この記事では、割り当て方法について説明します。 違う 「」を介した記憶 pytorch_cuda_alloc_conf ' 方法。
PyTorch の「pytorch_cuda_alloc_conf」メソッドとは何ですか?
基本的には、「 pytorch_cuda_alloc_conf ” は、PyTorch フレームワーク内の環境変数です。この変数により、利用可能な処理リソースを効率的に管理できるようになります。これは、モデルが最小限の時間で実行され、結果が生成されることを意味します。正しく行われないと、「 違う ” 計算プラットフォームは” を表示します。 メモリ不足 」エラーが発生し、ランタイムに影響を与えます。大量のデータに対してトレーニングされるモデル、または大規模な「 バッチサイズ 」では、デフォルト設定では十分ではない可能性があるため、実行時エラーが発生する可能性があります。
” pytorch_cuda_alloc_conf ” 変数は以下を使用します” オプション ” リソース割り当てを処理します。
- ネイティブ : このオプションは、PyTorch ですでに使用可能な設定を使用して、進行中のモデルにメモリを割り当てます。
- max_split_size_mb : 指定されたサイズより大きいコード ブロックが分割されないようにします。これは「」を防ぐための強力なツールです。 断片化 ”。この記事のデモではこのオプションを使用します。
- ラウンドアップ_パワー2_ディビジョン : このオプションは、割り当てのサイズを最も近い「」に切り上げます。 2の累乗 ” メガバイト (MB) 単位の分割。
- Roundup_bypass_threshold_mb: 指定されたしきい値を超えるリクエスト リストの割り当てサイズを切り上げることができます。
- ガベージコレクションのしきい値 : GPU からの利用可能なメモリをリアルタイムで利用して、すべて回収プロトコルが開始されないようにすることでレイテンシーを防ぎます。
「pytorch_cuda_alloc_conf」メソッドを使用してメモリを割り当てる方法?
大きなデータセットを含むモデルでは、デフォルトで設定されているメモリ割り当てよりも大きい追加のメモリ割り当てが必要です。カスタム割り当ては、モデル要件と利用可能なハードウェア リソースを考慮して指定する必要があります。
「」を使用するには、以下の手順に従ってください。 pytorch_cuda_alloc_conf 」 Google Colab IDE のメソッドを使用して、複雑な機械学習モデルにより多くのメモリを割り当てます。
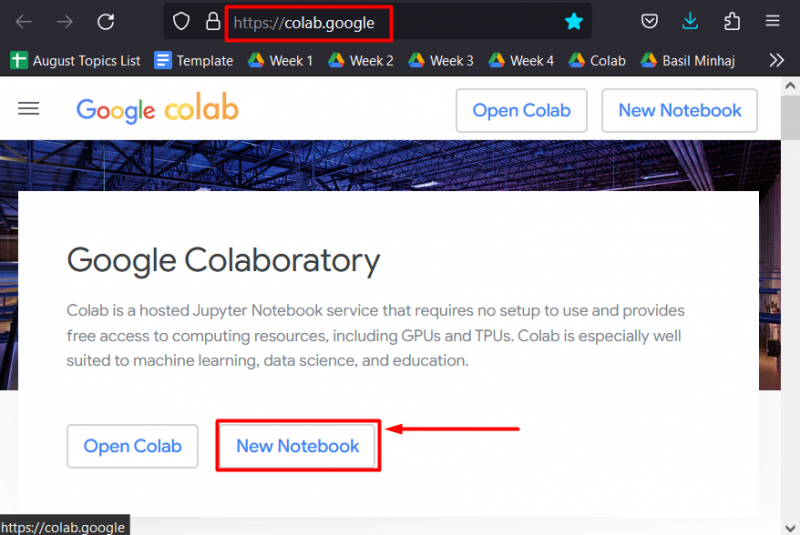
ステップ 1: Google Colab を開く
Googleで検索 協力的 ブラウザで「」を作成します 新しいノートブック ” 作業を開始するには:
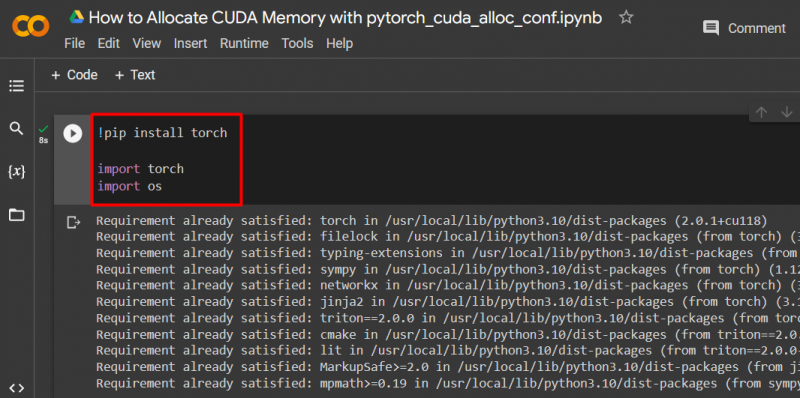
ステップ 2: カスタム PyTorch モデルをセットアップする
「」を使用して PyTorch モデルをセットアップします。 !ピップ ” インストール パッケージを使用して、” 松明 「図書館と」 輸入 「インポートするコマンド」 松明 ' そして ' あなた ” ライブラリをプロジェクトに追加します。
輸入トーチ
私たちを輸入してください
このプロジェクトには次のライブラリが必要です。
- 松明 – これは、PyTorch の基礎となる基本ライブラリです。
- あなた –「」 オペレーティング·システム ” ライブラリは、” などの環境変数に関連するタスクを処理するために使用されます。 pytorch_cuda_alloc_conf 」、システム ディレクトリとファイルのアクセス許可も同様です。
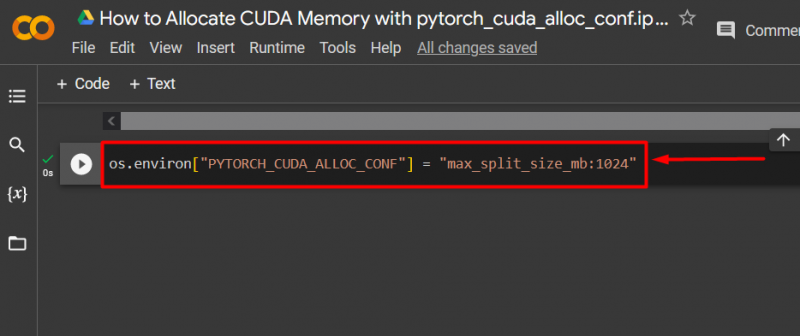
ステップ 3: CUDA メモリを割り当てる
使用 ' pytorch_cuda_alloc_conf ” を使用して最大分割サイズを指定する方法 max_split_size_mb ”:
ステップ 4: PyTorch プロジェクトを続行する
「」を指定した上で、 違う ” によるスペース割り当て max_split_size_mb 」オプションを選択した場合は、「 メモリ不足 ' エラー。
注記 : ここから Google Colab ノートブックにアクセスできます リンク 。
プロのヒント
前述したように、「 pytorch_cuda_alloc_conf 」メソッドは、上記で提供されたオプションのいずれかを使用できます。深層学習プロジェクトの特定の要件に応じてこれらを使用してください。
成功! 「」の使用方法を説明しました。 pytorch_cuda_alloc_conf ” を指定する方法 max_split_size_mb PyTorch プロジェクトの場合。
結論
使用 ' pytorch_cuda_alloc_conf 」メソッドを使用して、モデルの要件に従って利用可能なオプションのいずれかを使用して CUDA メモリを割り当てます。これらのオプションはそれぞれ、PyTorch プロジェクト内の特定の処理問題を軽減し、実行時間を改善し、操作をよりスムーズにすることを目的としています。この記事では、「」を使用するための構文を紹介しました。 max_split_size_mb 」オプションを使用して、分割の最大サイズを定義します。