前提条件
このチュートリアルの例を実践する前に、クライアントとともにデータベース サーバーをインストールする必要があります。このチュートリアルでは、MariaDB データベース サーバーとクライアントを使用します。
1. 次のコマンドを実行してシステムを更新します。
$ sudo apt-get アップデート
2. 次のコマンドを実行して、MariaDB サーバーとクライアントをインストールします。
$ sudo apt-get install mariadb-server mariadb-client
3. 次のコマンドを実行して、MariaDB データベースのセキュリティ スクリプトをインストールします。
$ sudo mysql_secure_installation
4. 次のコマンドを実行して MariaDB サーバーを再起動します。
$ sudo /etc/init.d/mariadb 再起動
6. 次のコマンドを実行して、MariaDB サーバーにログインします。
$ sudo mariadb -u root -pSQLクエリ例のリスト
- データベースを作成する
- テーブルを作成する
- テーブル名の変更
- テーブルに新しい列を追加する
- テーブルから列を削除する
- テーブルに単一行を挿入する
- テーブルに複数の行を挿入する
- テーブルから特定のフィールドをすべて読み取る
- テーブルからデータをフィルタリングした後にテーブルを読み取る
- ブール論理に基づいてデータをフィルタリングした後、テーブルを読み取ります
- データの範囲に基づいて行をフィルタリングした後、テーブルを読み取ります
- 特定の列に基づいてテーブルを並べ替えた後、テーブルを読み取ります。
- 列の代替名を設定してテーブルを読み取る
- テーブル内の行の合計数を数える
- 複数のテーブルからデータを読み取る
- 特定のフィールドをグループ化して表を読む
- 重複する値を省略してテーブルを読み取る
- 行数を制限してテーブルを読み取る
- 部分一致に基づいてテーブルを読み取る
- テーブルの特定のフィールドの合計を数える
- 特定のフィールドの最大値と最小値を見つける
- フィールドの特定部分のデータを読み取る
- 連結後のテーブルデータの読み取り
- 数学的計算後にテーブルデータを読み取る
- テーブルのビューを作成する
- 特定の条件に基づいてテーブルを更新する
- 特定の条件に基づいてテーブル データを削除する
- テーブルからすべてのレコードを削除
- テーブルをドロップする
- データベースを削除する
データベースを作成する
図書館管理システム用の単純なデータベースを設計する必要があるとします。このタスクを実行するには、複数のリレーショナル テーブルを含むデータベースをサーバー内に作成する必要があります。データベース サーバーにログインした後、次のコマンドを実行して、MariaDB データベース サーバーに「library」という名前のデータベースを作成します。
作成 データベース 図書館;出力は、ライブラリ データベースがサーバー上に作成されたことを示しています。
 次のコマンドを実行して、サーバーからデータベースを選択し、さまざまな種類のデータベース操作を実行します。
次のコマンドを実行して、サーバーからデータベースを選択し、さまざまな種類のデータベース操作を実行します。
出力は、ライブラリ データベースが選択されていることを示しています。

テーブルを作成する
次のステップでは、データベースにデータを保存するために必要なテーブルを作成します。チュートリアルのこの部分では 3 つのテーブルが作成されます。これらは、ブック、メンバー、およびborrow_infoテーブルです。
- Books テーブルには、書籍関連のデータがすべて保存されます。
- members テーブルには、図書館から本を借りるメンバーに関するすべての情報が保存されます。
- Bring_info テーブルには、どのメンバーがどの本を借りたかに関する情報が保存されます。
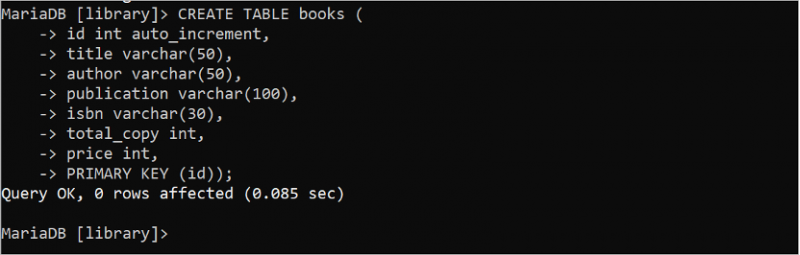
1. 本 テーブル
次の SQL ステートメントを実行して、「library」データベースに 7 つのフィールドと 1 つの主キーを含む「books」という名前のテーブルを作成します。ここで、「id」フィールドは主キーであり、データ型は int です。 auto_increment 属性は「id」フィールドに使用されます。したがって、このフィールドの値は、新しい行が挿入されると自動的に増加します。 varchar データ型は、可変長の文字列データを格納するために使用されます。タイトル、著者、出版物、isbn フィールドには文字列データが保存されます。 total_copy フィールドとprice フィールドのデータ型は int です。したがって、これらのフィールドには数値データが保存されます。
作成 テーブル 本 (ID INT 自動増加 、
タイトル VARCHAR ( 50 ) 、
著者 VARCHAR ( 50 ) 、
出版物 VARCHAR ( 100 ) 、
ISBN VARCHAR ( 30 ) 、
合計_コピー INT 、
価格 INT 、
主要な 鍵 ( ID ) ) ;
出力は、「books」テーブルが正常に作成されたことを示しています。
2. メンバー テーブル
次の SQL ステートメントを実行して、「ライブラリ」データベースに 5 つのフィールドと 1 つの主キーを含む「members」という名前のテーブルを作成します。 「id」フィールドには「books」テーブルと同様に auto_increment 属性があります。他のフィールドのデータ型は varchar です。したがって、これらのフィールドには文字列データが保存されます。
作成 テーブル メンバー (ID INT 自動増加 、
名前 VARCHAR ( 50 ) 、
住所 VARCHAR ( 200 ) 、
連絡先番号 VARCHAR ( 15 ) 、
Eメール VARCHAR ( 50 ) 、
主要な 鍵 ( ID ) ) ;
出力は、「members」テーブルが正常に作成されたことを示しています。

3. 情報を借りる テーブル
次の SQL ステートメントを実行して、「library」データベースに 6 つのフィールドを含む「borrow_info」という名前のテーブルを作成します。ここでは、「id」フィールドが主キーですが、このフィールドには auto_increment 属性が使用されていません。したがって、新しいレコードがテーブルに挿入されるときに、一意の値がこのフィールドに手動で挿入されます。 book_id フィールドと member_id フィールドは、このテーブルの外部キーです。これらは、「books」テーブルと「member」テーブルの主キーです。 Bring_date フィールドと return_date フィールドのデータ型は date です。したがって、これら 2 つのフィールドには日付値が「YYYY-MM-DD」形式で保存されます。
作成 テーブル 借用情報 (ID INT 、
借用日 日にち 、
book_id INT 、
メンバーID INT 、
戻り日 日にち 、
スターテス VARCHAR ( 10 ) 、
主要な 鍵 ( ID ) 、
外国 鍵 ( book_id ) 参考文献 本 ( ID ) 、
外国 鍵 ( メンバーID ) 参考文献 メンバー ( ID ) ) ;
出力は、「borrow_info」テーブルが正常に作成されたことを示しています。

テーブル名の変更
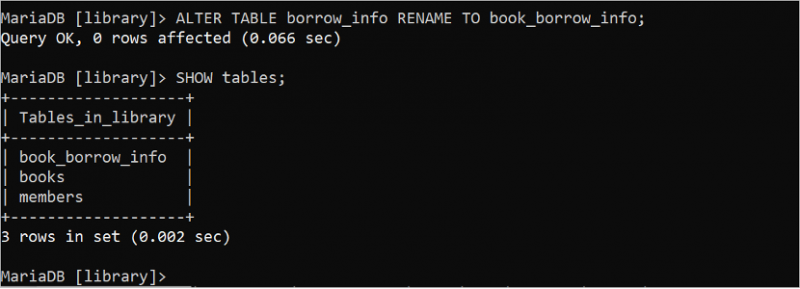
ALTER TABLE ステートメントは、SQL ステートメントで複数の目的に使用できます。次の ALTER TABLE ステートメントを実行して、「borrow_info」テーブルの名前を「book_borrow_info」に変更します。次に、SHOW tables ステートメントを使用して、テーブルの名前が変更されているかどうかを確認できます。
変更 テーブル 借用情報 名前を変更する に 本を借りる情報;見せる テーブル ;
出力には、テーブル名が正常に変更され、borrow_info テーブルの名前が book_borrow_info に変更されたことが示されています。
テーブルに新しい列を追加する
ALTER TABLE ステートメントを使用すると、テーブルの作成後に 1 つ以上の列を追加または削除できます。次の ALTER TABLE ステートメントは、「status」という名前の新しいフィールドをテーブル メンバーに追加します。 DESCRIBE ステートメントは、テーブル構造が変更されたかどうかを示すために使用されます。
変更 テーブル メンバー 追加 スターテス VARCHAR ( 10 ) ;説明 メンバー。
出力は、「status」という新しい列が「members」テーブルに追加され、テーブルのデータ型が varchar であることを示しています。

テーブルから列を削除する
次の ALTER TABLE ステートメントは、「members」テーブルから「status」という名前のフィールドを削除します。 DESCRIBE ステートメントは、テーブル構造が変更されたかどうかを示すために使用されます。
変更 テーブル メンバー 落とす 桁 スターテス ;説明 メンバー。
出力は、「status」列が「members」テーブルから削除されたことを示しています。

テーブルに単一行を挿入する
INSERT INTO ステートメントは、テーブルに 1 つ以上の行を挿入するために使用されます。次の SQL ステートメントを実行して、「books」テーブルに 1 行を挿入します。ここで、「id」フィールドは、自動インクリメント属性に対して新しいレコードが挿入されるときにレコードに自動的に挿入されるため、このクエリから省略されています。このフィールドを INSERT ステートメントで使用する場合、値は NULL である必要があります。
入れる の中へ 本 ( タイトル 、 著者 、 出版物 、 ISBN 、 合計_コピー 、 価格 )価値観 ( 「10分でわかるSQL」 、 「ベン・フォルタ」 、 「サムズ・パブリッシング」 、 「784534235」 、 5 、 39 ) ;
出力は、レコードが「books」テーブルに正常に追加されたことを示しています。

データは、各フィールド値が個別に割り当てられる SET 句を使用してテーブルに挿入できます。次の SQL ステートメントを実行し、INSERT INTO 句と SET 句を使用して「members」テーブルに単一行を挿入します。同じ理由で、前の例と同様に、このクエリでも「id」フィールドが省略されています。
入れる の中へ メンバー設定 名前 = 「ジョン・シーナ」 、 住所 = '34、ダンモンディ 9/A、ダッカ' 、 連絡先番号 = 「+14844731336」 、 Eメール = 「john@gmail.com」 ;
出力は、レコードが members テーブルに正常に追加されたことを示しています。

次の SQL ステートメントを実行して、「book_borrow_info」テーブルに 1 行を挿入します。
入れる の中へ book_borrow_info ( ID 、 借用日 、 book_id 、 メンバーID 、 戻り日 、 スターテス )価値観 ( 1 、 「2023-03-12」 、 1 、 1 、 「2023-03-19」 、 '借りた' ) ;
出力は、レコードが「book_borrow_info」テーブルに追加されたことを示しています。

テーブルに複数の行を挿入する
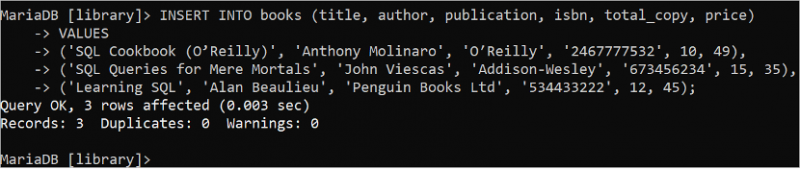
場合によっては、単一の INSERT INTO ステートメントを使用して、一度に多くのレコードを追加する必要があります。次の SQL ステートメントを実行し、単一の INSERT INTO ステートメントを使用して 3 つのレコードを「books」テーブルに挿入します。この場合、VALUES 句は 1 回だけ使用され、各レコードのデータはカンマで区切られます。
入れる の中へ 本 ( タイトル 、 著者 、 出版物 、 ISBN 、 合計_コピー 、 価格 )価値観
( 「SQL クックブック (オライリー)」 、 「アンソニー・モリナロ」 、 「オライリー」 、 「2467777532」 、 10 、 49 ) 、
( 「単なる人間のための SQL クエリ」 、 「ジョン・ヴィエスカス」 、 「アディソン・ウェスリー」 、 「673456234」 、 15 、 35 ) 、
( 「SQLを学ぶ」 、 「アラン・ボーリュー」 、 「ペンギンブックス株式会社」 、 「534433222」 、 12 、 4.5 ) ;
出力は、3 つのレコードが「books」テーブルに追加されたことを示しています。
テーブルから特定のフィールドをすべて読み取る
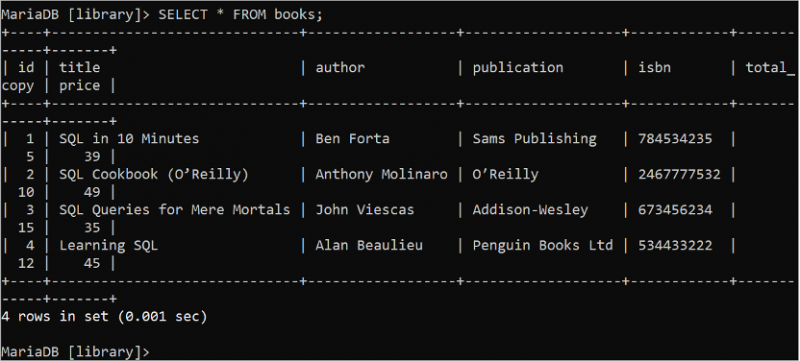
SELECT ステートメントは、「データベース」テーブルからデータを読み取るために使用されます。 「*」記号は、SELECT ステートメント内のテーブルのすべてのフィールドを示すために使用されます。次の SQL コマンドを実行して、books テーブルのすべてのレコードを読み取ります。
選択する * から 本。出力には、4 つのレコードを含む Books テーブルのすべてのレコードが表示されます。
次の SQL コマンドを実行して、「members」テーブルの 3 つのフィールドのすべてのレコードを読み取ります。
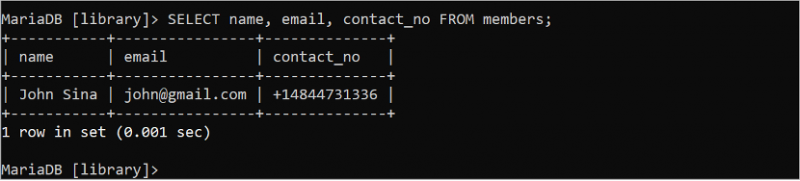
選択する 名前 、 Eメール 、 連絡先番号 から メンバー。出力には、「members」テーブルの 3 つのフィールドのすべてのレコードが表示されます。
テーブルからデータをフィルタリングした後にテーブルを読み取る
WHERE 句は、1 つ以上の条件に基づいてテーブルからデータを読み取るために使用されます。次の SELECT ステートメントを実行して、著者名が「John Viescas」である「books」テーブルのすべてのフィールドのすべてのレコードを読み取ります。
選択する * から 本 どこ 著者 = 「ジョン・ヴィエスカス」 ;「books」テーブルには、出力に示されている WHERE 句の条件に一致する 1 つのレコードが含まれています。

ブール論理に基づいてデータをフィルタリングした後、テーブルを読み取ります
ブール AND ロジックは、すべての条件が true を返す場合に true を返す WHERE 句で複数の条件を定義するために使用されます。次の SELECT ステートメントを実行して、論理 AND を使用して、total_copy フィールドの値が 10 を超え、price フィールドの値が 45 未満である「books」テーブルのすべてのフィールドのすべてのレコードを読み取ります。
選択する * から 本 どこ 合計_コピー > 10 と 価格 < 4.5 ;Books テーブルには、出力に示されている WHERE 句の条件に一致する 1 つのレコードが含まれています。

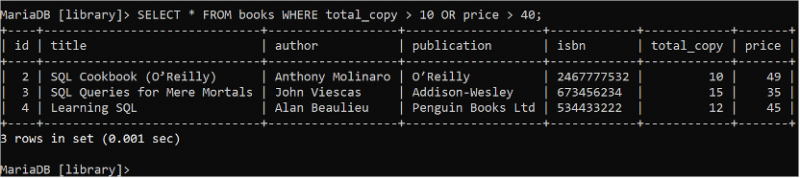
ブール OR ロジックは、いずれかの条件が true を返す場合に true を返す WHERE 句で複数の条件を定義するために使用されます。次の SELECT ステートメントを実行して、total_copy フィールドの値が 10 を超えるか、price フィールドの値が 40 を超える「books」テーブルのすべてのフィールドのすべてのレコードを読み取ります。
選択する * から 本 どこ 合計_コピー > 10 また 価格 > 40 ;Books テーブルには、出力に表示される WHERE 句の条件に一致する 3 つのレコードが含まれています。
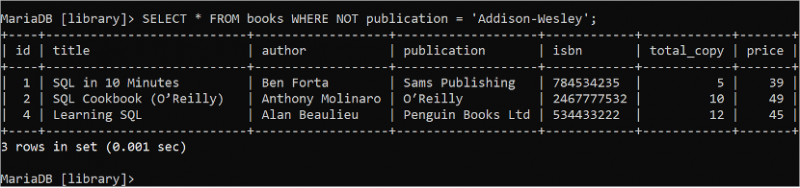
ブール NOT ロジックは、条件が true の場合に false を返し、条件が false の場合に true を返すために使用されます。次の SELECT ステートメントを実行して、著者フィールドの値が「Addison-Wesley」ではない「books」テーブルのすべてのフィールドのすべてのレコードを読み取ります。
選択する * から 本 どこ いいえ 著者 = 「アディソン・ウェスリー」 ;「books」テーブルには、出力に表示される WHERE 句の条件に一致する 3 つのレコードが含まれています。
データの範囲に基づいて行をフィルタリングした後、テーブルを読み取ります
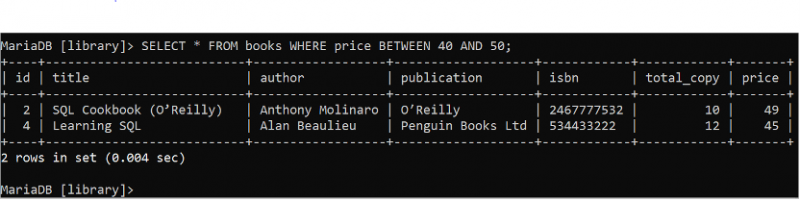
BETWEEN 句は、データベース テーブルからデータ範囲を読み取るために使用されます。次の SELECT ステートメントを実行して、「books」テーブルのすべてのフィールドの、価格フィールドの値が 40 ~ 50 であるすべてのレコードを読み取ります。
選択する * から 本 どこ 価格 間 40 と 50 ;Books テーブルには、出力に表示される WHERE 句の条件に一致する 2 つのレコードが含まれています。価格値 39 と 35 の帳簿は範囲外であるため、結果セットから除外されます。
表を並べ替えた後に表を読む
ORDER BY 句は、SELECT ステートメントの結果セットを昇順または降順に並べ替えるために使用されます。 ORDER BY 句が ASC または DESC なしで使用された場合、結果セットはデフォルトで昇順にソートされます。次の SELECT ステートメントは、タイトル フィールドに基づいて、books テーブルから並べ替えられたレコードを読み取ります。
選択する * から 本 注文 に タイトル;「books」テーブルのタイトルフィールドのデータは、出力内で昇順にソートされます。 「書籍」テーブルのタイトル フィールドを昇順に並べ替えると、「Learning SQL」書籍がアルファベット順で最初に表示されます。
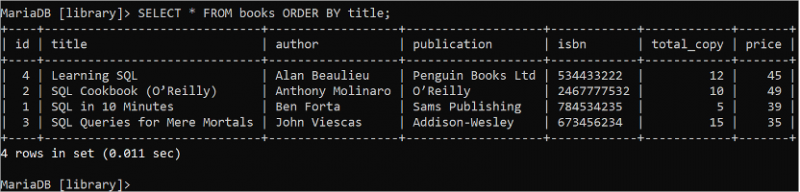
列の代替名を設定してテーブルを読み取る
列の代替名は、結果セットを読みやすくするためにクエリで使用されます。代替名は「AS」キーワードを使用して設定されます。次の SQL ステートメントは、代替名を設定することによって、タイトル フィールドと作成者フィールドの値を返します。
選択する タイトル として 「書籍名」 、 著者 として 「著者名」から 本。
出力では、タイトル フィールドは「書籍名」という代替名で表示され、著者フィールドは「著者名」という代替名で表示されます。
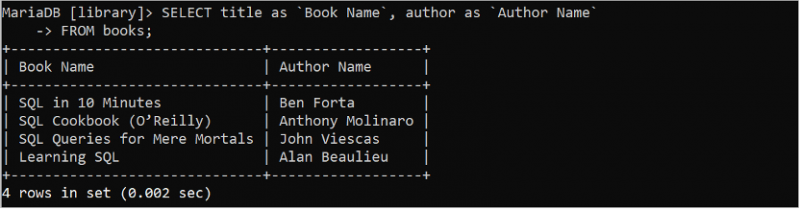
テーブル内の行の合計数を数える
COUNT() は、特定のフィールドまたはすべてのフィールドに基づいて行の合計数をカウントするために使用される SQL の集計関数です。 「*」記号はすべてのフィールドを示すために使用され、COUNT(*) はテーブルのすべてのレコードをカウントするために使用されます。
次のクエリは、books テーブルの合計レコードをカウントします。
選択する カウント ( * ) として 「総書籍数」 から 本。「books」テーブルの 4 つのレコードが出力に表示されます。

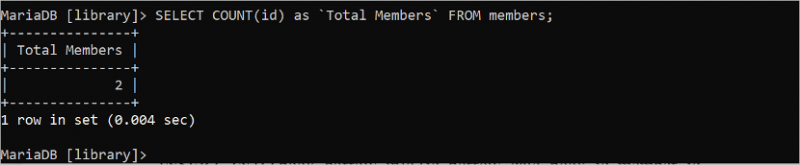
次のクエリは、「id」フィールドに基づいて「members」テーブルの合計行をカウントします。
選択する カウント ( ID ) として 「総会員数」 から メンバー。「メンバー」テーブルには、出力に出力される 2 つの ID 値があります。
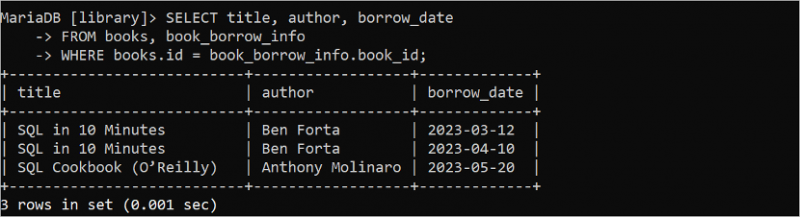
複数のテーブルからデータを読み取る
前の SELECT ステートメントは、単一のテーブルからデータを取得しました。ただし、SELECT ステートメントを使用すると、2 つ以上のテーブルからデータを取得できます。次の SELECT クエリは、「books」テーブルからタイトルと著者フィールドの値を読み取り、「book_borrow_info」テーブルからborrow_date を読み取ります。
選択する タイトル 、 著者 、 借用日から 本 、 book_borrow_info
どこ 本 。 ID = book_borrow_info 。 本のID;
次の出力は、「SQL in 10 Minutes」という書籍が 2 回借りられ、「SQL Cookbook (O'Reilly)」という書籍が 1 回借りられたことを示しています。
INNER JOIN、OUTER JOIN などのさまざまなタイプの JOIN を使用して、複数のテーブルからデータを取得できますが、このチュートリアルでは説明しません。
特定のフィールドをグループ化して表を読む
GROUP BY 句は、1 つ以上のフィールドに基づいて行をグループ化し、テーブルからレコードを読み取るために使用されます。このタイプのクエリは要約クエリと呼ばれます。 GROUP BY 句の使用を確認するには、テーブルに複数の行を挿入する必要があります。次の INSERT ステートメントを実行して、「members」テーブルに 1 つのレコードを挿入し、「book_borrow_info」テーブルに 2 つのレコードを挿入します。
入れる の中へ メンバー設定 名前 = 「彼女はサン」 、 住所 = 「11/A、ジガトラ、ダッカ」 、 連絡先番号 = 「+8801734563423」 、 Eメール = 「彼女@gmail.com」 ;
入れる の中へ book_borrow_info ( ID 、 借用日 、 book_id 、 メンバーID 、 戻り日 、 スターテス )
価値観 ( 2 、 「2023-04-10」 、 1 、 1 、 「2023-04-15」 、 '戻ってきた' ) ;
入れる の中へ book_borrow_info ( ID 、 借用日 、 book_id 、 メンバーID 、 戻り日 、 スターテス )
価値観 ( 3 、 「2023-05-20」 、 2 、 1 、 「2023-05-30」 、 '借りた' ) ;
前のクエリを実行してデータを挿入した後、GROUP BY 句を使用して各メンバーに基づいて借りた書籍の合計数とメンバー名をカウントする次の SELECT ステートメントを実行します。ここで、COUNT() 関数は、GROUP BY 句を使用してレコードを再グループ化するために使用されるフィールドに対して機能します。ここでのグループ化には、「members」テーブルの book_id フィールドが使用されます。
選択する カウント ( book_id ) として 「借りた本の合計」 、 名前 として 「メンバー名」 から 本 、 メンバー 、 book_borrow_info どこ 本 。 ID = book_borrow_info 。 book_id と メンバー 。 ID = book_borrow_info 。 メンバーID グループ に book_borrow_info 。 メンバーID;書籍、「members」テーブル、および「book_borrow_info」テーブルのデータによると、「John Sina」は 2 冊の本を借り、「Ella Hasan」は 1 冊の本を借りました。

重複する値を省略してテーブルを読み取る
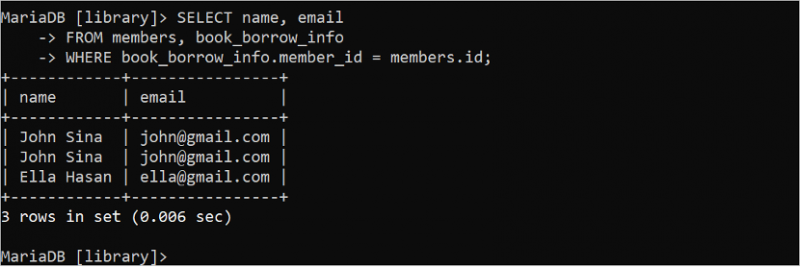
場合によっては、不要なテーブル データに基づいて SELECT ステートメントの結果セットに重複データが生成されることがあります。たとえば、次の SELECT ステートメントは、「book_borrow_info」テーブルのデータの重複レコードを返します。
選択する 名前 、 Eメールから メンバー 、 book_borrow_info
どこ book_borrow_info 。 メンバーID = メンバー 。 ID;
「John Sina」メンバーが 2 冊の本を借りたため、出力では同じレコードが 2 回表示されます。この問題は、DISTINCT キーワードを使用して解決できます。クエリ結果から重複レコードを削除します。
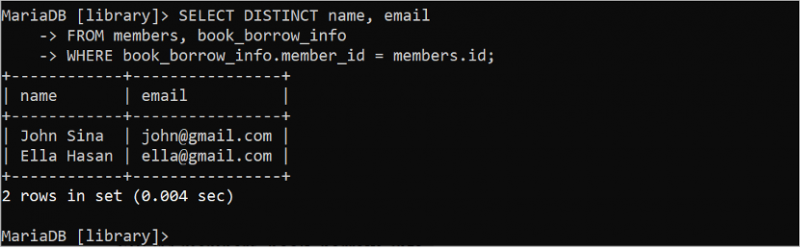
次の SELECT ステートメントは、クエリで DISTINCT キーワードを使用して重複する値を省略した後、「members」テーブルと「book_borrow_info」テーブルから結果セットの一意のレコードを生成します。
選択する 明確 名前 、 Eメールから メンバー 、 book_borrow_info
どこ book_borrow_info 。 メンバーID = メンバー 。 ID;
出力は、重複した値が結果セットから削除されたことを示しています。
行数を制限してテーブルを読み取る
場合によっては、行番号を制限して、データベース テーブルから結果セットの先頭、結果セットの末尾、または結果セットの中間から特定の数のレコードを読み取る必要があります。さまざまな方法で実現できます。行を制限する前に、次の SQL ステートメントを実行して、books テーブルに存在するレコードの数を確認します。
選択する * から 本。出力には、books テーブルに 4 つのレコードがあることが示されています。

次の SELECT ステートメントは、値 2 の LIMIT 句を使用して、「books」テーブルから最初の 2 つのレコードを読み取ります。
選択する * から 本 リミット 2 ;「books」テーブルの最初の 2 つのレコードが取得され、出力に表示されます。

FETCH 句は LIMIT 句の代替であり、その使用方法を次の SELECT ステートメントに示します。 「books」テーブルの最初の 3 レコードは、SELECT ステートメントの FETCH FIRST 3 ROWS ONLY 句を使用して取得されます。
選択する * から 本の取り出し 初め 3 行 それだけ ;出力には、「books」テーブルの最初の 3 レコードが表示されます。

3 つのレコードから 2 つのレコード rd 次の SELECT ステートメントを実行すると、books テーブルの行が取得されます。ここでは LIMIT 句が 2, 2 の値とともに使用されています。最初の 2 は 0 からカウントを開始するテーブルの行の開始位置を定義し、2 番目の 2 は開始位置からカウントを開始する行の数を定義します。
選択する * から 本 リミット 2 、 2 ;前のクエリを実行すると、次の出力が表示されます。

テーブルの末尾からのレコードは、自動インクリメントされる主キー値に基づいてテーブルを降順に並べ替え、LIMIT 句を使用することで読み取ることができます。次の SELECT ステートメントを実行して、「books」テーブルから最後の 2 レコードを読み取ります。ここでは、結果セットは「id」フィールドに基づいて降順にソートされます。
選択する * から 本 注文 に ID 説明 リミット 2 ;Books テーブルの最後の 2 つのレコードが次の出力に示されています。

部分一致に基づいてテーブルを読み取る
LIKE 句は、部分一致によってテーブルからレコードを取得するために「%」記号とともに使用されます。次の SELECT ステートメントは、LIKE 句を使用して、著者フィールドの値の先頭に「John」が含まれるレコードを「books」テーブルから検索します。ここでは、検索文字列の末尾に「%」記号を使用しています。
選択する * から 本 どこ 著者 好き 「ジョン%」 ;「books」テーブルには、著者フィールドの値の先頭に「John」文字列を含むレコードが 1 つだけ存在します。

次の SELECT ステートメントは、LIKE 句を使用して、出版物フィールドの値の末尾に「Ltd」が含まれるレコードを「books」テーブルから検索します。ここでは、検索文字列の先頭に「%」記号が使用されています。
選択する * から 本 どこ 出版物 好き 「%株式会社」 ;「books」テーブルには、出版物フィールドの末尾に「Ltd」文字列を含むレコードが 1 つだけ存在します。

次の SELECT ステートメントは、LIKE 句を使用して、タイトル フィールドの値の任意の場所に「クエリ」が含まれる「books」テーブルからレコードを検索します。ここでは、検索文字列の両側に「%」記号が使用されています。
選択する * から 本 どこ タイトル 好き '%クエリ%' ;「books」テーブルには、タイトルフィールドに「Queries」文字列を含むレコードが 1 つだけ存在します。

テーブルの特定のフィールドの合計を数える
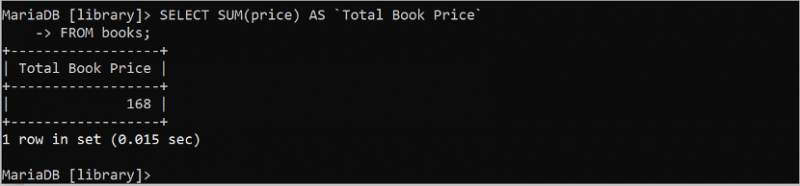
SUM() は、テーブルの数値フィールドの値の合計を計算する、SQL のもう 1 つの便利な集計関数です。この関数は引数を 1 つ取りますが、その引数は数値である必要があります。次の SQL ステートメントは、整数値を含む「books」テーブルの価格フィールドのすべての値の合計を計算します。
選択する 和 ( 価格 ) として 「書籍の合計価格」から 本。
出力には、「books」テーブルの価格フィールドのすべての値の合計値が表示されます。価格フィールドの 4 つの値は 39、49、35、および 45 です。これらの値の合計は 168 です。
特定のフィールドの最大値と最小値を見つける
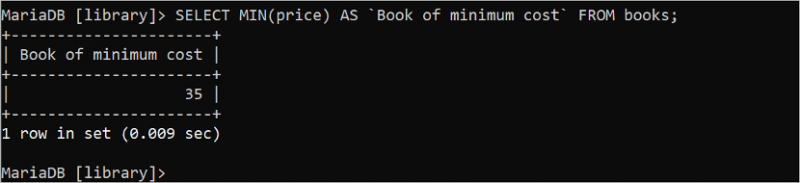
MIN() および MAX() 集約関数は、テーブルの特定のフィールドの最小値と最大値を見つけるために使用されます。どちらの関数も引数を 1 つ取り、その引数は数値である必要があります。次の SQL ステートメントは、整数である「books」テーブルから最低価格値を見つけます。
選択する 最小 ( 価格 ) として 「最小コストの本」 から 本。35 は、出力に印刷される価格フィールドの最小値です。
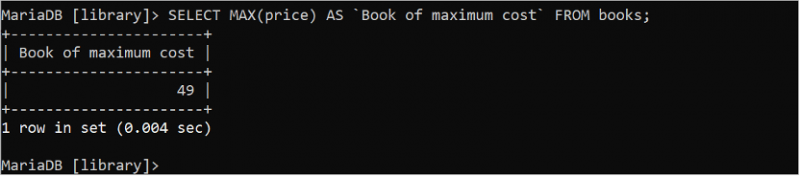
次の SQL ステートメントは、「books」テーブルから最高価格値を見つけます。
選択する マックス ( 価格 ) として 『最大コストの書』 から 本。49 は、出力に印刷される価格フィールドの最大値です。
データまたはフィールドの特定の部分を読み取る
SUBSTR() 関数は、文字列データの特定の部分またはテーブルの特定のフィールドの値を取得するために SQL ステートメントで使用されます。この関数には 3 つの引数が含まれます。最初の引数には、文字列値、または文字列であるテーブルのフィールド値が含まれます。 2 番目の引数には、最初の引数から取得されたサブ文字列の開始位置が含まれ、この値のカウントは 1 から始まります。 3 番目の引数には、開始位置からカウントを開始するサブ文字列の長さが含まれます。
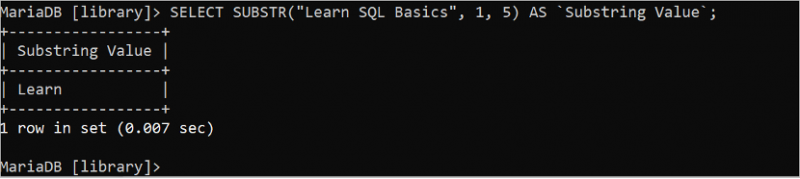
次の SELECT ステートメントは、開始位置が 1、長さが 5 である「Learn SQL Basics」文字列から最初の 5 文字を切り取って出力します。
選択する サブストラ ( 「SQLの基礎を学ぶ」 、 1 、 5 ) として `部分文字列値` ;「Learn SQL Basics」文字列の最初の 5 文字は「Learn」で、出力に表示されます。
次の SELECT ステートメントは、開始位置が 7、長さが 3 の「Learn SQL Basics」文字列から SQL を切り取って出力します。
選択する サブストラ ( 「SQLの基礎を学ぶ」 、 7 、 3 ) として `部分文字列値` ;前のクエリを実行すると、次の出力が表示されます。

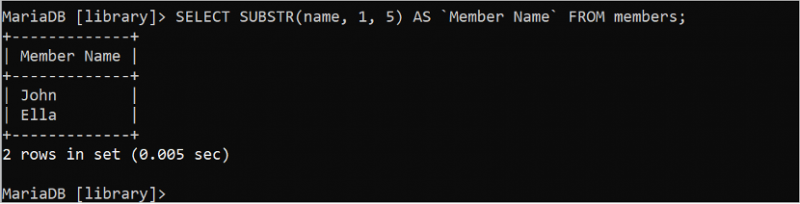
次の SELECT ステートメントは、「members」テーブルの名前フィールドから最初の 5 文字を切り取って出力します。
選択する サブストラ ( 名前 、 1 、 5 ) として 「メンバー名」 から メンバー。出力には、「members」テーブルの名前フィールドの各値の最初の 5 文字が表示されます。
連結後のテーブルデータの読み取り
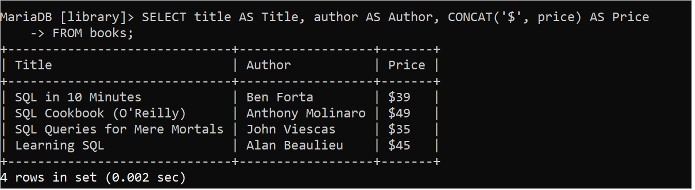
CONCAT() 関数は、テーブルの 1 つ以上のフィールドを結合するか、文字列データまたはテーブルの特定のフィールド値を追加することによって出力を生成するために使用されます。次の SQL ステートメントは、「books」テーブルのタイトル、著者、および価格フィールドの値を読み取り、CONCAT() 関数を使用して価格フィールドの各値に「$」文字列値を追加します。
選択する タイトル として タイトル 、 著者 として 著者 、 コンキャット ( 「$」 、 価格 ) として 価格から 本。
価格フィールドの値は、「$」文字列と連結して出力に表示されます。
次の SQL ステートメントを実行し、CONCAT() 関数を使用して「books」テーブルのタイトルおよび著者フィールドの値を「by」文字列値と結合します。
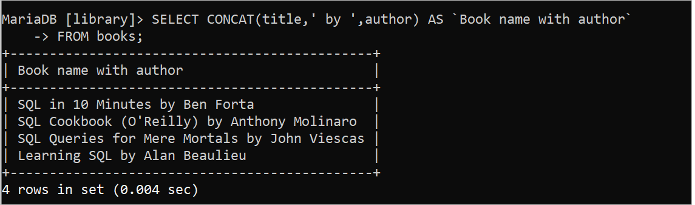
選択する コンキャット ( タイトル 、 ' に ' 、 著者 ) として `著者名付きの書籍名`から 本。
前の SELECT クエリを実行すると、次の出力が表示されます。
数学的計算後にテーブルデータを読み取る
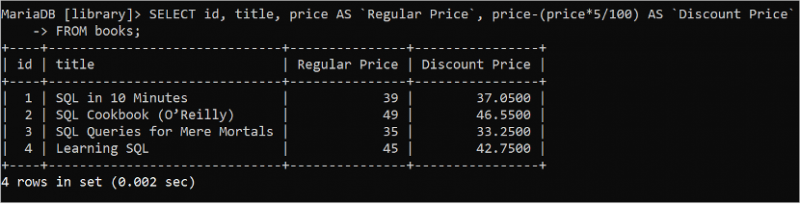
SELECT ステートメントを使用してテーブルの値を取得するときに、あらゆる数学的計算を実行できます。次の SQL ステートメントを実行して、ID、タイトル、価格、および 5% 割引を計算した後の割引価格の値を読み取ります。
選択する ID 、 タイトル 、 価格 として 「通常価格」 、 価格 - ( 価格 * 5 / 100 ) として 「割引価格」から 本。
次の出力は、各書籍の通常価格と割引価格を示しています。
テーブルのビューを作成する
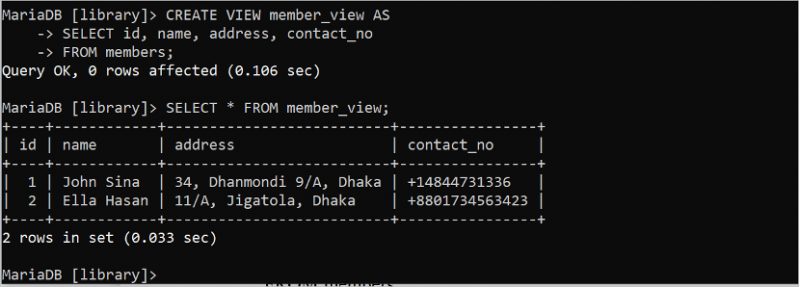
VIEW はクエリを簡素化し、データベースに追加のセキュリティを提供するために使用されます。これは、1 つまたは複数のテーブルから生成される仮想テーブルのように機能します。 「members」テーブルに基づいて単純な VIEW を作成および実行する方法を次の例に示します。 VIEW は SELECT ステートメントを使用して実行されます。次の SQL ステートメントは、id、name、address、および contact_no フィールドを含む「members」テーブルの VIEW を作成します。 SELECT ステートメントは member_view を実行します。
作成 意見 メンバービュー として選択する ID 、 名前 、 住所 、 連絡先番号
から メンバー。
選択する * から メンバービュー;
ビューを作成して実行すると、次の出力が表示されます。
特定の条件に基づいてテーブルを更新する
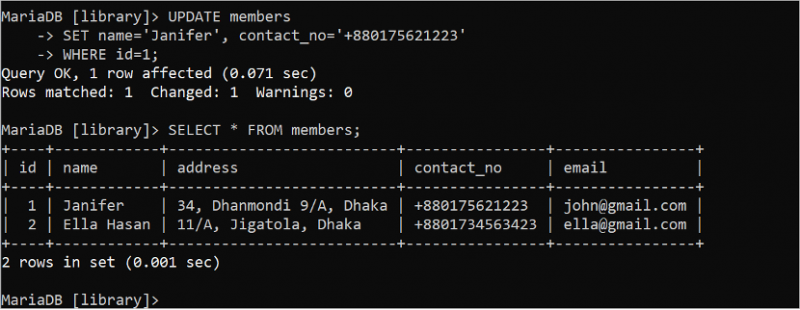
UPDATE ステートメントは、テーブルの内容を更新するために使用されます。 WHERE 句を指定せずに UPDATE クエリを実行すると、UPDATE クエリで使用されるすべてのフィールドが更新されます。したがって、適切な WHERE 句を指定した UPDATE ステートメントを使用する必要があります。次の UPDATE ステートメントを実行して、id フィールドの値が 1 である name フィールドと contact_no フィールドを更新します。次に、SELECT ステートメントを実行して、データが正しく更新されたかどうかを確認します。
アップデート メンバー設定 名前 = 「ジャニファー」 、 連絡先番号 = 「+880175621223」
どこ ID = 1 ;
選択する * から メンバー。
次の出力は、UPDATE ステートメントが正常に実行されたことを示しています。 UPDATE クエリを使用して、ID 値 1 を含むレコードの name フィールドの値が「Janifer」に変更され、contact_no フィールドが「+880175621223」に変更されます。
特定の条件に基づいてテーブル データを削除する
DELETE ステートメントは、テーブルの特定のコンテンツまたはすべてのコンテンツを削除するために使用されます。 WHERE 句を指定せずに DELETE クエリを実行すると、すべてのフィールドが削除されます。したがって、適切な WHERE 句を指定して UPDATE ステートメントを使用する必要があります。次の DELETE ステートメントを実行して、books テーブルから ID 値が 4 のデータをすべて削除します。次に、SELECT ステートメントを実行して、データが正しく削除されたかどうかを確認します。
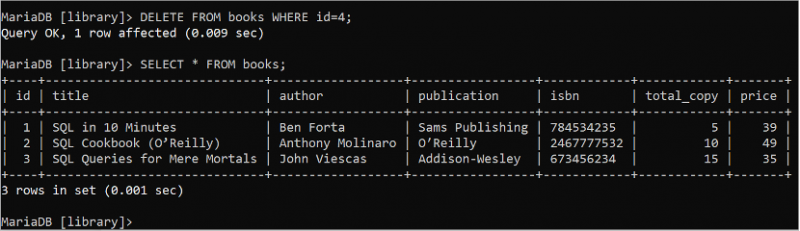
消去 から 本 どこ ID = 4 ;選択する * から 本。
次の出力は、DELETE ステートメントが正常に実行されたことを示しています。 4 番目 Books テーブルのレコードは、DELETE クエリを使用して削除されます。
テーブルからすべてのレコードを削除
次の DELETE ステートメントを実行して、「books」テーブルから WHERE 句が省略されているすべてのレコードを削除します。次に、SELECT クエリを実行してテーブルの内容を確認します。
消去 から 本を借りる情報;選択する * から 本を借りる情報;
次の出力は、DELETE クエリの実行後に「books」テーブルが空であることを示しています。

いずれかのテーブルに自動インクリメント属性が含まれており、すべてのレコードがテーブルから削除された場合、テーブルを空にした後に新しいレコードが挿入されると、自動インクリメント フィールドは最後の増分からカウントを開始します。この問題は、TRUNCATE ステートメントを使用して解決できます。これはテーブルからすべてのレコードを削除するためにも使用されますが、自動インクリメント フィールドはテーブルからすべてのレコードを削除した後に 1 からカウントを開始します。 TRUNCATE ステートメントの SQL を以下に示します。
切り詰める 本を借りる情報;テーブルをドロップする
テーブルが存在するかどうかをチェックすることによって、またはチェックせずに 1 つ以上のテーブルを削除できます。次の DROP ステートメントは「book_borrow_info」テーブルを削除し、「SHOW tables」ステートメントはテーブルがサーバー上に存在するかどうかを確認します。
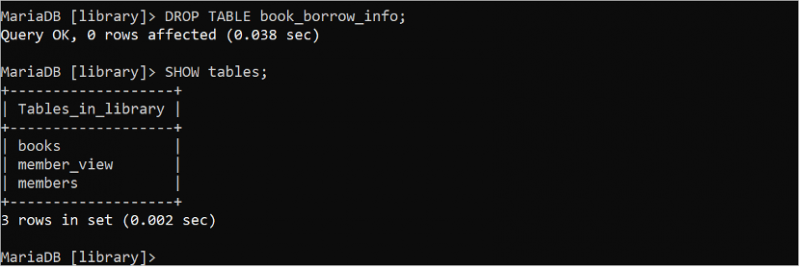
落とす テーブル 本を借りる情報;見せる テーブル ;
出力には、「book_borrow_info」テーブルが削除されたことが示されています。
テーブルがサーバー上に存在するかどうかを確認した後、テーブルを削除できます。これらのテーブルがサーバーに存在する場合は、次の DROP ステートメントを実行して、books テーブルと members テーブルを削除します。次に、「SHOW tables」ステートメントは、テーブルがサーバー上に存在するかどうかを確認します。
落とす テーブル もしも 存在します 本 、 メンバー。見せる テーブル ;
次の出力は、テーブルがサーバーから削除されたことを示しています。

データベースを削除する
次の SQL ステートメントを実行して、サーバーから「ライブラリ」データベースを削除します。
落とす データベース 図書館;出力には、データベースが削除されたことが示されています。

結論
このチュートリアルでは、データベースと 3 つのテーブルを作成することによって、MariaDB サーバーのデータベースの作成、アクセス、変更、削除によく使用される SQL クエリの例を示します。新しいデータベース ユーザーが SQL の基本を正しく学ぶのに役立つように、さまざまな SQL ステートメントの使用法が非常に簡単な例で説明されています。複雑なクエリの使用方法はここでは省略します。新しいデータベース ユーザーは、このチュートリアルを正しく読んだ後、どのデータベースでも作業を開始できるようになります。