「コンマ区切り値 (CSV) は、最も用途が広く使いやすいデータ形式の 1 つです。これは、開発者やアプリケーションが 1 つのソースから別のソースにデータを転送および解析できるようにする軽量のデータ形式です。
CSV データは、各列がカンマで区切られた表形式でデータを格納し、新しいレコードは新しい行に割り当てられます。これにより、SQL データベース、Cassandra データなどのデータベースをエクスポートするのに非常に適しています。
したがって、CSV ファイルをデータベースにインポートする必要があるシナリオに遭遇することは驚くことではありません。
このチュートリアルの目的は、Kibana ダッシュボードを使用して CSV ファイルを Elasticsearch クラスターにインポートするための迅速かつ簡単な方法を示すことです。」
飛び込みましょう。
要件
飛び込む前に、次の要件があることを確認してください。
- ヘルス ステータスが緑色の Elasticsearch クラスター。
- Elasticsearch クラスターに接続された Kibana サーバー。
- クラスターのインデックスを管理するための十分なアクセス許可。
サンプル CSV ファイル
いつものように、最初の要件はソース CSV ファイルです。 CSV ファイル内のデータが適切な形式であり、エラーが含まれていないことを確認することをお勧めします。
説明のために、Amazon Prime の映画とテレビ番組を含む無料のデータセットを使用します。
ブラウザーを開き、以下のリソースに移動します。
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
手順に従って、データセットをローカル マシンにダウンロードします。ダウンロードしたアーカイブは、次のコマンドで抽出できます。
$ 解凍する あ~ / ダウンロード / アーカイブ.zip
CSV ファイルのインポート
ソース ファイルの準備ができたら、インポート方法について説明します。
まず、Kibana のホーム ダッシュボードに移動し、[ファイルのアップロード] オプションを選択します。
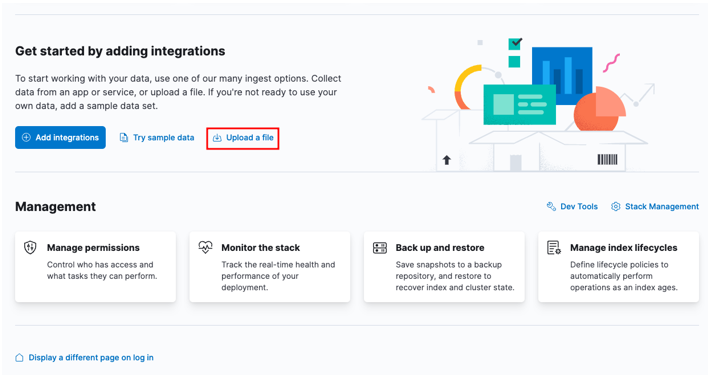
ランチャー ウィンドウで、インポートするターゲット CSV ファイルを見つけます。
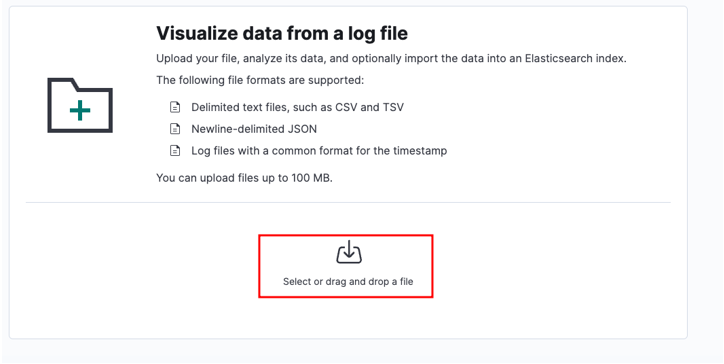
ソース ファイルを選択し、[アップロード] をクリックします。
Elasticsearch と Kibana がアップロードされたファイルを分析できるようにします。これにより、CSV ファイルが解析され、データ形式、フィールド、データ型などが決定されます。
注: クラスター構成とデータ サイズによっては、このプロセスに時間がかかる場合があります。タイムアウトを回避するために、マスター ノードが応答していることを確認します。
プロセスが完了すると、Elastic によって分析されたファイル コンテンツとファイル統計のサンプルを取得する必要があります。
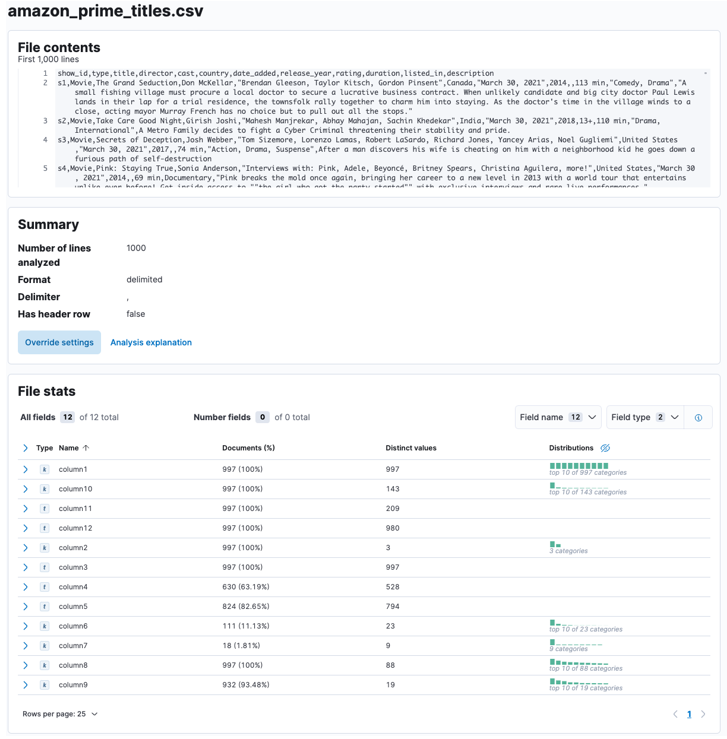
たとえば、区切り文字、ヘッダー行など、多数のパラメーターを調整できます。たとえば、上記の出力をカスタマイズして、CSV ファイルにヘッダー ファイルが含まれていることを Elastic に伝えることができます。
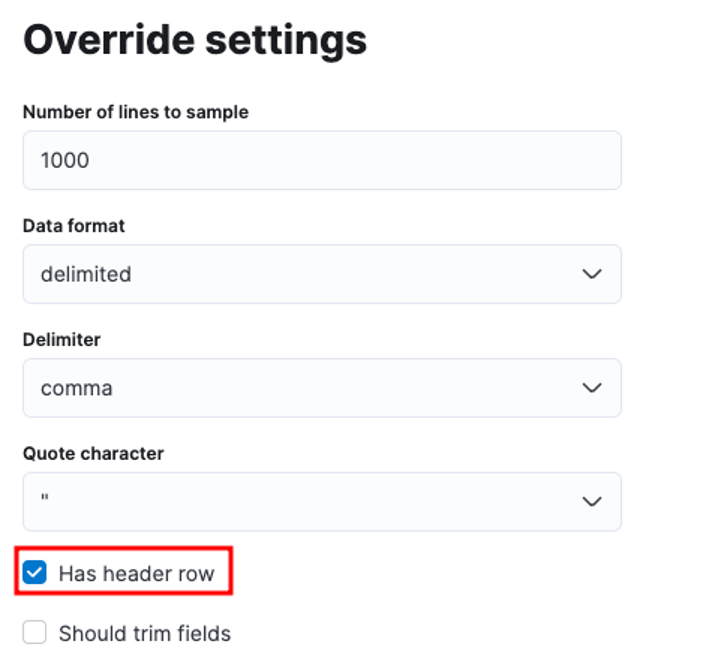
その後、[適用] をクリックして、データを再分析できます。これにより、フィールドを含め、データが正しい形式でフォーマットされます。
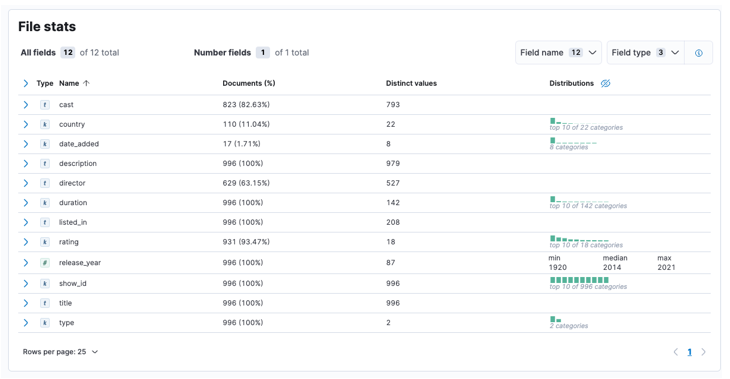
次に、[インポート] をクリックして、インポートされたダッシュボードに進みます。
ここでは、CSV データが格納されるインデックスを作成する必要があります。サポートされている任意の名前をインデックスに割り当てることができます。
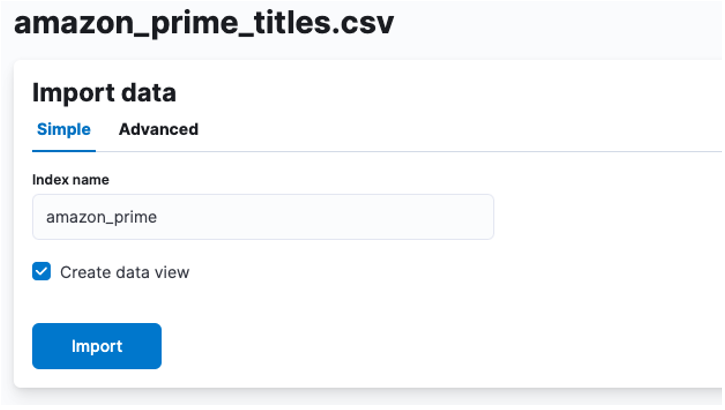
シャード、レプリカ、マッピングなどのインデックス プロパティをカスタマイズする場合は、高度なオプションを選択し、必要に応じて設定を調整します。
最後に、[インポート] をクリックして、Kibana がその「魔法」を実行するのを見てください。完了すると、Elasticsearch API または Kibana ダッシュボードを使用してインデックスにアクセスできます。
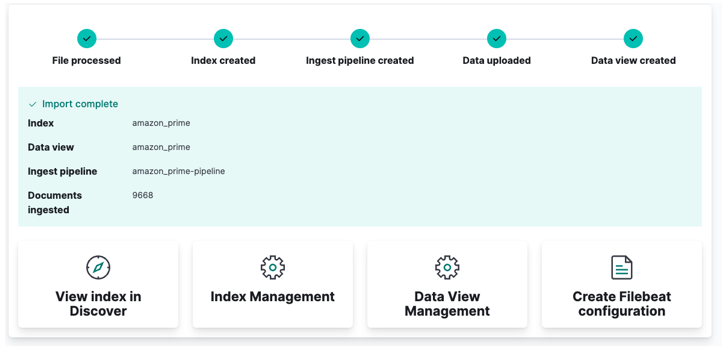
そして、あなたは完了です!!
結論
この投稿では、Kibana ダッシュボードを使用して CSV データセットを取得し、Elasticsearch クラスターにインポートするプロセスについて説明しました。
読んでくれてありがとう & 幸せなコーディング!!