{ 名前: 「アレクサ・ビル」 、 学年: 「あ」 、 コース: 「パイソン」 }、
{ 名前: 「ジェーン・マークス」 、 学年: 「B」 、 コース: 「ジャワ」 }、
{ 名前: 「ポール・ケン」 、 学年: 「C」 、 コース: 「C#」 }、
{ 名前: 「エミリー・ジオ」 、 学年: 「D」 、 コース: 「php」 }
]);
コレクションが存在し、その中にドキュメントが含まれている場合には、一意のインデックス フィールドを作成することもできます。このため、次のように挿入クエリが与えられる「候補」であるドキュメントを新しいコレクションに挿入します。
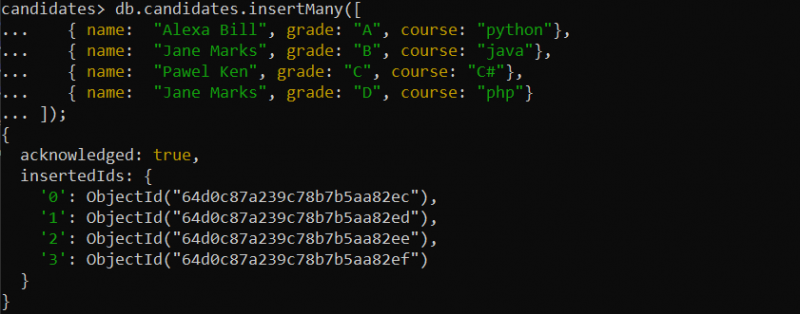
例 1: 単一フィールドの一意のインデックスを作成する
createIndex() メソッドを使用してインデックスを作成でき、ブール値「true」で unique オプションを指定することでフィールドを一意にすることができます。
db.candidates.createIndex( { グレード: 1 }, {一意: true })
ここでは、「候補」コレクションに対して createIndex() メソッドを開始して、特定のフィールドの一意のインデックスを作成します。次に、インデックス仕様として「グレード」フィールドに値「1」を指定します。ここでの値「1」は、コレクションの昇順インデックスを表します。次に、「unique」オプションを「true」値で指定して、フィールド「grade」の一意性を強制します。
出力は、「グレード」フィールドの一意のインデックスが「候補者」コレクションに対して作成されたことを表します。

例 2: 複数のフィールドの一意のインデックスを作成する
前の例では、一意のインデックスとして 1 つのフィールドのみが作成されます。ただし、createIndex() メソッドを使用して、2 つのフィールドを一意のインデックスとして同時に作成することもできます。
db.candidates.createIndex( { グレード: 1 、 コース: 1 }, {一意: true })
ここでは、同じ「候補」コレクションに対して createIndex() メソッドを呼び出します。 createIndex() メソッドに「grade」と「course」という 2 つのフィールドを指定し、最初の式として値「1」を指定します。次に、一意のオプションを「true」値に設定して、これら 2 つの一意のフィールドを作成します。
出力は、次の「候補者」コレクションの 2 つの一意のインデックス「grade_1」と「course_1」を表します。

例 3: フィールドの複合一意インデックスを作成する
ただし、同じコレクション内に一意の複合インデックスを同時に作成することもできます。これは、次のクエリを通じて実現します。
db.candidates.createIndex( { 名前: 1 、 学年: 1 、 コース: 1 }, {一意: true }再度 createIndex() メソッドを使用して、「候補」コレクションの複合一意インデックスを作成します。今回は、「グレード」、「名前」、「コース」の 3 つのフィールドを渡します。これらは、「候補者」コレクションの昇順インデックス フィールドとして機能します。次に、「unique」オプションを呼び出して、そのオプションに対して「true」が割り当てられるため、フィールドを一意にします。
出力には、3 つのフィールドすべてが指定されたコレクションの一意のインデックスになったことを示す結果が表示されます。

例 4: 重複するフィールド値の一意のインデックスを作成する
ここで、一意性制約を維持するためにエラーを引き起こす重複フィールド値に対して一意のインデックスを作成しようとします。
db.candidates.createIndex({名前: 1 },{一意:true})ここでは、類似した値を含むフィールドに一意のインデックス基準を適用します。 createIndex() メソッド内で、値「1」を指定して「name」フィールドを呼び出して一意のインデックスにし、値「true」を指定して一意のオプションを定義します。 2 つのドキュメントには同じ値の「name」フィールドがあるため、このフィールドを「candidates」コレクションの一意のインデックスにすることはできません。重複キー エラーは、クエリの実行時にトリガーされます。
予想どおり、名前フィールドには 2 つの異なるドキュメントの同じ値があるため、出力では結果が生成されます。

したがって、ドキュメント内の各「名前」フィールドに一意の値を与えることで「候補」コレクションを更新し、一意のインデックスとして「名前」フィールドを作成します。そのクエリを実行すると、通常、次のように、一意のインデックスとして「name」フィールドが作成されます。

例 5: 欠落しているフィールドの一意のインデックスを作成する
あるいは、コレクションのどのドキュメントにも存在しないフィールドに createIndex() メソッドを適用します。その結果、インデックスにはそのフィールドに対して null 値が格納され、フィールドの値に対する違反により操作は失敗します。
db.candidates.createIndex( { メール: 1 }, {一意: true })ここでは、createIndex() メソッドを使用し、「email」フィールドに値「1」を指定します。 「email」フィールドは「candidates」コレクションには存在しないため、一意のオプションを「true」に設定して、「candidates」コレクションの一意のインデックスにしようとします。
このクエリを実行すると、「候補者」コレクションに「電子メール」フィールドが欠落しているため、出力にエラーが表示されます。

例 6: スパース オプションを使用してフィールドの一意のインデックスを作成する
次に、sparse オプションを使用して一意のインデックスを作成することもできます。スパース インデックスの機能は、インデックス付きフィールドを持たないドキュメントを除外し、インデックス付きフィールドを持つドキュメントのみを含めることです。スパース オプションを設定するために次の構造を提供しました。
db.candidates.createIndex( { コース : 1 }、{ 名前: 「unique_sparse_course_index」 、一意: true、スパース: true })
ここでは、「course」フィールドの値が「1」に設定される createIndex() メソッドを提供します。その後、追加オプションを指定して、一意のインデックス フィールド「course」を設定します。オプションには、「unique_sparse_course_index」インデックスを設定する「name」が含まれます。次に、「unique」オプションが「true」値で指定され、「sparse」オプションも「true」に設定されます。
出力では、次に示すように、「course」フィールドに一意のスパース インデックスが作成されます。

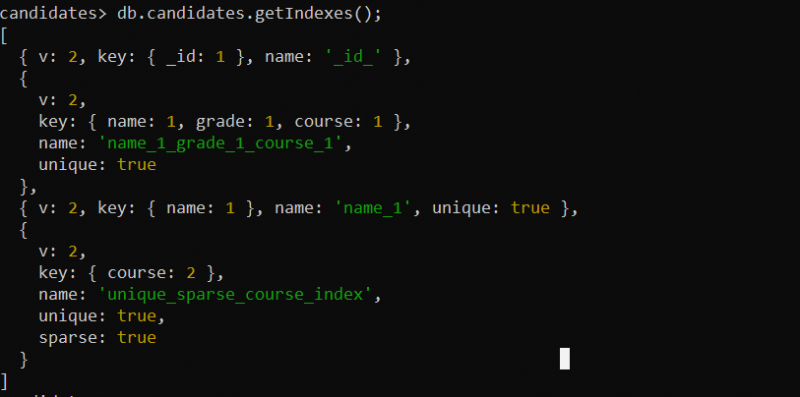
例 7: GetIndexes() メソッドを使用して、作成された一意のインデックスを表示する
前の例では、指定されたコレクションに対して一意のインデックスのみが作成されました。 「候補」コレクションの一意のインデックスに関する情報を表示および取得するには、次の getIndexes() メソッドを使用します。
db.candidates.getIndexes();ここでは、「候補」コレクションに対して getIndexes() 関数を呼び出します。 getIndexes() 関数は、前の例で作成した「候補」コレクションのすべてのインデックス フィールドを返します。
出力には、コレクション用に作成した一意のインデックス (一意のインデックス、複合インデックス、または一意のスパース インデックスのいずれか) が表示されます。
結論
コレクションの特定のフィールドに対して一意のインデックスを作成しようとしました。単一フィールドおよび複数フィールドに対して一意のインデックスを作成するさまざまな方法を検討しました。また、一意制約違反により操作が失敗する場合には、一意のインデックスを作成しようとしました。