概要
この投稿には次のセクションが含まれています。
LangChain で Async API エージェントを使用するには?
チャット モデルは、プロンプトの構造、その複雑さの理解、情報の抽出など、複数のタスクを同時に実行します。 LangChain で Async API エージェントを使用すると、ユーザーは一度に複数の質問に回答できる効率的なチャット モデルを構築できます。 LangChain で Async API エージェントを使用するプロセスを学習するには、このガイドに従ってください。
ステップ 1: フレームワークのインストール
まず、LangChain フレームワークをインストールして、Python パッケージ マネージャーから依存関係を取得します。
pip インストール ラングチェーン
その後、OpenAI モジュールをインストールして llm などの言語モデルを構築し、その環境を設定します。
pip インストール openai
ステップ 2: OpenAI 環境
モジュールのインストール後の次のステップは、 環境をセットアップする OpenAIのAPIキーを使用し、 サーバーAPI Google からデータを検索するには:
輸入 あなた
輸入 ゲットパス
あなた 。 約 [ 「OPENAI_API_KEY」 】 = ゲットパス 。 ゲットパス ( 「OpenAI API キー:」 )
あなた 。 約 [ 「SERPER_API_KEY」 】 = ゲットパス 。 ゲットパス ( 「サーバー API キー:」 )
ステップ 3: ライブラリのインポート
環境が設定されたので、LangChain の依存関係を使用して、asyncio やその他のライブラリなどの必要なライブラリをインポートするだけです。
から ラングチェーン。 エージェント 輸入 エージェントの初期化 、 ロードツール輸入 時間
輸入 非同期
から ラングチェーン。 エージェント 輸入 エージェントタイプ
から ラングチェーン。 llms 輸入 OpenAI
から ラングチェーン。 コールバック 。 標準出力 輸入 StdOutCallbackHandler
から ラングチェーン。 コールバック 。 トレーサー 輸入 ラングチェーントレーサー
から aiohttp 輸入 クライアントセッション
ステップ 4: 質問を設定する
インターネット (Google) で検索できる、さまざまなドメインまたはトピックに関連する複数のクエリを含む質問データセットを設定します。
質問 = [「2021年の全米オープン優勝者は誰だ?」 、
「オリビア・ワイルドのボーイフレンドの年齢は何歳ですか?」 、
「F1世界タイトルの勝者は誰だ?」 、
「2021年の全米オープン女子決勝で優勝したのは誰だ」 、
「ビヨンセの夫は誰で、彼の年齢は何歳ですか?」 、
】
方法 1: シリアル実行を使用する
すべての手順が完了したら、シリアル実行を使用して質問を実行するだけですべての回答が得られます。これは、一度に 1 つの質問が実行/表示され、これらの質問の実行にかかる完全な時間を返すことを意味します。
llm = OpenAI ( 温度 = 0 )ツール = ロードツール ( [ 「グーグルヘッダー」 、 「llm-数学」 】 、 llm = llm )
エージェント = エージェントの初期化 (
ツール 、 llm 、 エージェント = エージェントタイプ。 ZERO_SHOT_REACT_DESCRIPTION 、 冗長な = 真実
)
s = 時間 。 perf_counter ( )
#プロセス全体にかかる時間を取得するためのタイムカウンターの設定
のために q で 質問:
エージェント。 走る ( q )
経過 = 時間 。 perf_counter ( ) -s
#エージェントが回答を取得するために費やした合計時間を出力します
印刷する ( f 「シリアルは {elapsed:0.2f} 秒で実行されました。」 )
出力
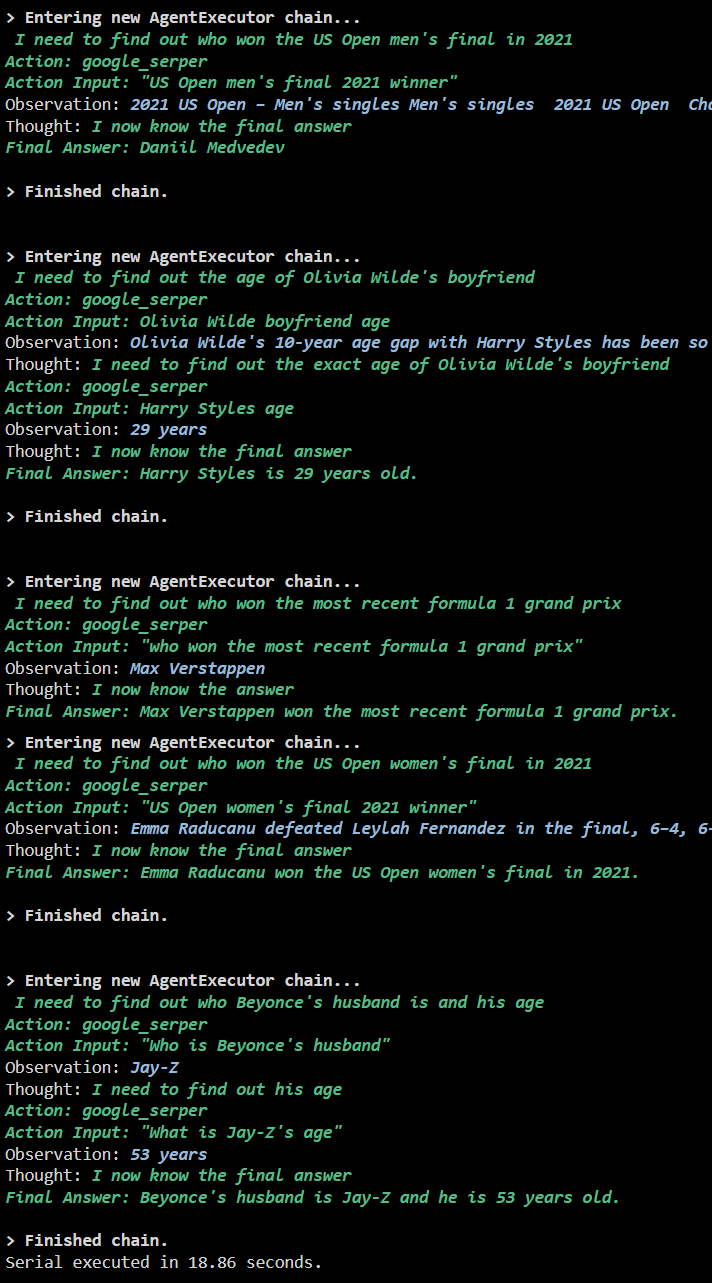
次のスクリーンショットは、各質問が個別のチェーンで回答され、最初のチェーンが終了すると 2 番目のチェーンがアクティブになることを示しています。シリアル実行では、すべての答えを個別に取得するのに時間がかかります。
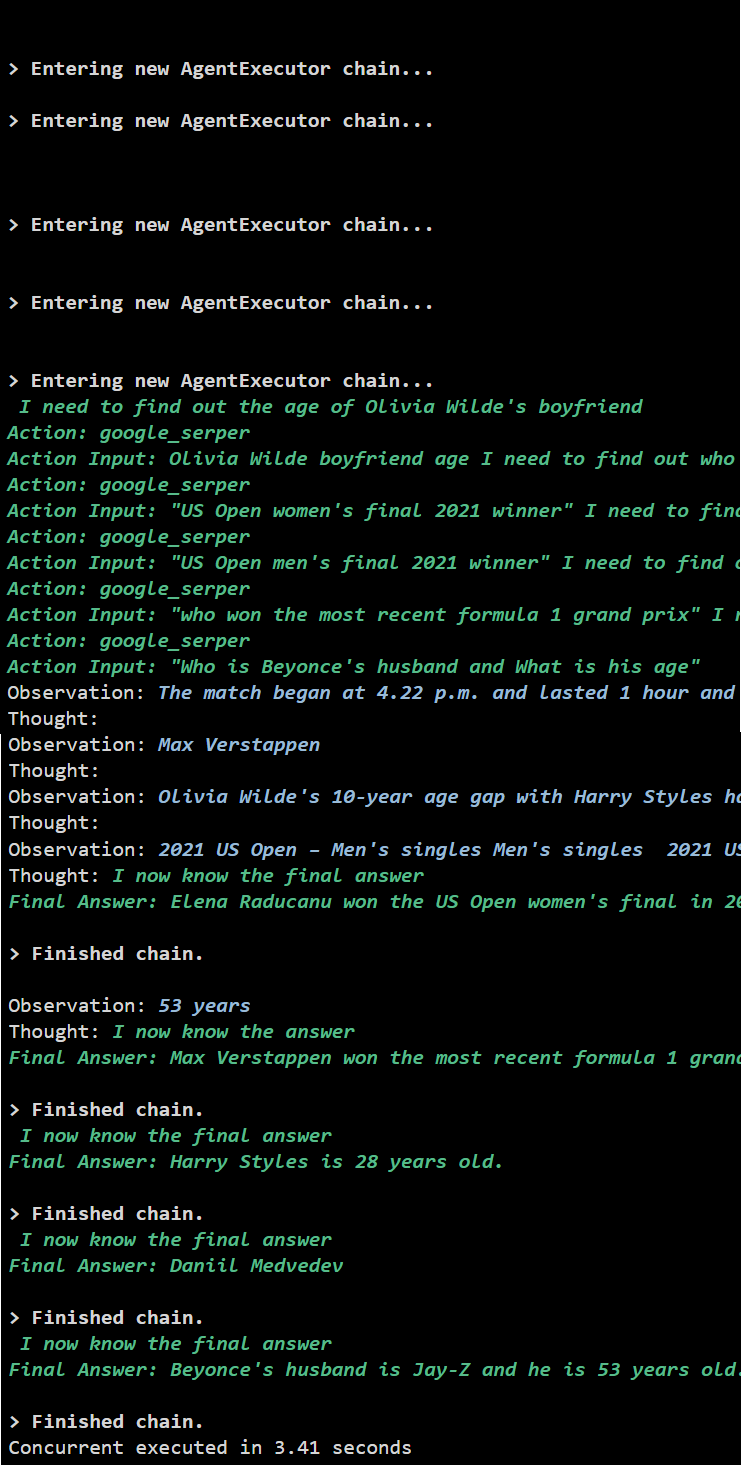
方法 2: 同時実行を使用する
同時実行方式では、すべての質問を取得し、その回答を同時に取得します。
llm = OpenAI ( 温度 = 0 )ツール = ロードツール ( [ 「グーグルヘッダー」 、 「llm-数学」 】 、 llm = llm )
#上記のツールを使用してエージェントを構成し、同時に回答を取得する
エージェント = エージェントの初期化 (
ツール 、 llm 、 エージェント = エージェントタイプ。 ZERO_SHOT_REACT_DESCRIPTION 、 冗長な = 真実
)
#プロセス全体にかかる時間を取得するためのタイムカウンターの設定
s = 時間 。 perf_counter ( )
タスク = [ エージェント。 病気 ( q ) のために q で 質問 】
非同期を待ちます。 集める ( *タスク )
経過 = 時間 。 perf_counter ( ) -s
#エージェントが回答を取得するために費やした合計時間を出力します
印刷する ( f 「同時実行は {elapsed:0.2f} 秒で実行されました」 )
出力
同時実行ではすべてのデータが同時に抽出され、シリアル実行よりもはるかに時間がかかりません。
LangChain での Async API エージェントの使用については以上です。
結論
LangChain で Async API エージェントを使用するには、モジュールをインストールして依存関係からライブラリをインポートし、asyncio ライブラリを取得するだけです。その後、OpenAI および Serper API キーを使用して、それぞれのアカウントにサインインして環境をセットアップします。さまざまなトピックに関連する一連の質問を構成し、チェーンを直列および同時に実行して、実行時間を取得します。このガイドでは、LangChain で Async API エージェントを使用するプロセスについて詳しく説明しました。