Pandas の「Series.to_csv()」メソッドは、指定されたシリーズ オブジェクトをコンマ区切り値 (csv) 表記で出力します。この関数は単純に系列から値を取得し、インデックスと列の値を区切るためにコンマを追加してフォーマットを変更します。
この関数を使用するには、次の構文を使用する必要があります。

この記事では、Python プログラムでこの方法を使用する方法を学習するための 2 つの異なる手法を紹介します。
例 # 1: Series.to_csv() メソッドを使用して、DatetimeIndex を持つシリーズをカンマ区切りの値に変換する
シリーズを CSV 形式に変更するには、「Series.to_csv()」関数を使用します。この図は、DatetimeIndex を使用してシリーズを生成し、それをコンマ区切り値形式に変換します。
この方法を実行するには、Python プログラミングをサポートするツールが必要です。コードのコンパイルには「Spyder」ツールが選択されています。スクリプトを作成するために、まずシステムにインストールされたツールを起動しました。 python プログラムには、必要な結果を達成するためのメソッドを実行するためのライブラリが必要です。ここでロードしたライブラリは「パンダ」です。同じコード行で、このライブラリのエイリアスは「pd」として識別されます。したがって、関数にアクセスするには、プログラムのどこにでも「pandas」と記述する必要があります。代わりに「pd」と書きます。
コードを開始するための最初のステップは、Pandas シリーズを生成することです。 pandas からのシリーズ作成方法を採用するには、「pd」と記述する必要があります。 「pd.Series()」関数が呼び出され、指定された値でシリーズが構築されます。シリーズに提供した値は、「Istanbul」、「Izmir」、「Ankara」、「Ankara」、「Antalya」、「Konya」、および「Bursa」です。この値の配列に名前を付けたい場合は、「name」パラメーターを使用して行うことができます。ここでは、この値の配列に「Cities」という名前を付けました。これは、6 つの都市の名前を保持しているためです。このシリーズを保存するために、シリーズ オブジェクト「Turkey」が作成されました。
DatetimeIndex を作成するために、「pd.date_range()」メソッドを呼び出しました。この関数の括弧の間に、「start」、「freq」、「periods」、「tz」の 4 つの引数を渡しました。
「開始」引数は、日付と時刻を取り、そこから日付範囲の生成を開始します。ここでは、開始日時を「2022-03-02 02:30」と指定しています。 「freq」パラメーターは、日付範囲の頻度を分類しています。そのため、値「D」を指定しました。これで、毎日の頻度で日付範囲が作成されます。 「期間」引数は「6」に設定されています。これは、6 日間の日付範囲を生成することを意味します。最後のパラメーターは、指定された地域のタイムゾーンを指定する「tz」です。 「アジア/イスタンブール」のタイムゾーンを指定しています。
この日付範囲を保存するために、変数「Datetime」変数を作成しました。 DatetimeIndex を設定するために、「Series.index」プロパティを採用しました。シリーズ「Turkey」の名前は「.index」プロパティで提供され、「Datetime」変数に格納されている日時範囲に割り当てられます。したがって、「index」プロパティは「Datetime」変数から値を取得し、それらを「Turkey」シリーズのインデックス リストにします。最後に、出力シリーズを表示するために、「print()」メソッドを使用し、「Turkey」シリーズを入力として渡してその内容を表示しました。
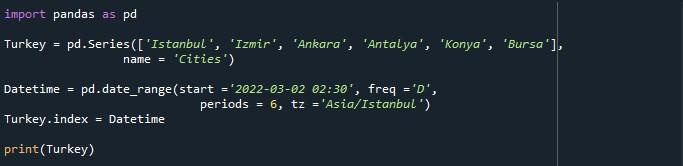
「ファイルの実行」オプションを押して、スクリプトを実行しました。その結果、DatetimeIndex が「2022-03-02 02:30:00+03:00」から始まり、「2022-03-07 02:30:00+03:00」で終わる一連の期間が作成されていることがわかります。 6日間。シリーズの下には、「Freq :D」、配列リストの名前「Cities」、dtype「object」も記載されています。
ここで、上のスナップショットで見たこのシリーズを CSV 形式に変換する方法を学びます。シリーズをカンマ区切りの値に変更するには、pandas モジュールが提供する「Series.to_csv()」というメソッドがあります。このメソッドは、提供されたシリーズの値を取得し、列の値の間にコンマを追加します。
「Series.to_csv()」関数が呼び出されます。変換したいシリーズの名前は、メソッドで「Turkey.to_csv()」として言及されます。カンマ区切りの値を保持するために、変数「Comma_Separated」を作成し、「print()」関数を呼び出してその内容を出力ウィンドウに配置しました。

これが csv 形式のシリーズです。スナップショットでは、インデックスと系列の値がカンマで区切られていることがわかります。

例 # 2: Series.to_csv() メソッドを使用して NaN 値を持つシリーズをコンマ区切り値に変換する
「Series.to_csv()」メソッドを実行する 2 番目の手法は、このメソッドを適用して、いくつかの null エントリを保持しているシリーズを CSV 形式に変換することです。
最初に必要なパッケージをインポートしました。 「pd」は pandas のエイリアスに、「np」は numpy のエイリアスにします。 pandas の「pd.Series()」メソッドを使用してシリーズを作成する際に、「np.NaN」を使用してシリーズにいくつかの null エントリを作成するため、numpy ツールキットがここにロードされます。
「pd.Series()」関数は、「Nile」、「Amazon」、「np.NaN」、「Ganges」、「Mississippi」、「np.NaN」、「Yangtze」、 「ドナウ」、「メコン」、「np.NaN」、「ヴォルガ」。シリーズには合計 21 個の値が定義されており、そのうち 3 つのエントリが「np.NaN」値を保持しています。これは、シリーズで 3 つの値が欠落していることを意味します。 「name」プロパティは、「Titles」に提供したこの値の配列の名前を指定しています。 「index」プロパティは、デフォルトのリストではなく、ユーザー定義のインデックス リストを設定するために使用されます。
ここでは、値が「10」、「11」、「12」、「13」、「14」、「16」、「17」、「18」、「19」、「20」のインデックスリストが必要です。そして21」。これで、シリーズのインデックス リストが「0」ではなく「10」から始まります。次に、このシリーズを保存して、後でプログラムで使用できるようにします。シリーズ オブジェクト「Rivers」を初期化し、「pd.Series()」メソッドの呼び出しから生成された出力シリーズを割り当てます。シリーズはpythonの「print()」関数を使って表示することで見ることができます。
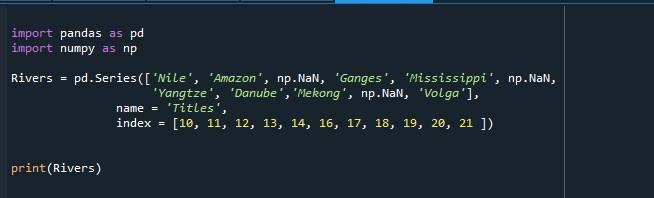
ターミナルでレンダリングされた出力は、インデックス リストが 10 から始まり 21 で終わるシリーズを出力しました。これは、シリーズが 21 の値を持つことを意味します。
シリーズは「Series.to_csv()」メソッドでCSV形式に変換されます。
シリーズ「Turkey」で「Series.to_csv()」メソッドを呼び出しました。したがって、このメソッドは「Turkey」シリーズから値を取得し、それらをコンマ区切り値形式に変換します。結果は「Converted_csv」変数に保存されます。そして最終的に、変換されたシリーズは「print()」関数を使用して印刷されます。

以下の結果のスナップショットでは、シリーズの値がコンマを使用してインデックス リストから区切られるように変更されていることがわかります。さらに、値が欠落している場合は、インデックス番号のみがカンマで出力されます。

結論
pandas シリーズを CSV 形式に変更することは、実用的なアプローチです。これは、パンダの「Series.to_csv()」関数を使用して実現できます。このガイドでは、この方法を採用するための 2 つの手法を実践しました。最初の図では、このメソッドを呼び出して、DatetimeIndex を持つシリーズをコンマ区切り値形式に変換しています。 2 番目のインスタンスは、「Series.to_csv()」関数を使用して、一部のエントリが欠落しているシリーズを CSV 形式に変更しました。どちらの手法も、Windows オペレーティング システムの「Spyder」ツールを使用して実際に実装されています。