります。
蓄積する ( first_index、last_index、initial_val ) ;5 つの整数型要素を含む「item_costs」という名前のベクトルを作成し、合計を計算します。
#includeを使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成 - item_costs
ベクター < 整数 > アイテムコスト = { 8900 、 5677 、 200 、 1000 、 2300 } ;
コート << 「アイテムのコスト: \n 」 ;
のために ( 整数 私 = 0 ; 私 < item_costs。 サイズ ( ) ; 私 ++ )
コート << アイテムコスト [ 私 】 << 終わり ;
// 上記のベクトルのすべての要素の合計を返します - item_costs
コート << 」 \n 総費用: ' << 蓄積する ( 始める ( アイテムコスト ) 、終わり ( アイテムコスト ) 、 0 ) ;
}
出力:
8900、5677、200、1000、2300の合計は18077です。
2 つのベクトルの要素ごとの乗算
- 数値型の 2 つのベクトルを作成します。2 つのベクトルは同じサイズでなければなりません (最初のベクトルに存在する要素の合計数 = 2 番目のベクトルに存在する要素の合計数)。
- 新しいベクトルを宣言し、 for ループ 、各反復で 2 つの要素に対して乗算演算を実行し、push_back() 関数を使用して作成されたベクトルに値を格納します。 のために ( 整数 ITR = 0 ; 私 < first_vec。 サイズ ( ) ; ITR ++ )
- 結果のベクトルを反復して、そのベクトルに存在する要素を表示します。
{
結果ベクトル。 プッシュバック ( first_vec [ ITR 】 * 秒のもの [ ITR 】 ) ;
}
5 つの整数型要素を含む「item_costs」という名前のベクトルを作成し、合計を計算します。
#includeを使用して 名前空間 標準 ;
主要 ( )
{
// それぞれ 5 つの要素を持つ 2 つのベクトル、products1 と products2 を作成します
ベクター < 整数 > 製品1 = { 10 、 二十 、 30 、 40 、 50 } ;
ベクター < 整数 > 製品2 = { 50 、 40 、 30 、 70 、 60 } ;
ベクター < 整数 > 結果_製品 ;
// 要素ごとの乗算を実行します
のために ( 整数 私 = 0 ; 私 < 製品1. サイズ ( ) ; 私 ++ ) {
結果_製品。 プッシュバック ( 製品1 [ 私 】 * 製品2 [ 私 】 ) ;
}
// 結果のベクトルを表示します
コート << 「ベクトルの乗算: \n 」 ;
のために ( 整数 レス : 結果_製品 )
コート << レス << 終わり ;
}
出力:
反復 - 1 : 10 * 50 => 500反復 - 2 : 二十 * 40 => 800
反復 - 3 : 30 * 30 => 900
反復 - 4 : 40 * 70 => 2800
反復 - 5 : 50 * 60 => 3000

2 つのベクトルの内積
C++ ベクトルの場合、ドット積は「2 つのベクトル シーケンスの対応するエントリの積の合計」として定義されます。
構文:
内部製品 ( 最初に Vector1、最後に Vector1、最初に Vector2、Initial_Val )inner_product() 関数を使用してドット積を返します。この関数は 4 つの必須パラメータを受け取ります。
ここ:
- 最初のパラメーターは、最初のベクトルの先頭を指す反復子を参照します (begin() 関数を使用して指定します)。
- 2 番目のパラメーターは、最初のベクトルの終わりを指す反復子を参照します (end() 関数を使用して指定します)。
- 3 番目のパラメーターは、2 番目のベクトルの先頭を指す反復子を参照します (begin() 関数を使用して指定します)。
- 初期値は、ドット積を累算するための整数である最後のパラメータとして渡す必要があります。
2 つのベクトルの乗算用に作成されたものと同じプログラムを利用し、 innsr_product() 関数を使用して 2 つのベクトルの内積を求めます。
#includeを使用して 名前空間 標準 ;
主要 ( )
{
// それぞれ 5 つの要素を持つ 2 つのベクトル、products1 と products2 を作成します
ベクター < 整数 > 製品1 = { 10 、 二十 、 30 、 40 、 50 } ;
ベクター < 整数 > 製品2 = { 50 、 40 、 30 、 70 、 60 } ;
// 結果のベクトルを表示します
コート << 「products1 と products2 の内積:」 ;
コート << 内部製品 ( 始める ( 製品1 ) 、終わり ( 製品1 ) 、始める ( 製品2 ) 、 0 ) ;
}
出力:
( 10 * 50 ) + ( 二十 * 40 ) + ( 30 * 30 ) + ( 40 * 70 ) + ( 50 * 60 )=> 500 + 800 + 900 + 2800 + 3000
=> 8000

セットをベクトルに変換する
セット内で発生するすべての要素をベクトルに渡すことによって、セットをベクトルに変換する方法は数多くあります。最も簡単な最良の方法は、std::copy() 関数を使用することです。
構文
標準 :: コピー ( 最初にsourceIterator、最後にsourceIterator、最初にdestinationIterator )使用 std::copy() セットの要素をベクトルに挿入する関数。 3 つのパラメータを取ります。
ここ:
- 最初のパラメータは、イテレータ内の最初の要素を指すソース イテレータを参照します。ここで、set は begin() 関数を使用して指定されたソース反復子です。
- 同様に、2 番目のパラメーターは最後の要素 (end() 関数) を指します。
- 3 番目のパラメータは、イテレータ内の最初の要素(begin() 関数を使用して指定)を指す宛先イテレータを参照します。
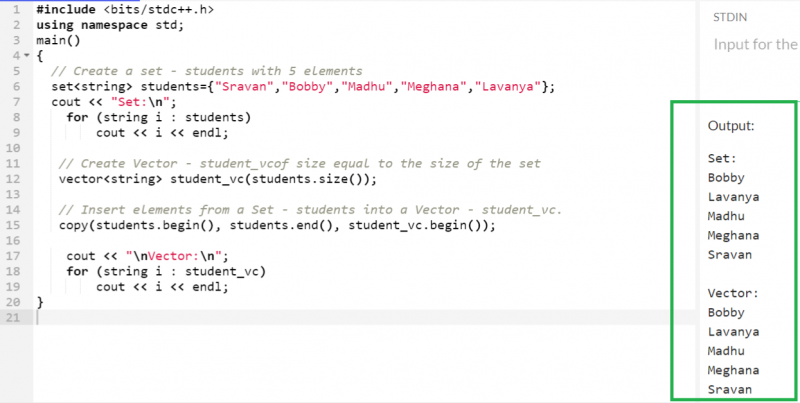
5 人の生徒のセットを作成し、前の関数を使用してすべての要素をベクトルにコピーしてみましょう。
#includeを使用して 名前空間 標準 ;
主要 ( )
{
// セットを作成します - 5 つの要素を持つ生徒
セット < 弦 > 学生 = { 「スラヴァン」 、 「ボビー」 、 「マドゥ」 、 「メガナ」 、 「ラヴァーニャ」 } ;
コート << 'セット: \n 」 ;
のために ( 文字列i : 学生 )
コート << 私 << 終わり ;
// ベクターを作成 - Student_vcof のサイズはセットのサイズと同じ
ベクター < 弦 > 学生VC ( 学生。 サイズ ( ) ) ;
// Set - students から Vector -student_vc に要素を挿入します。
コピー ( 学生。 始める ( ) 、 学生。 終わり ( ) 、student_vc。 始める ( ) ) ;
コート << 」 \n ベクター: \n 」 ;
のために ( 文字列i : 学生VC )
コート << 私 << 終わり ;
}
出力:
これで、「Students」セットに存在するすべての要素が「students_vc」ベクトルにコピーされます。
重複した要素を削除する
- まず、ベクトル内の要素を並べ替えて、すべての重複要素が互いに隣接するようにする必要があります。 std::sort() 関数。 標準 :: 選別 ( 最初のベクトル、最後のベクトル ) ;
- std::unique() 関数を使用して、重複した要素が選択されるようにします。同時に、erase() 関数を使用して、std::unique() 関数によって返された重複を削除します。最終的なベクトルでは要素の順序が変わる場合があります。 ベクター。 消す ( 標準 :: 個性的 ( 最初のベクトル、最後のベクトル ) 、ベクトルの最後 ) )
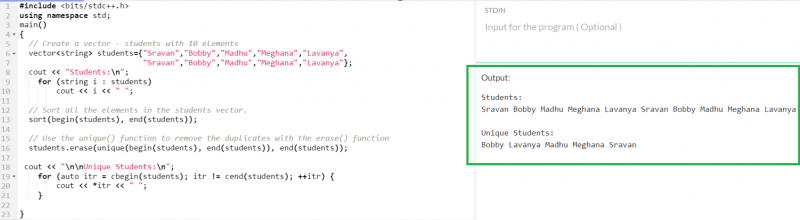
10 個の要素を含む「students」ベクトルを作成し、重複を削除してベクトルを返します。
#include使用して 名前空間 標準 ;
主要 ( )
{
// ベクトルを作成します - 10 個の要素を持つ生徒
ベクター < 弦 > 学生 = { 「スラヴァン」 、 「ボビー」 、 「マドゥ」 、 「メガナ」 、 「ラヴァーニャ」 、
「スラヴァン」 、 「ボビー」 、 「マドゥ」 、 「メガナ」 、 「ラヴァーニャ」 } ;
コート << '学生: \n 」 ;
のために ( 文字列i : 学生 )
コート << 私 << 「」 ;
// 学生ベクトル内のすべての要素を並べ替えます。
選別 ( 始める ( 学生 ) 、 終わり ( 学生 ) ) ;
// unique() 関数を使用して、erase() 関数で重複を削除します
学生。 消す ( 個性的 ( 始める ( 学生 ) 、 終わり ( 学生 ) ) 、 終わり ( 学生 ) ) ;
コート << 」 \n \n ユニークな生徒たち: \n 」 ;
のために ( 自動 ITR = 始める ( 学生 ) ; ITR ! = いくつかの ( 学生 ) ; ++ ITR ) {
コート << * ITR << 「」 ;
}
}
出力:
これで、すべての要素がベクター内で一意になります。
ベクトルをセットに変換する
Set では要素の重複は許可されません。重複のあるセットにベクトルを挿入するように入力している場合、それらは無視されます。セットをベクトルに変換する前のシナリオで使用したものと同じ std::copy() 関数を使用します。
このシナリオでは:
- 最初のパラメーターは、begin() 関数を使用して指定されたソース反復子としてベクトルを受け取ります。
- 2 番目のパラメーターは、end() 関数を使用して指定されたソース反復子としてベクトルを受け取ります。
- セットの末尾を指すセットとイテレータをパラメータとして指定することで、セット内の特定の位置に要素を自動的に上書き/コピーするために使用される std::inserter() 関数を渡します。
10 個の整数を含むベクトルを作成し、要素をセットにコピーしましょう。
#include使用して 名前空間 標準 ;
主要 ( )
{
// セットを作成します - 10 個の値を持つマーク
ベクター < 整数 > マーク = { 12 、 3.4 、 56 、 78 、 65 、 78 、 90 、 90 、 78 、 3.4 } ;
コート << 'ベクター: \n 」 ;
のために ( 整数 私 : マーク )
コート << 私 << 「」 ;
// ベクターのサイズと同じサイズの Set -marks_set を作成します
セット < 整数 > マークセット ;
// Set - students から Vector -student_vc に要素を挿入します。
コピー ( 始める ( マーク ) 、終わり ( マーク ) 、インサーター ( マークセット、終了 ( マークセット ) ) ) ;
コート << 」 \n \n セット: \n 」 ;
のために ( 整数 私 : マークセット )
コート << 私 << 「」 ;
}
出力:
「marks」という名前の既存のベクトルには 10 個の値があります。これを「marks_set」セットにコピーすると、他の 4 つの要素が重複するため、6 つの要素のみが保持されます。

空の文字列を削除する
ベクトル内に存在する空の文字列は使用されません。ベクター内に存在する空の文字列を削除することをお勧めします。 C++ ベクトルから空の文字列を削除する方法を見てみましょう。
- 「for」ループを使用してベクトルを繰り返します。
- 各反復で、要素が空 ('') かどうか、または at() メンバー関数で '==' 演算子を使用していないかどうかを確認します。
- std::erase() 関数を使用して、前の条件を確認した後、空の文字列を削除します。
- ベクトルの終わりまでステップ 2 とステップ 3 を繰り返します。
10 個の文字列を含む「会社」ベクトルを作成しましょう。そのうち 5 つは空なので、前のアプローチを実装してそれらを削除します。
#include#include <ベクター>
使用して 名前空間 標準 ;
主要 ( ) {
ベクター < 弦 > 企業 { 「A社」 、 「」 、 「B社」 、
「」 、 「C社」 、 「」 、 「D社」 、 「」 、 「」 、 「」 } ;
// 会社を反復処理します
// そして、erase() を使用して空の要素を削除します
のために ( 整数 ITR = 1 ; ITR < 企業。 サイズ ( ) ; ++ ITR ) {
もし ( 企業。 で ( ITR ) == 「」 ) {
企業。 消す ( 企業。 始める ( ) + ITR ) ;
-- ITR ;
}
}
// ベクトルを表示する
のために ( 自動 & 私 : 企業 ) {
コート << 私 << 終わり ;
}
}
出力:
ここで、「companies」ベクトルは空ではない文字列を保持します。

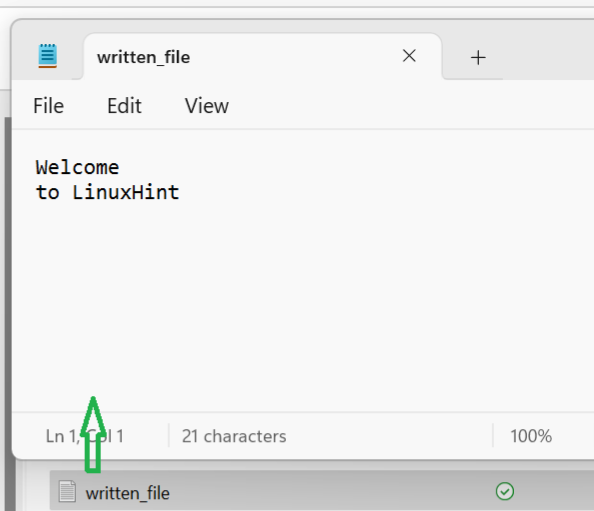
ベクトルをテキスト ファイルに書き込む
ベクトル内に存在するすべての要素を、ベクトル インデックスを使用してファイルに書き込む方法について説明します。 fストリーム 。
- ベクトルを初期化した後、push_back 関数を使用していくつかの要素をそれにプッシュします。
- 「fstream」ライブラリの open() 関数をモードを out にして使用します。
- 「for」ループ内のインデックスを使用してベクトル内に存在する各要素をトラバースし、提供されたファイルに各要素を書き込みます。
- 最後に、ファイルを閉じます。
C++ コードを実行して、前のアプローチを実装してみましょう。
#include <ベクター>#include <文字列>
#include
#include
を使用して 名前空間 標準 ;
主要 ( )
{
// ベクターを作成 - v_data
// そして 2 つの要素をそこにプッシュします。
ベクター < 弦 > v_data ;
v_データ。 プッシュバック ( 'いらっしゃいませ' ) ;
v_データ。 プッシュバック ( 「Linuxヒントへ」 ) ;
ストリームf ;
// ファイルを開きます
f. 開ける ( 「書かれたファイル.txt」 、ios_base :: 外 ) ;
// ベクトルの各要素を繰り返し、ファイルに 1 つずつ書き込みます。
のために ( 整数 私 = 0 ; 私 < v_データ。 サイズ ( ) ; 私 ++ )
{
f << v_data [ 私 ] << 終わり ;
}
// ファイルを閉じます
f. 近い ( ) ;
}
出力:
「v_data」ベクトルは 2 つの要素を保持し、ベクトル内に存在する要素を使用してプログラムが実行されるパスにファイルが作成されます。
テキスト ファイルからベクトルを作成する
ベクター内に存在する要素をテキスト ファイルに書き込む方法を学習しました。ここでは、テキスト ファイルに存在するコンテンツからベクターを作成しましょう。
- 「」を作成します イフストリーム」 テキスト ファイルから情報を読み取るために使用される変数で、ファイルからベクトルを作成します。
- ファイルの内容を保存する空のベクトルを作成し、ファイルの終わりを確認するためのフラグとして空の文字列変数を使用します。
- ファイルの次の行を最後に到達するまで読み取ります (基本的には「while」ループを使用します)。 Push_back() 関数を使用して次の行を読み取り、それをベクトルにプッシュします。
- ラインに存在するラインを個別に表示して、コンソール上のベクトルに存在する要素を確認します。
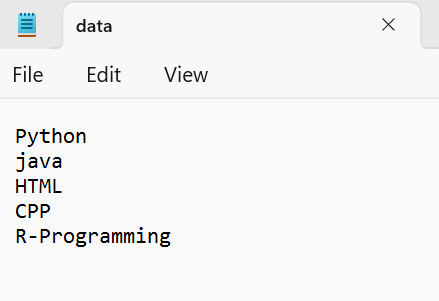
C++ コードを実行して、前のアプローチを実装してみましょう。以下の内容の「data.txt」ファイルを考えてみましょう。ここでは、ベクトルの名前を「v_data」とします。
を使用して 名前空間 標準 ;
主要 ( )
{
// テキスト ファイル - データを開きます
ifstream ファイル ( 「データ.txt」 ) ;
// ベクトル - 文字列型の v_data を作成します
ベクター < 弦 > v_data ;
Tバックでした ;
// data.txt から次の行を読み取ります
// 最後まで。
その間 ( ファイル >> だった ) {
// 次の行を読み取り、v_data にプッシュします
v_データ。 プッシュバック ( だった ) ;
}
// 行内に存在する行を個別に表示します。
コピー ( v_データ。 始める ( ) 、v_data。 終わり ( ) 、ostream_iterator < 弦 > ( コート 、 」 \n 」 ) ) ;
}
出力:
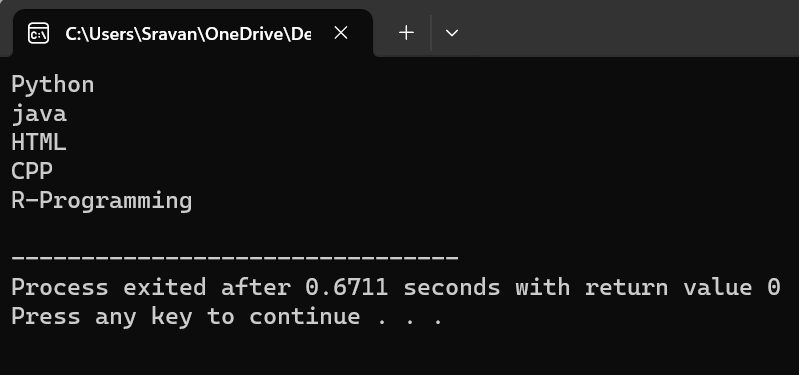
「v_data」には、ファイルから取得した 5 つの要素が保持されていることがわかります。
結論
この長い記事では、C++ プログラミング言語のベクトルに関連するリアルタイム アプリケーションで使用される可能性のあるすべての例を検討しました。各例は、構文、パラメーター、および出力例で説明されています。コードを明確に理解できるように、各コードにコメントが追加されています。