例 1:
「iostream」は、C++ の関数が宣言されている最初のヘッダー ファイルです。次に、ベクトルとベクトルを操作する関数を操作できるように、ここに含まれる「ベクトル」ヘッダー ファイルを追加します。次に、「std」はここで挿入する名前空間であるため、このコード内でこの「std」をすべての関数とともに個別に配置する必要はありません。そして、ここで「main()」が呼び出されます。この下に、「myNewData」という名前の「int」データ型のベクトルを作成し、そこにいくつかの整数値を挿入します。
この後、「for」ループを配置し、その中でこの「auto」キーワードを利用します。ここで、このイテレータは値のデータ型を検出します。 「myNewData」ベクトルの値を取得して「data」変数に保存し、この「data」を「cout」に追加するときにここにも表示します。
コード 1:
#include
#include <ベクター>
を使用して 名前空間 標準 ;
整数 主要 ( ) {
ベクター < 整数 > 私の新しいデータ { 十一 、 22 、 33 、 44 、 55 、 66 } ;
のために ( 自動 データ : 私の新しいデータ ) {
コート << データ << 終わり ;
}
}
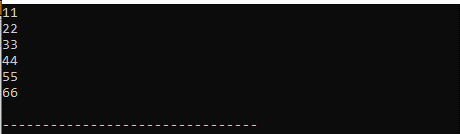
出力 :
ここに出力されているこのベクトルの値をすべて確認しました。 「for」ループを利用し、その中に「auto」キーワードを配置することで、これらの値を出力します。
例 2:
ここでは、すべての関数宣言が含まれる「bits/stdc++.h」を追加します。次に、ここに「std」名前空間を配置し、「main()」を呼び出します。この下では、「string」の「セット」を初期化し、「myString」という名前を付けます。次に、次の行で文字列データを挿入します。 「insert()」メソッドを使用して、このセットにいくつかの果物の名前を挿入します。
この下に「for」ループを使用し、その中に「auto」キーワードを配置します。この後、「auto」キーワードを使用して「my_it」という名前のイテレータを初期化し、「begin()」関数とともに「myString」をこれに割り当てます。
次に、「my_it」が「myString.end()」と等しくないという条件を設定し、「my_it++」を使用してイテレータの値をインクリメントします。この後、「*my_it」を「cout」に配置します。ここで「auto」キーワードを配置すると、果物の名前がアルファベット順に出力され、データ型が自動的に検出されます。
コード 2:
#includeを使用して 名前空間 標準 ;
整数 主要 ( )
{
セット < 弦 > myString ;
myString。 入れる ( { 「ぶどう」 、 'オレンジ' 、 'バナナ' 、 '梨' 、 'りんご' } ) ;
のために ( 自動 my_it = myString。 始める ( ) ; my_it ! = myString。 終わり ( ) ; my_it ++ )
コート << * my_it << 「」 ;
戻る 0 ;
}
出力:
ここでは、果物の名前がアルファベット順に表示されていることがわかります。前のコードで「for」と「auto」を使用したため、文字列セットに挿入したすべてのデータがここにレンダリングされます。

例 3:
「bits/stdc++.h」にはすでにすべての関数宣言が含まれているので、ここに追加します。 「std」名前空間を追加した後、この場所から「main()」を呼び出します。以下で確立した「int」の「セット」を「myIntegers」と呼びます。次に、次の行に整数データを追加します。 「insert()」メソッドを使用して、このリストにいくつかの整数を追加します。 「auto」キーワードが、この下で使用される「for」ループに挿入されます。
次に、「auto」キーワードを使用して「new_it」という名前のイテレータを初期化し、「myIntegers」と「begin()」関数をそれに割り当てます。次に、「my_it」が「myIntegers.end()」と等しくないという条件を設定し、「new_it++」を使用してイテレータの値を増やします。次に、この「cout」セクションに「*new_it」を挿入します。整数を昇順に出力します。 「auto」キーワードを挿入すると、データ型を自動的に検出します。
コード 3:
#includeを使用して 名前空間 標準 ;
整数 主要 ( )
{
セット < 整数 > myIntegers ;
myIntegers。 入れる ( { 4.5 、 31 、 87 、 14 、 97 、 21 、 55 } ) ;
のために ( 自動 新しい = myIntegers。 始める ( ) ; 新しい ! = myIntegers。 終わり ( ) ; 新しい ++ )
コート << * 新しい << 「」 ;
戻る 0 ;
}
出力 :
以下に示すように、ここでは整数が昇順で表示されます。前のコードで「for」と「auto」という用語を使用したため、整数セットに配置したすべてのデータがここでレンダリングされます。

例 4:
ここでベクターを扱う際には、「iostream」ヘッダー ファイルと「vector」ヘッダー ファイルが含まれています。次に、「std」名前空間が追加され、「main()」を呼び出します。次に、「int」データ型のベクトルを「myVectorV1」という名前で初期化し、このベクトルにいくつかの値を追加します。ここで、「for」ループを配置し、ここで「auto」を利用してデータ型を検出します。ベクトルの値でアクセスし、「cout」に「valueOfVector」を配置して出力します。
この後、その中に別の「for」と「auto」を配置し、「&& valueOfVector : myVectorV1」で初期化します。ここでは参照でアクセスし、「cout」に「valueOfVector」を入れてすべての値を出力します。ここでは、ループ内で「auto」キーワードを使用しているため、両方のループにデータ型を挿入する必要はありません。
コード 4:
#include#include <ベクター>
を使用して 名前空間 標準 ;
整数 主要 ( ) {
ベクター < 整数 > myVectorV1 = { 0 、 1 、 2 、 3 、 4 、 5 、 6 、 7 、 8 、 9 、 10 } ;
のために ( 自動 ベクトルの値 : myVectorV1 )
コート << ベクトルの値 << 「」 ;
コート << 終わり ;
のために ( 自動 && ベクトルの値 : myVectorV1 )
コート << ベクトルの値 << 「」 ;
コート << 終わり ;
戻る 0 ;
}
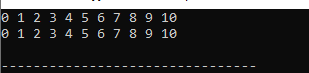
出力:
ベクターのすべてのデータが表示されます。最初の行に表示される数値は値によってアクセスした数値であり、2 行目に表示される数値はコード内の参照によってアクセスした数値です。
例 5:
このコードで「main()」メソッドを呼び出した後、「int」データ型でサイズ「7」の「myFirstArray」と「double」データ型でサイズ「7」の「mySecondArray」の 2 つの配列を初期化します。データ・タイプ。両方の配列に値を挿入します。最初の配列に「整数」値を挿入します。 2 番目の配列には、「double」値を追加します。この後、「for」を利用して、このループに「auto」を挿入します。
ここでは、「myFirstArray」に対して「range Base for」ループを使用します。次に、「myVar」を「cout」に配置します。この下に再度ループを配置し、「range Base for」ループを利用します。このループは「mySecondArray」用であり、その配列の値も出力します。
コード5:
#includeを使用して 名前空間 標準 ;
整数 主要 ( )
{
整数 myFirstArray [ 7 】 = { 15 、 25 、 35 、 4.5 、 55 、 65 、 75 } ;
ダブル mySecondArray [ 7 】 = { 2.64 、 6.45 、 8.5 、 2.5 、 4.5 、 6.7 、 8.9 } ;
のために ( 定数 自動 & myVar : myFirstArray )
{
コート << myVar << 「」 ;
}
コート << 終わり ;
のために ( 定数 自動 & myVar : mySecondArray )
{
コート << myVar << 「」 ;
}
戻る 0 ;
}
出力:
両方のベクトルのすべてのデータがこの結果に表示されます。

結論
この記事では「自動車向け」というコンセプトを徹底的に研究しています。 「auto」はデータ型を言及せずに検出すると説明しました。この記事では複数の例を検討し、コードの説明もここで提供しました。この記事では、この「自動車用」コンセプトの仕組みについて詳しく説明しました。