Pandas Set_Option メソッド
今日は、「pd.set_option()」関数を使用して、Spyder ツールで表示するときに Pandas データフレームのすべての列を表示する方法を見ていきます。 「pd.set_option()」を使用するには、指定された構文に従います。

Python プログラムの実践的な実装の助けを借りて、概念の学習を始めましょう。
例: Pandas Set_Option メソッドを利用してすべての列を表示する
このデモは、Pandas の「set_option()」を利用して、DataFrame 内のすべての列を表示するためのガイドです。この Python メソッドを実装するためのすべてのステップの詳細を明らかにします。
Python スクリプトを実際に実装するための最初の要件は、プログラムを実行する最適なツールを見つけることです。イラストに使用したツールは「Spyder」ツールです。ツールを起動し、Python スクリプトの作業を開始しました。
コードから始めて、最初に、このプログラムで必要な前提条件のライブラリをインポートする必要があります。 Python ファイルにロードした最初のライブラリは Pandas ライブラリです。ここで使用する関数は Pandas によって提供されます。このライブラリに「pd」という別名を付けました。ロードした 2 番目のライブラリは NumPy ライブラリです。 NumPy (Numerical Python) は、Python プログラミングで開発された数値計算パッケージです。コードの Import NumPy セクションは、NumPy モジュールを現在の Python ファイルに統合するよう Python に指示します。スクリプトの「as np」部分は、NumPy に「np」の略語を割り当てるように Python に指示します。 NumPy の代わりに「np.function_name」を入力することで、NumPy メソッドを利用できます。
それでは、メインコードから始めます。私たちのプログラムにとって最も重要で基本的なニーズは、Pandas DataFrame です。そのため、含まれるすべての列を表示します。指定された値で DataFrame を作成するか、CSV ファイルをインポートする必要があるかは、完全にあなた次第です。このインスタンスで選択したのは、NaN 値を持つ DataFrame の作成です。 「pd.DataFrame()」メソッドを呼び出して、DataFrame を構築しました。ここでは、「index」と「columns」という 2 つのパラメーターを指定しました。 「index」引数は行を参照します。これは、DataFrame の行を設定することを意味します。
「index」パラメーターと NumPy 関数「np.arange()」に値カウント「6」を割り当てました。 DataFrame に対して 6 行を生成します。値を指定していないため、すべてのエントリに NaN 値が入力されます。名前が示すように、「列」引数は、DataFrame の列を設定するために使用されます。また、列の値カウントが「25」の「np.arange()」関数も割り当てられます。したがって、DataFrame の 25 列を構築します。
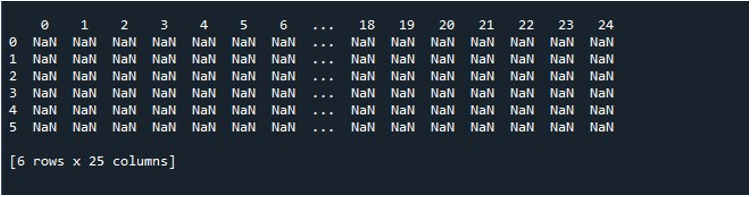
したがって、「pd.DataFrame()」関数を呼び出すと、25 列と 6 行が null 値で埋められた DataFrame が作成されます。この DataFrame を保持する必要があるため、そのコンテンツを格納する DataFrame オブジェクトを構築する必要があります。したがって、DataFrame オブジェクトを「random」に作成し、「pd.DataFrame()」メソッドから取得した結果を割り当てました。ここで、DataFrame が生成されるのを見たいと思うはずです。 Python は、「print()」関数である画面に出力を表示する方法を提供します。 DataFrame オブジェクト「random」をパラメーターとして渡すことで、このメソッドを呼び出しました。
このコード スニペットを実行すると、ターミナルに NaN 値が表示された DataFrame が取得されます。ここでは、最初の列の一部と、最後からの数列のみが表示されていることがわかります。中間の列はすべて切り捨てられます。デフォルトでは、巨大なデータセットを表示することでユーザーにフラストレーションを与えないように、一部の行と列が非表示になっています。
Pandas の「len()」関数を使用して、DataFrame の合計列数を確認することもできます。 「Spyder」ツールのコンソールに「len()」関数を記述します。 「.columns」プロパティを使用して、括弧内に DataFrame の名前を記述します。 DataFrame 内の列の合計の長さを返します。

25 である DataFrame の長さを返します。
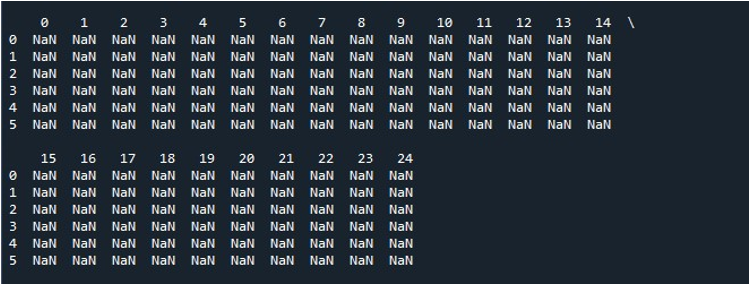
次の重要なタスクは、デフォルトのオプションを変更して出力を表示することです。端末で DataFrame 全体を表示したい場合があります。デフォルト値が原因で、多くのエントリが切り捨てられ、ユーザーを失望させます。ここでは、この問題を克服する方法を学びます。 Pandas は、デフォルトの表示設定を変更する「pd.set_option()」関数を提供します。コンソールに DataFrame を表示した直後に、「pd.set_option()」メソッドを呼び出します。 DataFrame のすべての列を表示するために使用する必要がある、この関数の括弧内のパラメーターを指定します。
ここでは、「display.max_columns」を使用して、DataFrame の最大列を表示しました。このパラメーターの値、つまり表示する最大列を定義することもできます。一方、「display.max_columns」を「None」に設定すると、DataFrame のすべての列が最大長で表示されます。最後に、「print()」関数を使用して、結果の DataFrame を表示し、すべての列を端末に表示しました。
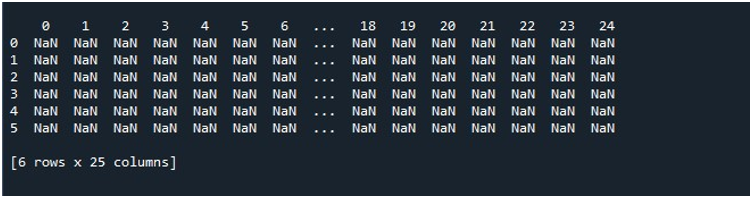
「Spyder」ツールの「ファイルの実行」オプションをクリックすると、公開されている DataFrame を表示できます。この DataFrame には 6 つの行があり、保持される列の数は 25 です。最大列長の「pd.set_option()」関数が有効になっているため、切り捨てられる列はありません。
表示の長さを最大に設定すると、その特定の Python ファイル内のすべての列を含む DataFrame が引き続き表示されるため、表示オプションをリセットすることもできます。このために、パンダの「pd.reset_option()」を利用します。この関数を呼び出し、この関数のパラメーターとして「display.max_columns」を提供します。

これにより、提供された DataFrame の初期表示設定が取得されます。
結論
ツールのデフォルト設定がユーザーのニーズと対照的である場合、巨大なデータセットを使用して端末で完全な出力を表示すると、問題が発生することがあります。この後退を解決するために、Pandas は「pd.set_option()」メソッドを提供します。この学習ガイドでは、この方法とそれを採用する必要性について紹介しました。実際にコンパイルおよび実行された Python のサンプル コードを使用して、このトピックのデモを行いました。 「Spyder」で行ったイラストの成果をレンダリングしました。デフォルト設定を変更するだけでなく、すべての設定を初期化することで、DataFrame のすべての列をコンソールに表示する方法を説明しました。モジュールの実装に十分な注意を払うことで、このようなトラブルに遭遇したときにいつでも使用できます。