Dalle-mini は、ユーザーの入力テキストから高品質の画像を生成できるディープラーニング モデルです。これは、OpenAI が 2021 年 1 月にリリースした DALL-E モデルに基づいています。DALL-E は「」の略です。 解きほぐされた言語と潜在表現 」は、テキストと画像を共通の潜在空間にエンコードし、デコードしていずれかのモダリティに戻すことができるトランスフォーマー ベースのニューラル ネットワークです。
この記事では以下の内容について解説します。
ダルミニとは何ですか?
彼女にミニをあげてください は、オープンソースの研究集団である EleutherAI によって作成された、DALL-E の小型で高速なバージョンです。 DALL-E の 120 億個のパラメータと比較して、Dalle-mini は 60 億個のパラメータのみを使用し、単一の GPU で実行できます。 Dalle-mini は、テキスト入力に異なるトークナイザーと語彙も使用するため、さまざまな言語やドメインとの互換性が高まります。

注記 : ユーザーは、次の手順に従って、Dalle-mini を使用して無料の画像を生成できます。 リンク 。
ダルミニの働きとは何ですか?
Dalle-mini の背後にある主なアイデアは、ニューラル ネットワークであるトランスの力です。テキストや画像などの連続データ内の長距離の依存関係や複雑なパターンを学習できます。
トランスフォーマーは、エンコーダーとデコーダーという 2 つの主要な部分で構成されます。最初の部分は入力 (テキストの説明) を受け取り、それを隠しベクトルに変更します。その後、デコーダはそれを受け取り、入力に関連する出力 (画像) を生成します。
ダルミニとダルイーの違いは何ですか?
Dalle-mini と DALL-E は、テキストと画像の両方に共有エンコーダ/デコーダ アーキテクチャを使用します。同じネットワークを使用して、両方のモダリティをエンコードおよびデコードできます。これにより、テキストと画像の間の意味論的な関係を捉える共通の潜在空間を学習できるようになります。その後、テキストから画像を作成したり、テキストから画像を作成したりするなど、クロスモーダル生成を実行できるようになります。
ダルミニはどのように機能しますか?
テキストの説明から画像を生成するために、Dalle-mini はまずバイトペア エンコード (BPE) アルゴリズムを使用してテキストをトークン化し、頻度と共起に基づいてテキストをサブワード単位に分割します。
Dalle-mini の内部動作の詳細を見てみましょう。
Dale-miniの内部動作
「」という言葉を考えてみましょう。 遊んでいる 「」は「」に分割される可能性があります プラ ' そして ' 英 ”。次に、トークンは 8192 個のトークンの語彙を使用して数値 ID にマッピングされます。 ID がエンコーダーに供給され、サイズ 256 x 64 の潜在表現が生成されます。
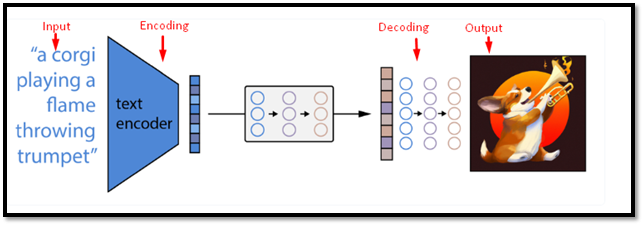
次に、デコーダは潜在表現を取得し、サイズ 256 x 256 ピクセルの画像を生成します。デコーダは自己回帰プロセスを使用します。これは、前のピクセルと潜在表現に基づいて、各ピクセルを 1 つずつ生成することを意味します。
Dalle-miniを使用してテキストの説明から画像を生成するにはどうすればよいですか?
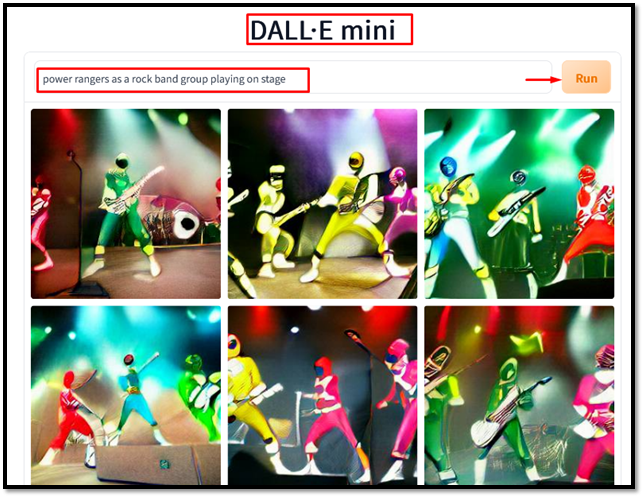
Dalle-mini を使用して画像からテキストの説明を生成するには、プロンプト ウィンドウにテキストを入力します。たとえば、「」と入力します。 ランダムな花の絵 プロンプトで「」を入力し、「 走る ' ボタン:
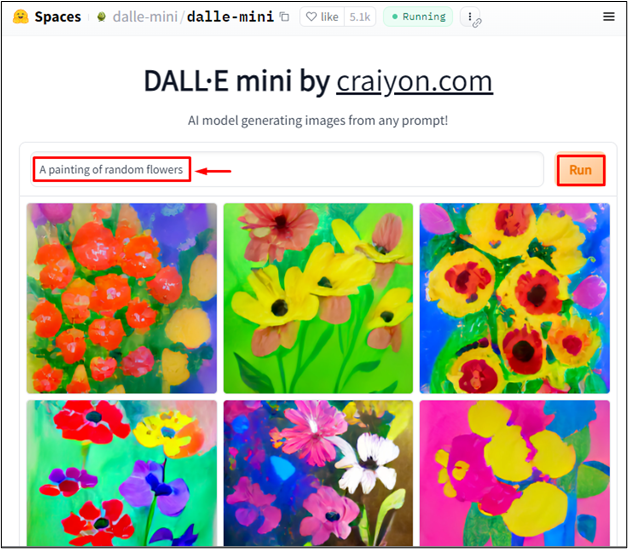
出力は、Dalle-mini が入力テキストに従って関連画像を生成したことを示しています。
結論
Dalle-mini は、クロスモーダル発電における変圧器の可能性を実証する注目すべきモデルです。自然言語の説明からリアルで多様な画像を作成したり、画像から一貫性のある関連性の高いテキストを作成したりできます。また、複数のオブジェクトや属性を 1 つの画像やテキストに組み合わせるなど、複雑な構成も処理できます。この記事では、Dalle-mini とその仕組みについて詳しく説明しました。