Pandas は、今日データ サイエンティストが表形式のデータを分析するために使用する最も人気のあるツールの 1 つです。表形式のコンテンツを処理するために、より迅速で効果的な API を提供します。分析中にデータ フレームを表示するたびに、Pandas はさまざまな表示動作を自動的にデフォルト値に設定します。これらの表示動作には、表示する行と列の数、各データ フレームのフロートの精度、列のサイズなどが含まれます。要件によっては、これらのデフォルトを変更する必要がある場合があります。 Pandas には、デフォルトの動作を変更するためのさまざまなアプローチがあります。 pandas の「オプション」属性を活用することで、この動作を変更することができました。
パンダは最大行を表示します
定義済みのしきい値よりも多くの行と列を含む巨大なデータ フレームを印刷しようとすると、出力がトリミングされます。 DataFrame のすべての行を表示するには、このチュートリアルで Pandas の表示オプションを変更する方法を学習します。パンダはデフォルトで、表示する列と行の数に制限を課します。これはコンテンツを読むのに役立つかもしれませんが、表示する必要がある情報が表示されない場合、フラストレーションを引き起こすことがよくあります.ここでは、以下に示すメソッドとその構文を使用して、データフレームのすべての列を表示します。
to_string()

set_option()

option_context()

提供されたデータフレームに最大行を表示するための実用的な実装を使用して、これらすべてのメソッドの使用法を学習します。
例 # 1: Pandas の to_string() メソッドの利用
このデモでは、pandas の「to_string()」メソッドを使用して、端末のデータフレームに最大行を表示する方法を説明します。
サンプル プログラムのコンパイルと実行には、「Spyder」ツールを選択しました。このガイドでは、このツールを使用してすべての例を実行します。 「Spyder」ツールを起動して、Python スクリプトの作成を開始しました。コードから始めて、まず必要なライブラリを Python ファイルにロードして、その機能を使用できるようにする必要があります。ここで必要なモジュール ライブラリは「パンダ」です。そのため、それを python ファイルにインポートし、「pd」にエイリアスしました。
この記事の主な操作は、データフレームの最大行を表示することなので、最初にデータフレームが必要です。データフレームを生成するか、CSV ファイルをインポートするかは、あなた次第です。サンプルの CSV ファイルをインポートしました。 CSV ファイルを Python プログラムに読み込むために、pandas の「pd.read_csv()」関数を利用しました。この関数の括弧内に、表示を読み取る CSV ファイル「industry.csv」を指定しました。提供された CSV ファイルを読み取って生成された出力を格納する変数「df」を作成しました。次に、「print()」メソッドを呼び出してデータフレームを表示しました。
「ファイルの実行」オプションを押してこの python プログラムを実行すると、コンソールにデータフレームが表示されます。以下の結果には 43 行あることがわかりますが、表示されているのは 10 行のみです。これは、Pandas ライブラリのデフォルト値が 10 行のみであるためです。
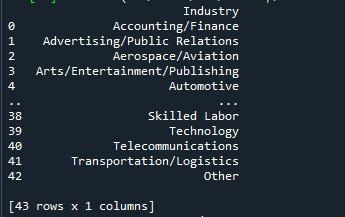
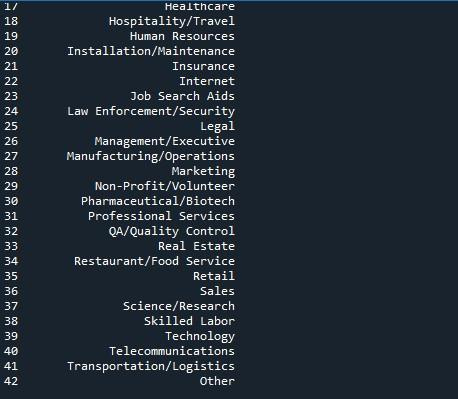
pandas メソッド「to_string」を使用して、ここにすべての行を表示します。データ フレームから最大行を表示する最も簡単な方法は、この手法を使用することです。ただし、完全なデータ フレームが 1 つの文字列に変換されるため、非常に大きなデータセット (数百万単位) にはお勧めできません。それにもかかわらず、これは数千の長さのデータセットに対して効果的に機能します。
上記の「to_string()」関数の構文に従いました。データフレームの名前で「to_string()」メソッドを呼び出すだけです。次に、このメソッドを「print()」関数に配置して、呼び出されたときに表示します。

出力スナップショットは、端末に表示されているすべての行を含むデータフレームを示しています。
例 # 2: Pandas set_option メソッドの利用
このガイドで実践する 2 番目の方法は、パンダの「set_option()」を使用して、提供されたデータフレームの最大行を表示します。
Python ファイルでは、上記の関数にアクセスするために pandas ライブラリをインポートしました。パンダの「pd.read_csv()」を使用して、提供された CSV ファイルを読み取りました。 「pd.read_CSV()」関数を、使用する CSV ファイルの名前をかっこで囲んで「Sampledata.csv」として呼び出しました。 CSV ファイルをインポートするときは、Python プログラムの現在の作業ディレクトリに注意してください。 CSV ファイルは同じディレクトリに配置する必要があります。そうしないと、「ファイルが見つかりません」というエラー メッセージが表示されます。 CSVファイルからデータフレームを格納する変数「サンプル」を作成しました。このデータフレームを表示するために「print()」メソッドを呼び出しました。
ここでは、10 行のみが表示される出力があります。示されている行の最大数は 99 です。最初の 5 行と最後の 5 行の間の他のすべての行は切り捨てられます。

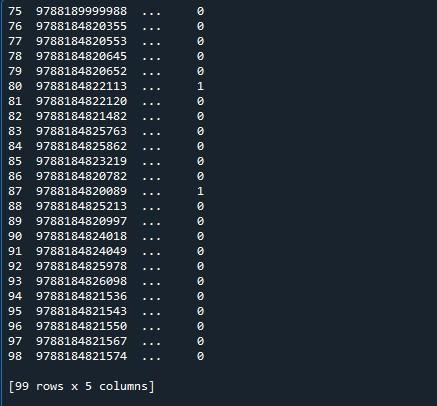
このデータフレームで最大 99 行を表示するには、pandas モジュールの「set_option()」関数を使用します。 Pandas には、動作と表示を変更できるオペレーティング システムが付属しています。このメソッドを使用すると、切り捨てられたデータ フレームではなく完全なデータ フレームを表示するようにディスプレイを設定できます。パンダは、データ フレームのすべての行を表示するための関数「set_option()」を提供します。
「pd.set_option()」を呼び出しました。この関数には、パラメータ「display.max_rows」があります。 「display.max_rows」は、データフレームを表示するときに表示される行の最大数を指定します。 「max_rows」の値は、デフォルトで 10 に設定されています。 「なし」が選択されている場合、データ フレーム内のすべての行を意味します。すべての行を表示したいので、「なし」に設定します。最後に、「print()」関数を使用して、データフレームを最大行で表示しました。

これにより、以下のスナップショットで提供される結果が得られます。
例 # 3: Pandas の option_context() メソッドの利用
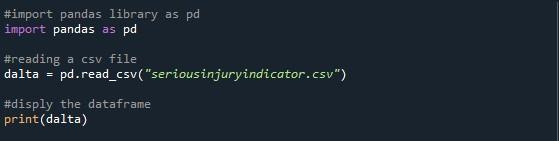
ここで説明する最後のメソッドは、すべてのデータフレームの行を表示するための「option_context()」です。このために、pandas パッケージを python ファイルにインポートし、コードの記述を開始しました。 「pd.read_csv()」関数を使用して、指定した CSV ファイルを読み取りました。指定した CSV ファイルからデータフレームを格納する変数「dalta」を作成しました。次に、「print()」メソッドを使用してデータフレームを単純に印刷しました。
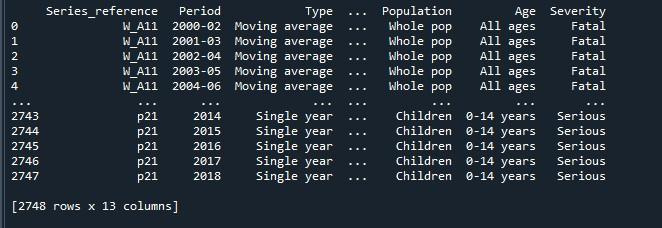
上記のコードを実行して得られた結果は、行が切り捨てられたデータフレームを示しています。
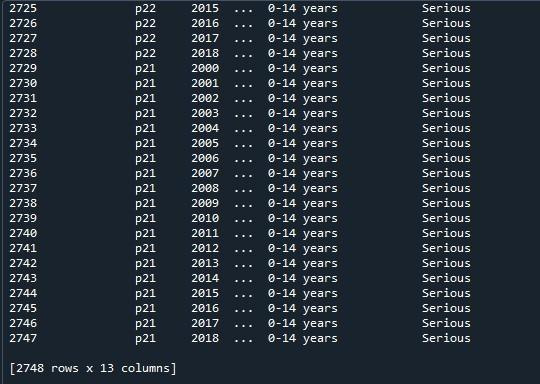
このデータフレームにパンダ「pd.option_context()」を適用します。この関数は「set_option()」と同じです。 2 つのアプローチの唯一の違いは、「set_option()」は設定を永続的に変更するのに対し、「option _context()」はスコープ内で設定を変更するだけであることです。このメソッドはまた、display.max 行をパラメーターとして取り、データ フレームのすべての行をレンダリングするために「None」に設定します。この関数を呼び出した後、「print()」メソッドを使用して表示しました。

ここでは、最大行数が 2747 の完全なデータフレームを表示できます。
結論
この記事では、パンダの表示オプションに焦点を当てています。端末で完全なデータフレームを表示する必要がある場合があります。パンダは、その目的のためにさまざまなオプションを提供してくれます。このガイドでは、これらの戦略のうち 3 つを使用しました。最初の例は、「to_string()」メソッドの使用に基づいていました。 2 番目の例では、「set_option()」を実装するように教えていますが、最後の図では「option_context()」メソッドを実行しています。これらのテクニックはすべて、必要な結果を達成するために pandas が提供する別の方法に慣れるために示されています。