PostgreSQL コード ブロックの構造を理解する
PostgreSQL のコード ブロックは次の構文に従います。
DO [ラベル]DECLARE [宣言]
BEGIN [ステートメント]
例外 [ハンドラー]
END [ラベル] ;
DECLARE セクションでは、コード ブロックで使用する変数を宣言します。 BEGIN セクションでは、SQL クエリなどのアクションを実行します。これはコード ブロック内の必須セクションです。最後に、例外はエラーの処理方法を定義するときに利用されます。 END キーワードはブロックの終わりを示します。ラベルは匿名ブロックを表します。
PostgreSQL 匿名コード ブロックの例
従うべき構造を理解したので、その実装のさまざまな例を挙げてみましょう。
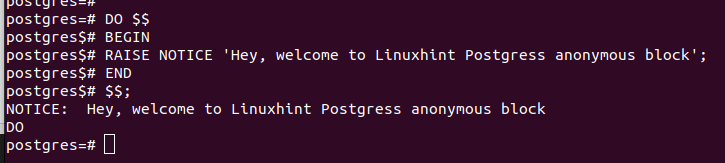
例 1: 単純なコード ブロック
この例では、変数を持たず、RAISE NOTICE ステートメントを使用してユーザーにメッセージを表示するだけのコード ブロックを示します。
PostgreSQL では、「Enter」キーを押すとコード ブロックが即座に実行されます。
例 2: 匿名コード ブロック
最初の例では、匿名コード ブロックを追加しませんでした。このような場合は、ブロック全体が匿名であることを前提としており、ブロックを参照する方法がないため、その中にセミブロックを含めることはできません。
次の例では、「main_block」を作成します。次のブロック構造に示すように、これを囲む必要があることに注意してください。
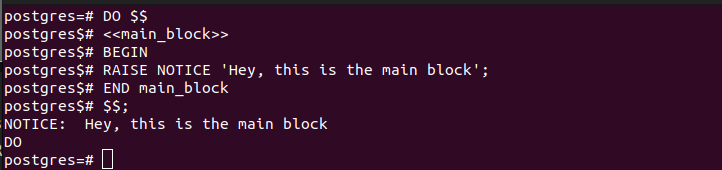
さらに、END キーワードを追加する場合は、終了する匿名コード ブロックの名前を指定する必要があります。
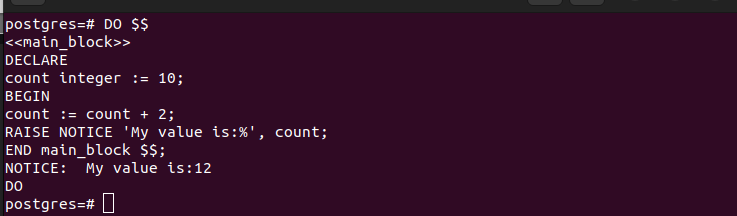
例 3: 変数を含む匿名コード ブロック
コード ブロック内で変数を操作すると便利です。変数は DECLARE セクションで宣言されます。これらは同じブロック内で初期化できますが、ほとんどの場合、BEGIN セクションで初期化する必要があります。
変数が初期化された匿名コード ブロックの名前を指定することで、変数を参照できます。こうすることで、親ブロックと子ブロックなど、多数のブロックがある場合に、エラーを引き起こす変数の混乱が発生しなくなります。
変数を宣言するときは、PostgreSQL の変数タイプを追加して、どのようなデータが期待され、その変数に格納されるかを理解する必要があります。この例では、整数変数があります。その値をインクリメントし、端末にメッセージを出力します。
例 4: PostgreSQL 匿名コード ブロックのテーブルの操作
データベースにテーブルがある場合、クエリを実行してテーブル内の値を参照できます。たとえば、この例では参考として次の表を使用します。
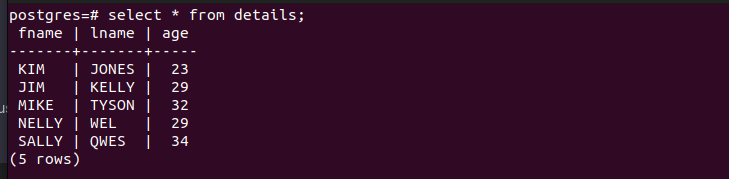
コード ブロック内に SELECT クエリを作成して、指定された条件に一致する特定のエントリの値を取得します。抽出された値は宣言された変数に保存され、取得された値を示すメッセージが出力されます。
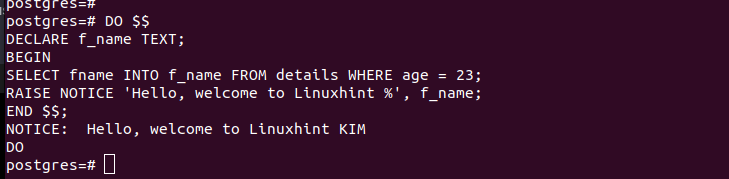
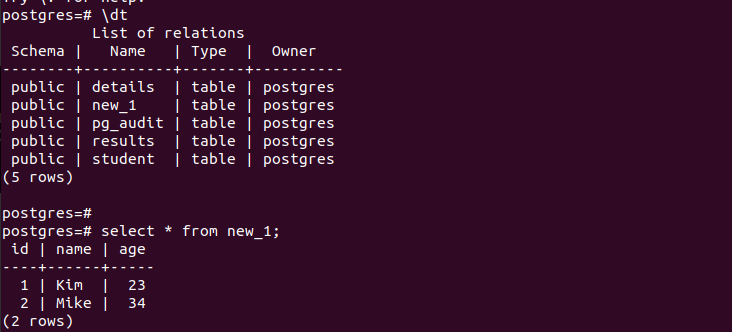
ただし、テーブル上では、テーブルを作成してそこに値を挿入するクエリを実行できます。次の PostgreSQL 匿名コード ブロックが「new_1」という名前のテーブルを作成し、挿入クエリを実行する様子を見てください。クエリは正常に実行されます。

データベース内の使用可能なテーブルを確認すると、テーブルが作成されたことがわかります。さらに、そのエントリをチェックすると、コード ブロックに挿入したものと同じものが得られます。理想的には、SQL が正しく、その値が期待どおりに取得される限り、どの SQL でも実行できます。
例 5: 匿名サブブロック コードの操作
場合によっては、外側のブロック、親ブロック、およびその内側の他のサブブロックが必要になる場合があります。コードによって、サブブロックがどのように実行されるかが決まります。ここでも、サブブロックと同じ変数名を共有する外側のブロックを持つことができます。変数を参照するときは、オーナー ブロックを指定する必要があります。
次の例では、外側のブロックとして「parent_block」があります。サブブロックを保持するために、別の DECLARE セクションと BEGIN セクションを追加します。さらに、END キーワードを 2 回使用して、内側と外側のブロックを閉じます。
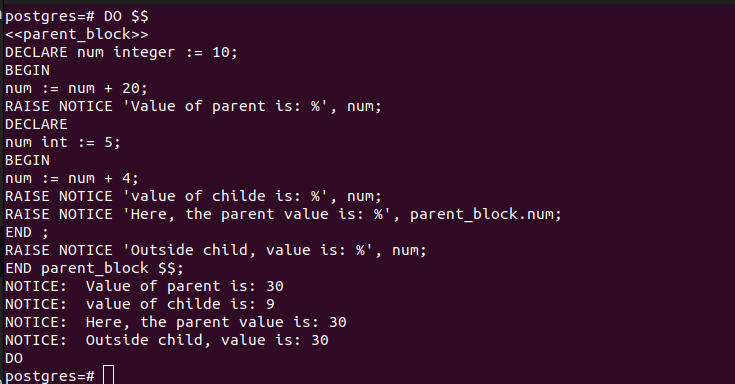
これが、PostgreSQL 匿名コード ブロックのサブブロックを操作する方法です。
結論
PostgreSQL ユーザーは、匿名コード ブロックとその使用方法について理解する必要があります。このガイドと例で提供される洞察は、理解を助ける簡単なガイドです。例を練習し続けると、すぐに PostgreSQL 匿名コード ブロックを快適に操作できるようになります。